


Graph retrieval-augmented generation (RAG) is a powerful way to knock down some of the limitations of traditional vector search, by integrating multiple data sources to produce more accurate results. It does this by enhancing your ability to understand and organize documents by leveraging a knowledge graph to reveal hidden relationships and structures. This new perspective aids in document visualization and enhances RAG performance for large language model (LLM) queries.
Unstructured excels at parsing and interpreting different types of documents, extracting both content and metadata. This includes structural relationships, which are essential for constructing a knowledge graph. By preserving these relationships, Unstructured lays the groundwork for building a graph that captures document hierarchies and connections often missed by purely semantic embeddings.
Astra DB complements this by providing a scalable, hybrid graph and vector store. Its intuitive interface and robust architecture make it easy to store and manage document embeddings and their associated graph structures, ensuring scalability as your data grows. Together, these tools enable you to create a rich, interconnected perspective of your documents.
Graphs are especially valuable for capturing information that gets lost in semantic embeddings. For example, while embeddings capture meaning, they often miss the hierarchical or relational structure inherent in documents. With graph RAG, you gain a new way of organizing and visualizing your data, transforming document retrieval and enhancing contextual understanding for LLMs. This means your application can deliver smarter, more context-aware results by combining semantic insights with the relational power of graphs.
In this post, we’ll explore how to implement graph RAG using the Unstructured Platform and Astra DB.
The problem
Traditional vector search methods, while effective for finding semantically similar documents, can overlook hierarchical or relational connections within your data. For instance, consider a technical document that defines terms in a glossary and uses those terms in various sections. A semantic search might retrieve a section using the term but miss the glossary definition entirely. Similarly, in a web context, a semantic search might retrieve a page that discusses a topic but fail to find linked articles that provide essential background information.
Graphs help solve these problems by capturing relationships such as parent/child hierarchies, hyperlinks between documents, or connections between glossary terms and their definitions. These additional layers of context enable a new way of understanding your documents, providing richer insights and more meaningful connections.
The solution
This post focuses on constructing structural graphs, a specific type of graph where relationships between elements are based on the structural hierarchy of the document. Structural graphs are particularly useful for capturing parent-child relationships, such as sections and subsections within a document. Not all graphs can be constructed using the Unstructured Platform today, but structural graphs are an excellent starting point for leveraging the platform's capabilities.
The Unstructured Platform is an end-to-end solution that simplifies the process by loading, parsing, chunking, embedding, and storing documents, integrated with Astra DB. By combining these steps into a single platform, it eliminates the need for separate workflows and ensures seamless integration of structural metadata and vector embeddings.
The solution involves:
- Loading and parsing documents - Use the Unstructured Platform to parse documents into structured formats that retain semantic and structural metadata. Parsing is challenging because documents come in diverse formats with varying structures, but the platform simplifies this with robust extraction and embedding tools.
- Building the knowledge graph - Enhance the document embeddings with graph edges to capture document relationships. Defining meaningful edges requires understanding document context, which is addressed by leveraging metadata extracted during parsing.
- Querying with graph traversal: Retrieve relevant subgraphs for LLM queries to provide richer context. This step is tricky because it combines two different data modalities: vector similarity and graph relationships. We solve this using a hybrid graph/vector traversal algorithm that balances both approaches.
Step 1: Loading and parsing documents with Unstructured
The Unstructured Platform supports diverse document formats, such as PDFs, HTML, and plain text. It parses documents into structured elements while embedding the content and storing it directly in Astra DB.
The following video shows a walk through of the Unstructured Platform:
Read on for a simplified workflow.
Create source and destination data connectors
Begin by connecting Unstructured to your source data. The Unstructured Platform enables you to connect to many different data sources (AWS S3 or Google GCS, for example). We’ll use Astra DB as the data destination.
