
When you’re building a retrieval-augmented generation (RAG) app, the first thing you need to do is prepare your data. You need to:
- collect your unstructured data
- split it into chunks
- turn those chunks into vector embeddings
- store the embeddings in a vector database
There are many ways that you can create vector embeddings in Python. In this post, we’ll take a look at four ways to generate vector embeddings: locally, via API, via a framework, and with Astra DB's Vectorize.
Local vector embeddings
There are many pre-trained embedding models available on Hugging Face that you can use to create vector embeddings. Sentence Transformers (SBERT) is a library that makes it easy to use these models for vector embedding, as well as cross-encoding for reranking. It even has tools for finetuning models, if that’s something that might be of use.
You can install the library with:
pip install sentence_transformers
A popular local model for vector embedding is all-MiniLM-L6-v2. It’s trained as a good all-rounder that produces a 384-dimension vector from a chunk of text.
To use it, import sentence_transformers and create a model using the identifier from Hugging Face, in this case "all-MiniLM-L6-v2". If you want to use a model that isn't in the sentence-transformers project, like the multilingual BGE-M3, you can use the organization to identify the model too, like, "BAAI/BGE-M3". Once you've loaded the model, use the encode method to create the vector embedding. The full code looks like this:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
sentence = "A robot may not injure a human being or, through inaction, allow a human being to come to harm."
embedding = model.encode(sentence)
print(embedding)
# => [ 1.95171311e-03 1.51085425e-02 3.36140348e-03 2.48030387e-02 ... ]If you pass an array of texts to the model, they’ll all be encoded:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
sentences = [
"A robot may not injure a human being or, through inaction, allow a human being to come to harm.",
"A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.",
"A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.",
]
embeddings = model.encode(sentences)
print(embeddings)
# => [[ 0.00195174 0.01510859 0.00336139 ... 0.07971715 0.09885529 -0.01855042]
[-0.04523939 -0.00046248 0.02036596 ... 0.08779042 0.04936493 -0.06218244]
[-0.05453169 0.01125113 -0.00680178 ... 0.06443197 0.08771271 -0.00063468]]There are many more models you can use to generate vector embeddings with the sentence-transformers library and, because you’re running locally, you can try them out to see which is most appropriate for your data. You do need to watch out for any restrictions that these models might have. For example, the all-MiniLM-L6-v2 model doesn’t produce good results for more than 128 tokens and can only handle a maximum of 256 tokens. BGE-M3, on the other hand, can encode up to 8,192 tokens. However, the BGE-M3 model is a couple of gigabytes in size and all-MiniLM-L6-v2 is under 100MB, so there are space and memory constraints to consider, too.
Local embedding models like this are useful when you’re experimenting on your laptop, or if you have hardware that PyTorch can use to speed up the encoding process. It’s a good way to get comfortable running different models and seeing how they interact with your data.
If you don't want to run your models locally, there are plenty of available APIs you can use to create embeddings for your documents.
APIs
There are several services that make embedding models available as APIs. These include LLM providers like OpenAI, Google, or Cohere, as well as specialist providers like Jina AI or model hosts like Fireworks.
These API providers provide HTTP APIs, often with a Python package to make it easy to call them. You will typically require an API key from the service. Once you have that setup you can generate vector embeddings by sending your text to the API.
For example, with Google's google-genai SDK and a Gemini API key you can generate a vector embedding with their experimental Gemini embedding model like this:
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="A robot may not injure a human being or, through inaction, allow a human being to come to harm.")
print(result.embeddings)Each API can be different, though many providers do make OpenAI-compatible APIs. However, each time you try a new provider you might find you have a new API to learn. Unless, of course, you try one of the available frameworks that are intended to simplify this.
Frameworks
There are several projects available, like LangChain or LlamaIndex, that create abstractions over the common components of the GenAI ecosystem, including embeddings.
Both LangChain and LlamaIndex have methods for creating vector embeddings via APIs or local models, all with the same interface. For example, you can create the same Gemini embedding as the code snippet above with LangChain like this:
from langchain_google_genai import GoogleGenerativeAIEmbeddings
embeddings = GoogleGenerativeAIEmbeddings(
model="gemini-embedding-exp-03-07",
google_api_key="GEMINI_API_KEY"
)
result = embeddings.embed_query("A robot may not injure a human being or, through inaction, allow a human being to come to harm.")
print(result)As a comparison, here is how you would generate an embedding using an OpenAI embeddings model and LangChain:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key="OPENAI_API_KEY"
)
result = embeddings.embed_query("A robot may not injure a human being or, through inaction, allow a human being to come to harm.")
print(result)We had to change the name of the import and the API key we used, but otherwise the code is identical. This makes it easy to swap them out and experiment.
