

Domain Specific Languages (DSLs) provide a way for programmers to increase the expressivity of their code within a specific domain. It enables the developer to gain greater productivity by hiding low-level programming constructs in favor of higher level ones that better link to the elements of the domain itself. DSLs also have the benefit of making it possible for non-programmers to “speak” in the same language as their programming counterparts, thus lowering technical communication barriers.
IMPORTANT: This blog post is written with TinkerPop 2.x in mind. A newer post has been written that is focused on TinkerPop 3.x and introduces a revised development pattern. Please see Gremlin DSLs in Java with DSE Graph for more details.
Pearson’s OpenClass Education-based DSL
An earlier Aurelius blog post entitled "Educating the Planet with Pearson," spoke of the OpenClass platform and Titan’s role in Pearson’s goal of "providing an education to anyone, anywhere on the planet". It described the educational domain space and provided a high-level explanation of some of the conceptual entity and relationship types in the graph. For example, the graph modeled students enrolling in courses, people discussing content, content referencing concepts and other entities relating to each other in different ways. When thinking in graph terminology, these “conceptual entity and relationship types” are expressed as vertices (e.g. dots, nodes) and edges (e.g. lines, relationships), so in essence, the domain model embeds conceptual meaning into graph elements.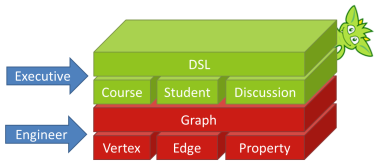 At Pearson, the OpenClass domain model is extended into a programmatic construct, a DSL based on Gremlin, which abstracts away the language of the graph. Engineers and analysts can then ask questions of the graph in their educational domain language, as opposed to translating those familiar terms into the language of vertices and edges. The OpenClass DSL defines the graph schema, extends the Gremlin graph traversal language into the language of education, provides standalone functions that operate over these extensions, and exposes algorithms that are developed from those extensions and functions. Together these components form a coarsely-grained API which helps bring general accessibility to complex graph traversals.
At Pearson, the OpenClass domain model is extended into a programmatic construct, a DSL based on Gremlin, which abstracts away the language of the graph. Engineers and analysts can then ask questions of the graph in their educational domain language, as opposed to translating those familiar terms into the language of vertices and edges. The OpenClass DSL defines the graph schema, extends the Gremlin graph traversal language into the language of education, provides standalone functions that operate over these extensions, and exposes algorithms that are developed from those extensions and functions. Together these components form a coarsely-grained API which helps bring general accessibility to complex graph traversals.
Extending Gremlin into a DSL
Gremlin is a Groovy-based DSL for traversing property graphs and has applicability in the areas of graph query, analysis, and manipulation. It provides for an intuitive way to not only think in terms of a graph, but to program in terms of one as well. One of the interesting properties of Gremlin is that it allows programmers to extend upon the language for even greater programmatic expressiveness, not just within graphs, but within the domain that the graph itself resides.
An important aspect to Pearson’s graph is the notion of "people discussing content." For purpose of the upcoming examples, think of "content" as an online discussion forum, with instructor assigned topics for students to share discourse and open debate. A person writes a post which may be in reference to a different post that was written earlier.
Traversing Discussions in Graph Terminology
Given the "people discussing content" graph structure, a Gremlin novice could immediately begin to navigate the graph. Asking the graph for a list of all vertices with a property key of type and a value of post yields the list of posts in the graph. The Gremlin for such a request is below:
|
|
The traversal becomes a bit more involved when there is a need to walk the depth of the tree of posts:
|
|
To analyze and compare threads of posts within the tree, the path of each thread needs to be analyzed, such that each thread be flattened into a Map, where the key is the userName of the user who wrote the first post in the thread and the value is a unique list of vertices for the threads the user started:
|
|
Evaluating m after execution of the traversal would yield post vertices arranged as follows:
|
|
It is not important to understand the mechanics of the Gremlin above. Its intent is to demonstrate a bit of confusion, in the sense that even a Gremlin expert might have to take a moment to deconstruct what this code is doing. Consider for a moment just how much someone unfamiliar with graphs would have to learn in order to get a set of flattened post threads into this format. The value of a DSL suddenly becomes apparent.
Traversing Discussions in the Domain Terminology
 Developing a DSL can begin with a standalone Groovy script that can be referenced when starting a Gremln REPL or initialized into Rexster or Titan Server through the
Developing a DSL can begin with a standalone Groovy script that can be referenced when starting a Gremln REPL or initialized into Rexster or Titan Server through the init-script configuration element of rexster.xml. In the case of OpenClass, the DSL has evolved well past the early development needs that a "script" satisfies and is now engineered as a Maven-based project deployed as a standalone JAR file.