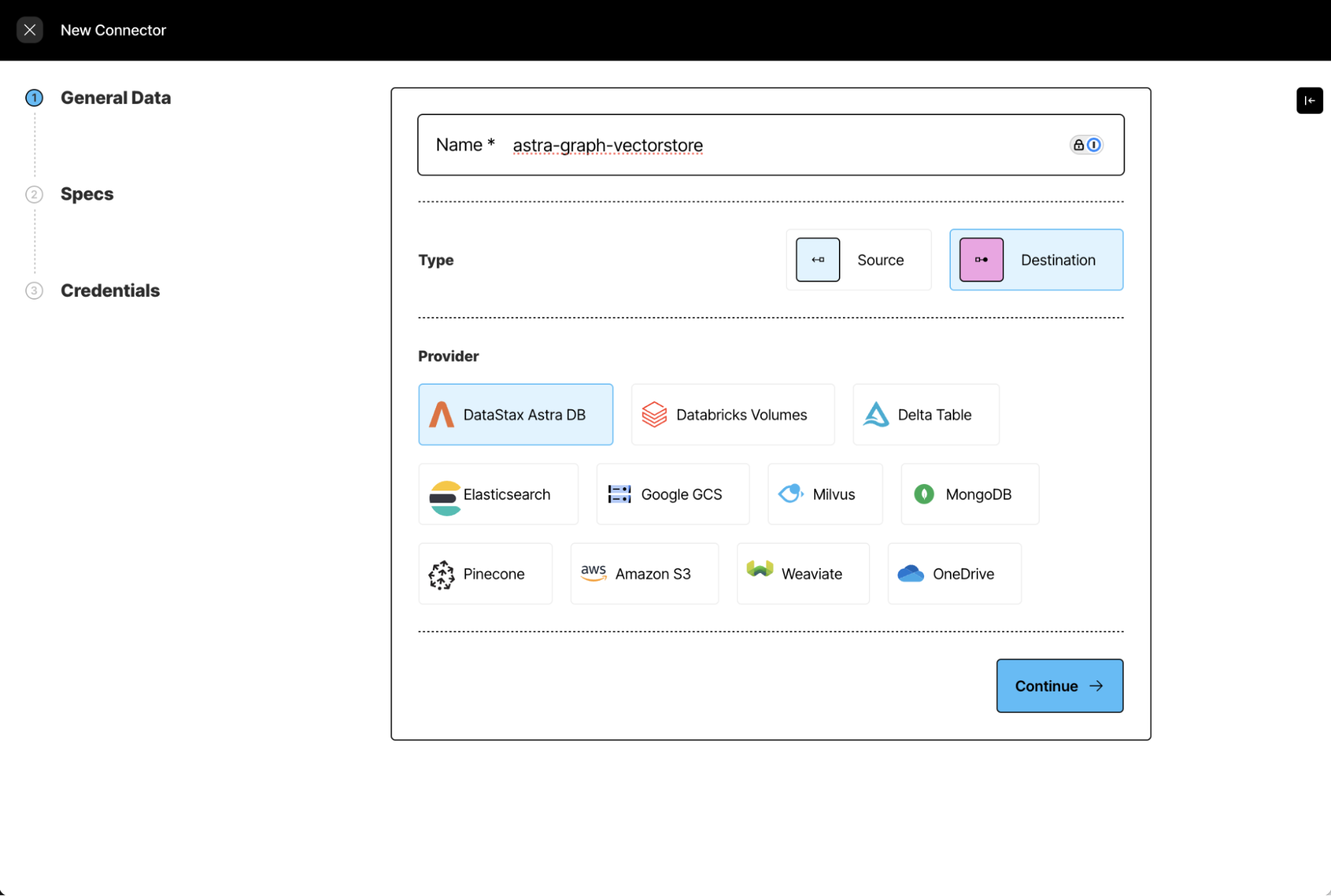
Create a document ingestion pipeline
Documents are transformed with Workflows, which you can set up here. The Unstructured Platform gives you different ways to transform different types of documents, and will help you choose the right settings based on your documents. In this case we’ll use the “Basic” default optimization, since we are working with simple, text-only documents. Check out the partition documentation for more information on how to select a strategy.