If you're using LangChain to build your entire RAG pipeline, these embeddings fit in well with the vector database interfaces. You can provide an embedding model to the database object and LangChain handles generating the embeddings as you insert documents or perform queries. For example, here's how you can combine the Google embeddings model with the LangChain wrapper for Astra DB.
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_astradb import AstraDBVectorStore
embeddings = GoogleGenerativeAIEmbeddings(
model="gemini-embedding-exp-03-07",
google_api_key="GEMINI_API_KEY"
)
vector_store = AstraDBVectorStore(
collection_name="astra_vector_langchain",
embedding=embeddings,
api_endpoint="ASTRA_DB_API_ENDPOINT",
token="ASTRA_DB_APPLICATION_TOKEN"
)
vector_store.add_documents(documents) # a list of document objects to store in the dbYou can use the same vector_store object and associated embeddings to perform the vector search, too.
results = vector_store.similarity_search("Are robots allowed to protect themselves?")LlamaIndex has a similar set of abstractions that enable you to combine different embedding models and vector stores. Check out this LlamaIndex introduction to RAG to learn more.
If you're new to embeddings, LangChain has a handy list of embedding models and providers that can help you find different options to try.
Directly in the database
The methods we’ve talked through so far have involved creating a vector independently of storing it in or using it to search against a vector database. When you want to store those vectors in a vector database like Astra DB, it looks a bit like this:
from astrapy import DataAPIClient
client = DataAPIClient("ASTRA_DB_APPLICATION_TOKEN")
database = client.get_database("ASTRA_DB_API_ENDPOINT")
collection = database.get_collection("COLLECTION_NAME")
result = collection.insert_one(
{
"text": "A robot may not injure a human being or, through inaction, allow a human being to come to harm.",
"$vector": [0.04574034, 0.038084425, -0.00916391, ...]
}
)The above assumes that you have already created your vector-enabled collection with the right number of dimensions for the model you’re using.
Performing a vector search then looks like this:
cursor = collection.find(
{},
sort={"$vector": [0.04574034, 0.038084425, -0.00916391, ...]}
)
for document in cursor:
print(document)In these examples, you have to create your vectors first, before storing or searching against the database with them. In the case of the frameworks, you might not see this happen, as it has been abstracted away, but the operations are being performed.
With Astra DB, you can have the database generate the vector embeddings for you as you either insert the document into the collection or at the point of performing the search. This is called Astra Vectorize and it simplifies a crucial step in your RAG pipeline.
To use Vectorize, you first need to set up an embedding provider integration. There’s one built-in integration that you can use with no extra work; the NVIDIA NV-Embed-QA model, or you can choose one of the other embeddings providers and configure them with your API.
When you create a collection, you can choose which embedding provider you want to use with the requisite number of dimensions.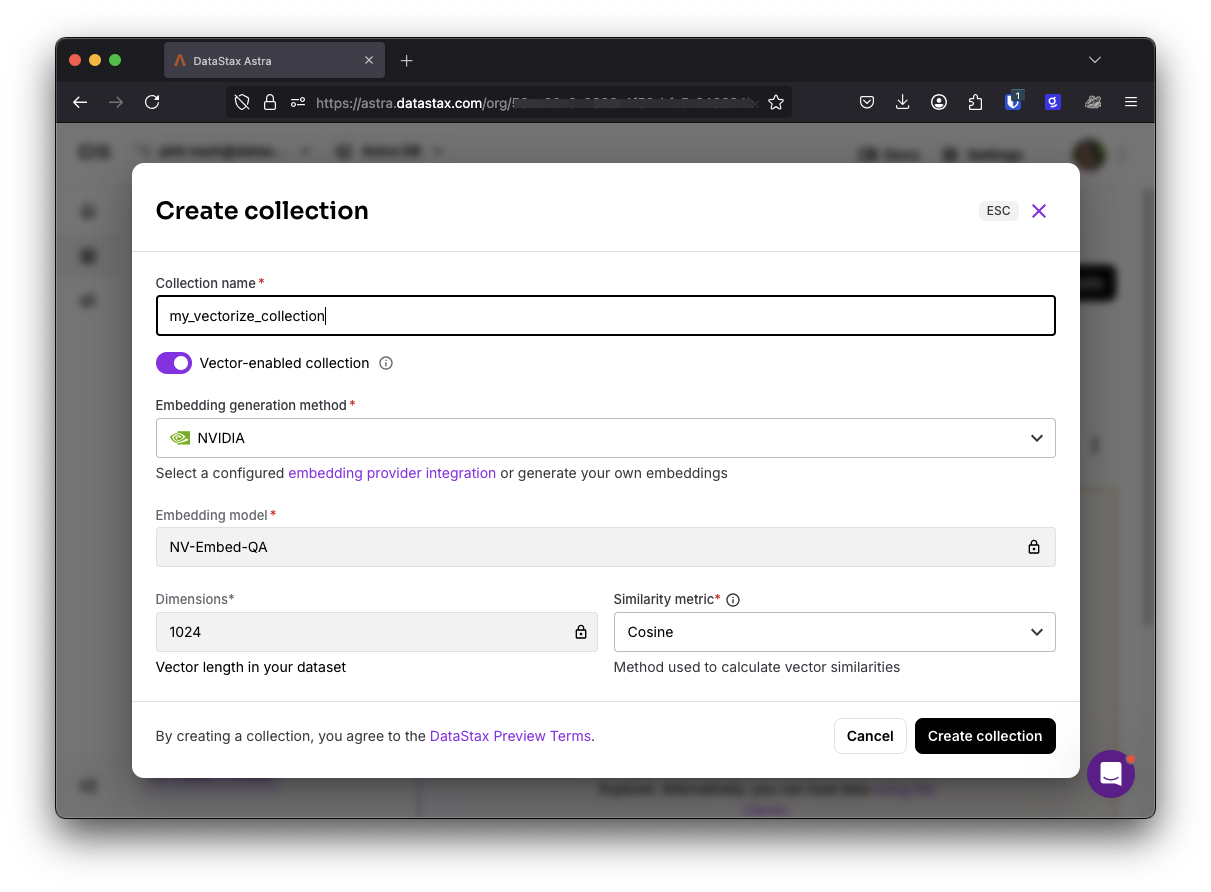
