

We often talk about how Cassandra is designed from the ground up for fault-tolerance and availability. Today I want to discuss how this actually works in practice, and in particular what Cassandra can tell clients about request state when machines go down.
First, let's start with a very basic diagram describing a non-distributed server:
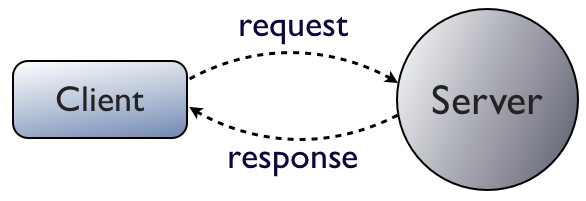
Client makes a request and gets a response. Simple!
But what happens when the server goes down before it replies?
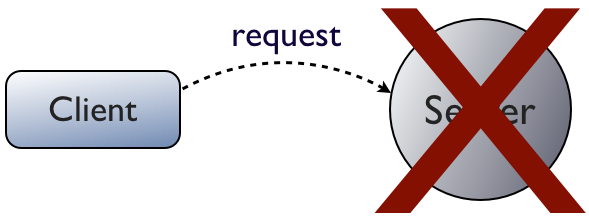
The client doesn't know what happened. If it was trying to perform an update, it will have to retry the request when the server comes back up.
Everything else we're going to cover here is just an extension of this to a distributed system.
First, let's look at how things work when everything goes according to plan:
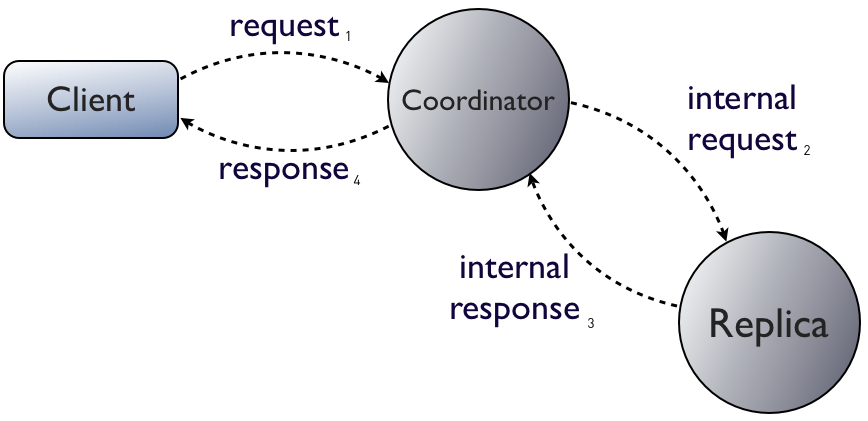
A client may talk to any node in a Cassandra cluster, whether or not it is a replica of the data being read or updated. The node a client talks to, the "coordinator," is responsible for routing the request to appropriate replicas.
If the coordinator fails mid-request, we're in a similar situation to what we had in the non-distributed case: the client is in the dark and has no choice but to retry. The only difference is that the client can reconnect to any node in the cluster immediately.
The interesting case is when a replica fails but the coordinator does not. There are actually two distinct scenarios here. In the first, the coordinator's failure detector knows that the replica is down before the request arrives:
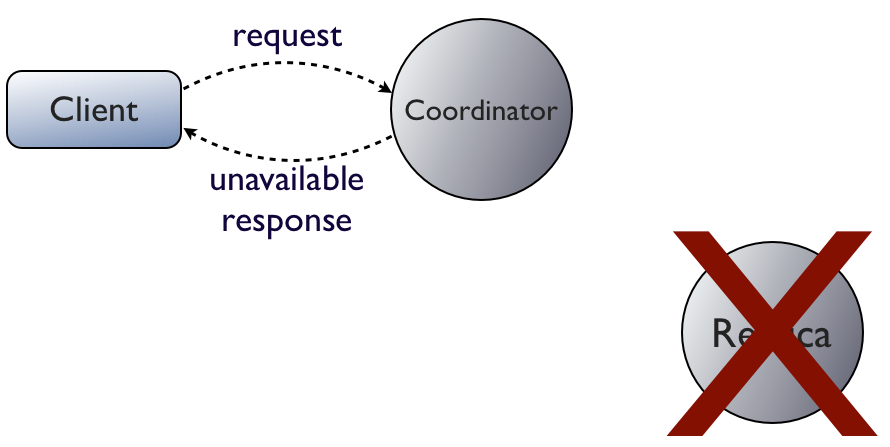
Since the coordinator knows the replica is down, it doesn't even attempt to route the request to it. Instead, it immeditely responds to the client with an UnavailableException. This is the only time Cassandra will fail a write. (And even then, you can request that Cassandra allow the write with ConsistencyLevel.ANY.)