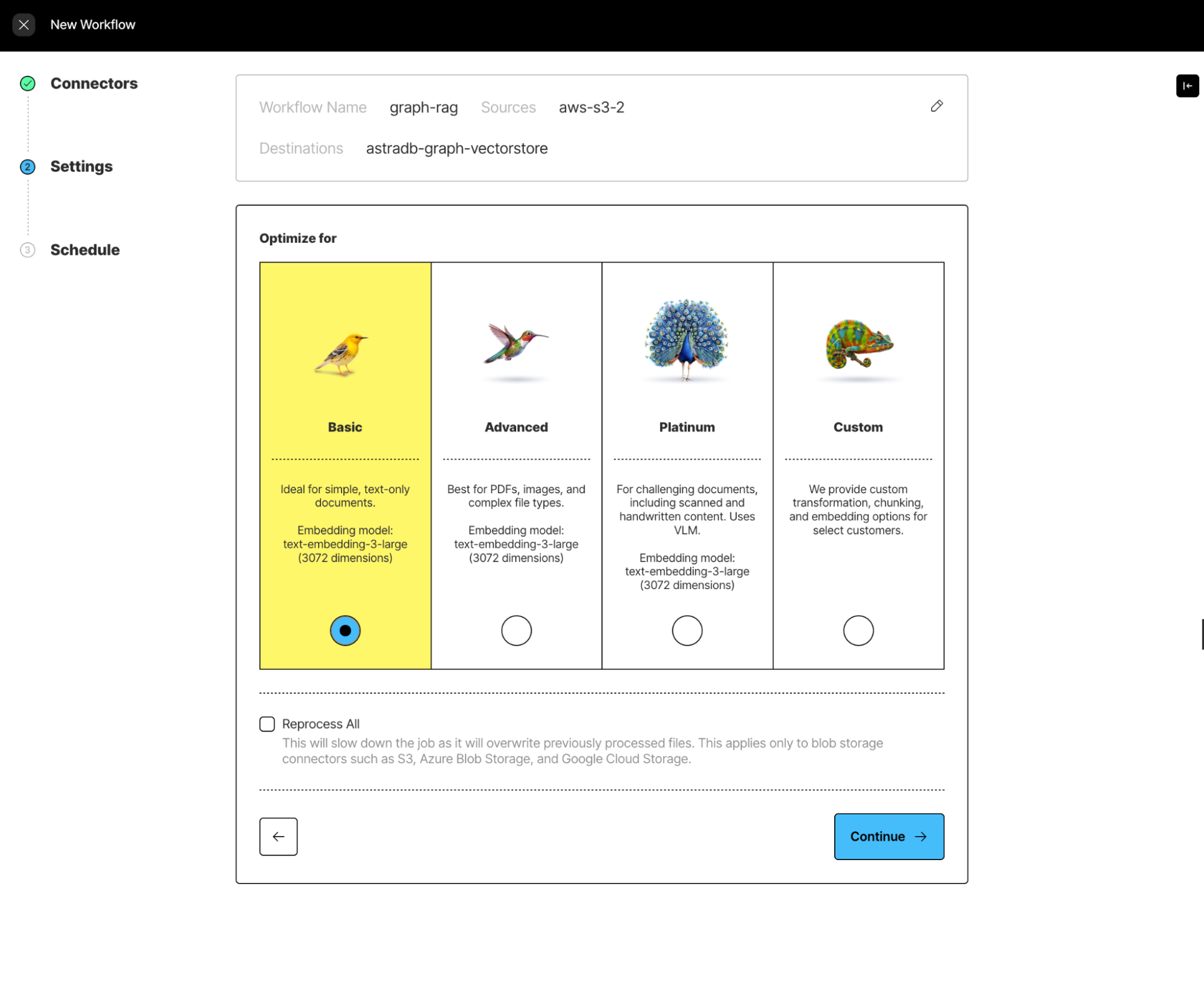
Execute the pipeline to load, process, and persist documents in AstraDB
Once you’ve created a workflow, click “Run” and Unstructured will load, extract, chunk, and persist your documents to Astra DB. This workflow will identify your document’s structure and persist that structure to Astra DB as metadata.
