

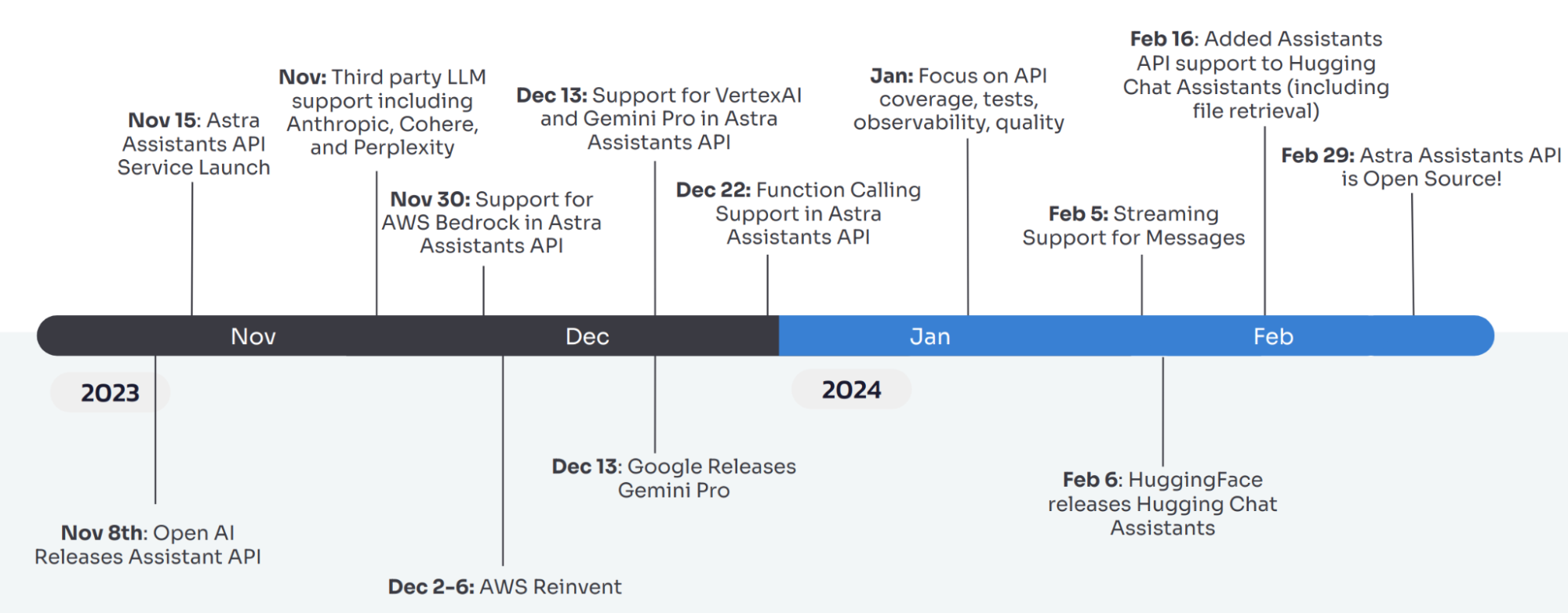
On November 8, OpenAI CEO Sam Altman took the stage to unveil the OpenAI Assistants API beta preview. This kicked off an exciting and busy time at DataStax as we set out to build and improve an API-compatible service powered by Astra DB and its vector search capabilities.
We launched the service eight days later; today, we’re excited to announce that we’re open sourcing the codebase for users who want to see exactly how it works and for those that want to host it themselves.
Here's what we've been up to since launch (we've been busy!):
Why open source?
We believe that making the server code open source will benefit users in a few ways:
- It enables folks who want to deploy on premises / self hosted and point to their own self managed cassandra / DSE databases or locally hosted LLM inference servers
- Astra Assistants API users may be interested in exactly how we implement retrieval and function calling. This is an area that we are quickly innovating in and are interested in accelerating user feedback.
Internals
The assistant-api-server repo is a Python server app that heavily depends on FastAPI, Pydantic, and the DataStax Python CQL driver. It relies on LiteLLM for third-party LLM support and we've been very happy with their responsiveness in Github as well as their ability to quickly add new models as the AI landscape evolves.
The app is mostly stateless (with the exception of a database connection cache) and all authentication tokens and LLM provider configuration are passed as http headers. The streaming-assistants Python library makes it easy for users to store these configurations as environment variables and it takes care of the rest. We serve the app in production using uvicorn (a high performance web server for python) and scale it in Kubernetes and horizontal pod autoscaler. The Docker image is available at datastax/astra-assistants.
The app consists of both generated and hand-written code. The generated code is based on OpenAI's OpenAPI spec and generated with openapi-generator-cli from openapi-generator.tech. It mostly lives in the openapi_server directory. Leveraging the OpenAPI spec was one of the first design decisions we made and it was a no brainer: OpenAI's high quality spec (they use it to generate their SDKs) ensures that all the types for all the endpoints are built correctly and enforced by Pydantic.
The hand-written code takes the method stubs from open-api-server/apis and implements them using the types from openapi-server/models inside of impl/routes. The third-party LLM support is abstracted in impl/services/inference_utils.py and the database interactions occur in impl/astra_vector.py. We collect throughput, duration, and payload size metrics and export them with a Prometheus exporter that’s exposed with a /metrics endpoint. The Prometheus exporter is configured to work using a multi-process collector to support our multi-process uvicorn production deployment.
Finally, in the tests directory we have implemented tests and CI using both an HTTP client directly (originally generated by openapi-generator.tech and tweaked manually) and custom tests that use both the OpenAI SDK and our streaming-assistants library directly.
Try it out!
The service has been running in production since November 15th, 2023 and we're constantly improving it. Try the service, check out our code, and give us feedback on GitHub. We can't wait to see what you build!