Let me say that again, because it's the single greatest point of confusion I see: the only time Cassandra will fail a write is when too few replicas are alive when the coordinator receives the request.
So what happens if the replica doesn't fail until after the coordinator has forwarded the client's request?
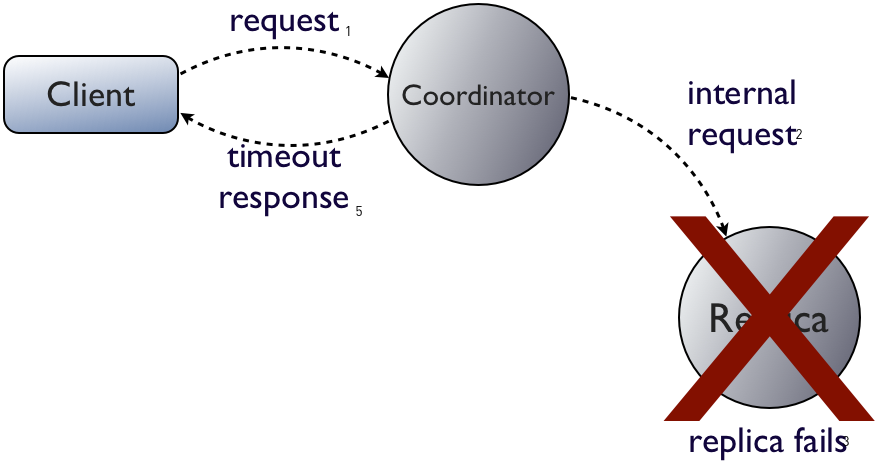
In this case, the coordinator replies with a TimedOutException. Starting in Cassandra 1.2, it will also include an acknowledged_by count of how many replicas succeeded. Also in 1.2, Cassandra provides different timeouts for reads, writes, and other operations such as truncate.
The coordinator is in the same situation the client was in during the single-server failure scenario: it doesn't know whether the request succeeded or failed, so all it can tell the client is that the request timed out.
Remember that for writes, a timeout is not a failure. (To make this more clear, we considered renaming TimedOutException to InProgressException for Cassandra 1.2, but decided against it to preserve backwards compatibility.)How can we say that since we don't know what happened before the replica failed? The coordinator can force the results towards either the pre-update or post-update state. This is what Cassandra does with hinted handoff:
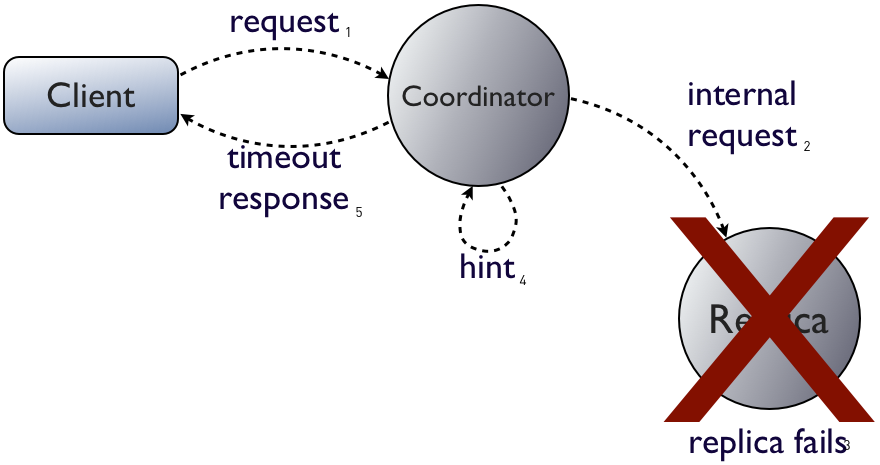
I labeled "timeout response" step 5 in the previous diagram. Recording the hint is the missing step 4: the coordinator stores the update locally, and will re-send it to the failed replica when it recovers, thus forcing it to the post-update state that the client wanted originally.
In the next post, I'll cover how we generalize this to multiple replicas.