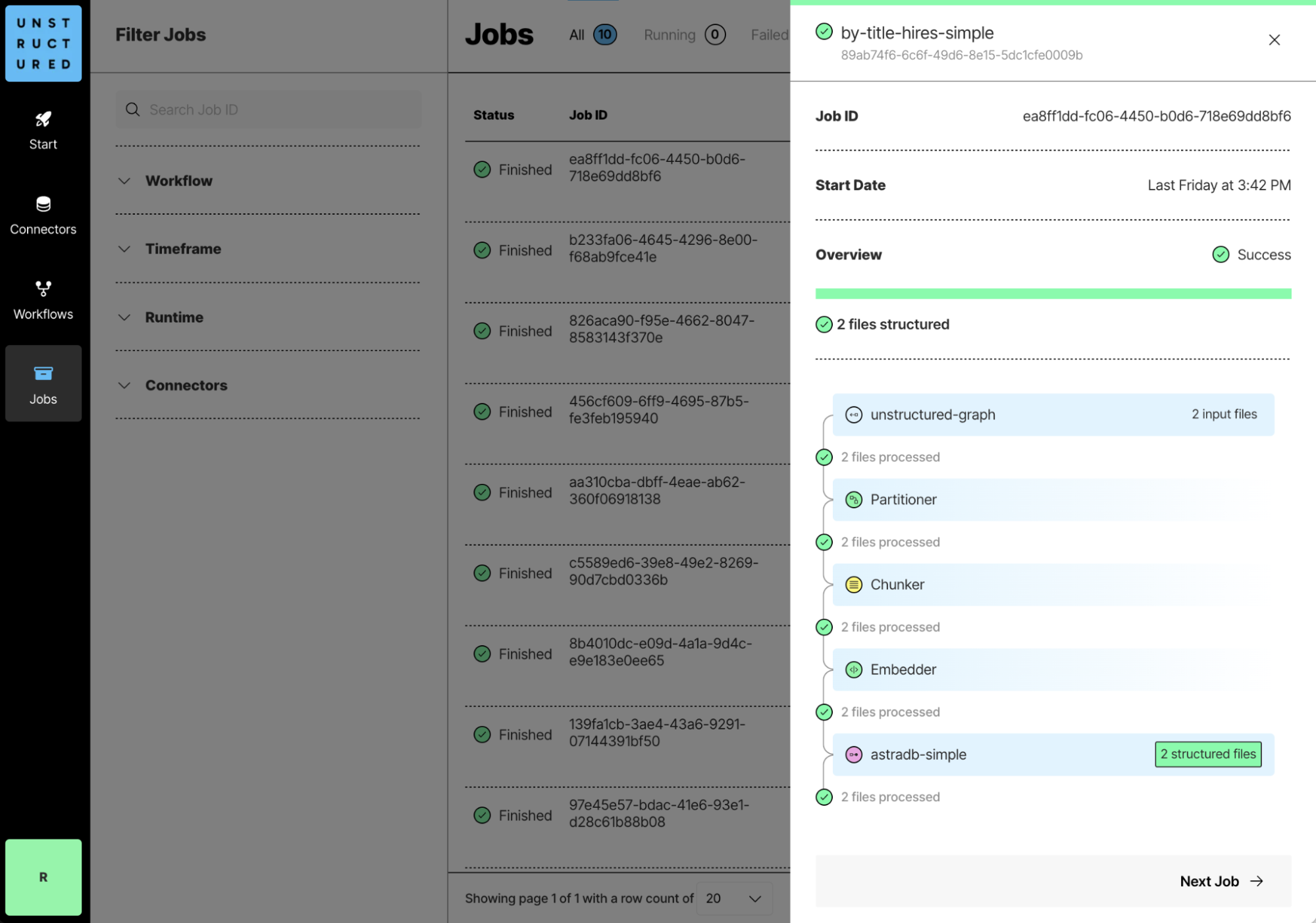
Step 2: Enhancing with graph edges
In the previous step, we used the Unstructured Platform to populate an Astra DB Vector store with document chunks and associated metadata. Now, we’ll transform the document metadata into a graph of relationships between documents.
This transformation consists of describing “links” between documents. Links connect documents that share an attribute: in this example we’ll connect chunks of a document with the same parent element to each other and to the parent element itself.