It is a good practice to use the DSL to centralize the property name strings that make up the graph’s schema. Avoiding the use of hard-coded strings eases future refactoring efforts and makes it straightforward to identify property usage within the DSL itself.
|
|
Examining the Gremlin traversals from the previous section, it can be seen that there is some commonality to them in that they all start with similar types of statements, each building on the next to add additional layers of processing. With Gremlin’s User Defined Steps, it is possible to build composable base steps that extend the language of the graph or operate at a level of abstraction higher than the graph itself.
First, define a class that will be responsible for containing the step definitions and for initializing them into Gremlin:
|
|
With the Steps class in place, a first step definition can be added to encapsulate post filtering:
|
|
Including this step simplifies the three Gremlin statements written in the previous section to:
|
|
 The
The post step replaces usage of has(S.PROPERTY_TYPE, S.TYPE_POST). That change doesn't make the code much more readable, but it is a start. Continuing with the example, two additional steps are included, one to traverse the tree of post vertices and one to flatten each thread (or discussion path):
|
|
The addition of these steps simplifies the traversals and expands their flexibility:
|
|
The steps have also been defined in such a way that the DSL gains the interesting capability to parameterize behavior of the traversal. Parameterization of steps introduces flexibility to the DSL, allowing the consumers of the functions to tune the internals of the traversal for performance, filtering, transformations, etc. Note how the last example of flattenThread provides a closure for the final argument, making it possible to introduce dynamic behavior to traversals. Instead of always keying the map on userName, that behavior is now determined by the user of DSL.
DSL Development Patterns
The list below represents recommended patterns to follow when building DSLs with Gremlin:
- Centralize property names, edge labels and other string values as global variables. Don’t embed string literals into the DSL.
- Include a schema class with some sort of initialization function that takes a Blueprints
Graphinstance as an argument and configures the indices of the graph. A schema class is especially important when using Titan and its Type Definitions. - Standalone Groovy scripts are just a starting point for a DSL. Those scripts will quickly grow in complexity and become unmanageable. Treat the DSL as its own project. Use a dependency management and build system like Maven or Gradle to produce compiled code that can be referenced in other projects, pulled into the Gremlin REPL with Grape or copied to the path of Rexster or Titan Server and configured for use with
importsandstatic-importssettings. Note that direct support of Grape in the REPL will be replaced in Gremlin 2.5.0 with theGremlin.use()function which wraps Grape and performs a similar function. - Given deployment of the DSL to Rexster or Titan Server, client-side code no longer needs to pass long, complex Gremlin scripts as strings for remote execution via REST or RexPro. Client applications can just call parameterized functions from the DSL exposed on the server.
- Write tests. Use the aforementioned schema class to “set-up” a
Graphinstance on each run of the tests to ensure that changes to the schema do not introduce problems and that new additions to the DSL will work properly in the production graph given that configuration. Use TinkerGraph for a lightweight means to test DSL operations. - Write in-line documentation for the schema, User Defined Steps, and other functions, but consider avoiding javadoc. Use a tool like Groc, which processes Markdown formatted text and produces documentation that includes the source code.
- Design DSL components as composable blocks, such that one or more blocks can be used together for even higher-level operations. When possible, think generically and design functions that can be altered at the time they are called through parameterization with settings and closures.
- The DSL is not just about extending Gremlin with User Defined Steps. Make use of the Groovy language and write standalone functions that operate on the graph, within User Defined Steps, or anywhere it makes sense to encapsulate graph functionality.
- Use an IDE, like IntelliJ. Since Gremlin is Groovy, IDE features like syntax validation and code complete help make writing Gremlin more productive.
Conclusion
Gremlin is a general purpose graph traversal language, but developers can extend it with the specific rules and nomenclature of their domain. This additional layer to Gremlin can provide for a robust toolset for programmers, analysts and others interested in the data that the graph contains.
Pearson's OpenClass DSL continues to expand allowing realization of the following benefits:
- All logic related to the graph is centralized in the DSL providing a standard interface for any part of the organization that wishes to access the graph for information.
- Non-programmers leverage the DSL in their work, as there is less “Gremlin-graph” language and more “education-graph” language.
- Ad-hoc analysis of the graph tends to be less error prone and more productive, as the higher-order functions of the DSL are tested versions of common and sometimes mundane traversals (e.g. traversing a tree).
- Interesting and unintended discoveries occur when exploring the graph by mixing and matching functions of the DSL.
The introduction of a DSL over Gremlin will be beneficial to projects of any size, but will quickly become a requirement as the complexity of the conceptual model of the domain increases. Investing in a DSL to make it a core component of a graph engineering strategy, should be considered a common pattern for productionalizing Gremlin in the TinkerPop and Aurelius technology stacks.
Acknowledgements
Dr. Marko A. Rodriguez read draft versions of this post and provided useful comments