When you set up your collection this way you can add content and have it automatically vectorized by using the special property $vectorize.
result = collection.insert_one(
{
"$vectorize": "A robot may not injure a human being or, through inaction, allow a human being to come to harm."
}
)Then, when a user query comes in, you can perform a vector search by sorting using the $vectorize property. Astra DB will create the vector embedding and then make the search in one step.
cursor = collection.find(
{},
sort={"$vectorize": "Are robots allowed to protect themselves?"},
limit=5
)There are several advantages to this approach:
- The Astra DB team has done the work to make the embedding creation robust already
- Making two separate API calls to create embeddings and then store them is often slower than letting Astra DB handle it
- Using the built-in NVIDIA embeddings model is even quicker than that
- You have less code to write and maintain
A world of vector embedding options
As we have seen, there are many choices you can make in how to implement vector embeddings, which model you use, and which provider you use. It's an important step in your RAG pipeline and it is important to spend the time to find out which model and method is right for your application and your data.
You can choose to host your own models, rely on third-party APIs, abstract the problem away through frameworks, or entrust Astra DB to create embeddings for you. Of course, if you want to avoid code entirely, then you can drag-and-drop your components into place with Langflow.
If you want to chat more about vector embeddings and RAG, drop into the DataStax Devs Discord or drop me an email at phil.nash@datastax.com.
Frequently asked questions
What are vector embeddings?
Vector embeddings are numerical representations of text in multi-dimensional space used for tasks like document retrieval and recommendation systems.
What steps are involved in creating vector embeddings for a retrieval-augmented generation (RAG) app?
To create vector embeddings, you need to:
- Collect unstructured data
- Split data into chunks
- Turn chunks into vector embeddings
- Store embeddings in a vector database
How can I create vector embeddings locally in Python?
You can create vector embeddings locally in Python using pre-trained embedding models from the HuggingFace, specifically using the sentence-transformers library.
What are some limitations of local embedding models?
Local embedding models handle a limited number of tokens effectively, and larger models require substantial memory and storage.
How can I create vector embeddings using an API?
You can create vector embeddings using APIs provided by services such as OpenAI, Google, and Cohere.
Are there frameworks to simplify embedding creation?
Yes, frameworks like LangChain and LlamaIndex offer standardized interfaces that abstract the complexities of embedding models and APIs.
What is Astra Vectorize, and how does it simplify the embedding process?
Astra Vectorize enables Astra DB to automatically generate vector embeddings as documents are inserted or queries are performed.
What are the advantages of using Astra Vectorize?
The advantages include simplified code maintenance, faster performance, improved efficiency, and robustness through pre-tested integrations.