The relationships between chunks were identified by Unstructured, so all that’s needed is to transform the parent_id and element_id metadata fields into corresponding graph links. This step involves incrementally updating rows in the database to add graph edges, ensuring scalability even with large datasets:
# Rather than loading the entire dataset, query the database in
# smaller batches to find documents without graph edges.
# This ensures the process is incremental and scalable.
while True:
filter = {"graph_edges": {"$exists": False}}
to_extend = vectorstore.metadata_search(filter=filter, n=100)
if len(to_extend) == 0:
break
for doc in to_extend:
element_id = doc.metadata.get("element_id")
if element_id:
add_links(doc, [
# Allow graph traversal from this element ID
Link.incoming(kind="sections", tag=element_id)
])
parent_id = doc.metadata.get("parent_id")
if parent_id:
add_links(doc, [
# Allow graph traversal to and from this parent ID
Link.bidir(kind="sections", tag=parent_id)
])
doc.metadata.update(graph_edges=True)
# Updated documents with graph edges are added back
# into the database incrementally, ensuring the process
# is efficient and avoids overloading memory.
vectorstore.add_documents(to_extend)A key advantage of using a graph structure is the ability to visualize the document relationships. Parent-child relationships naturally form clusters, offering insights into document structure. The following diagram shows clusters representing sections with the document.

This type of visualization helps you understand how your data is organized and provides a new perspective on your documents.
Step 3: Querying with graph traversal
Graph traversal retrieves related documents by considering graph connections, adding more context to LLM queries. This step utilizes a hybrid graph/vector traversal algorithm, which blends the strengths of both retrieval methods to surface richer, more interconnected results.
Graph traversal enables you to retrieve relevant neighborhoods of documents. For example:
traversal_results = vectorstore.traversal_search(
query="What are the differences between Graph RAG and naive RAG?",
k=4,
depth=2,
)
visualize(traversal_results)The traversal depth determines the scope of the search. Depth 0 retrieves only the closest documents based on vector similarity, while greater depths bring in related documents via graph edges, creating clusters of semantically and contextually connected information.
Here’s a graphical representation of a query result:
Depth 0 (vector search) - Individual documents are isolated, representing purely semantic matches without context. Graphically, we can see that these documents aren't connected to each other, indicating they come from different sections of the document. The four nodes represent the four documents closest to our query in semantic space.

Depth 1 (graph traversal) - Increasing the traversal depth retrieves the "neighborhood" around each document, providing additional context for the model. In the graphical representation we can see that several documents are now part of larger clusters, formed by incorporating non-semantic relationships between documents (in this case, the document's hierarchical structure).

Depth 2 (MMR graph traversal) - MMR Traversal is a retrieval strategy that includes document rescoring. This strategy traverses the graph as before, but selects a subgraph, balancing similarity (documents close to the search vector) and diversity (documents far away from each other). In the graphical representation you can see there are exactly four documents and some are connected with edges (suggesting they were discovered through traversal). This type of traversal provides a way to incorporate both graph and vector similarity in a single query.

This visualization demonstrates how increasing the traversal depth surfaces a broader, more connected view of your document landscape.
Querying with graph traversal is particularly tricky because it requires balancing two retrieval strategies: finding semantically similar documents and navigating graph-based relationships. The hybrid graph/vector traversal algorithm efficiently integrates these strategies, ensuring relevant and comprehensive results.
Results
Graph RAG provides a new way to visualize and organize your documents, uncovering hidden relationships and structures. This perspective enables more effective understanding of your data while also enhancing traditional RAG performance. By retrieving connected clusters instead of disjoint results, Graph RAG delivers deeper insights and improved LLM responses.
Next steps
Ready to try applying graph RAG to your own datasets to unlock richer, more accurate insights for your applications? Check out the full notebook for the complete implementation details, and join our Jan. 15 livestream for more.
The problem
The solution
Step 1: Loading and parsing documents with Unstructured
Create source and destination data connectors
Create a document ingestion pipeline
Execute the pipeline to load, process, and persist documents in AstraDB
Step 2: Enhancing with graph edges
Step 3: Querying with graph traversal
Results
Next steps
More Technology
View All
How to Build Graph RAG with Unstructured and Astra DB


