

As a Solutions Engineer at DataStax, I often hear the question from new customers: how do I know that all of my data is loading correctly in my DataStax Enterprise (DSE) cluster? This is especially important when data governance is important or when DSE becomes the System of Record.
With traditional databases, there are several ways you can reconcile data between environments. For example:
- Count the number of rows inserted and check that they match what you are expecting
- Count the number of rows inserted and check that they match what you are expecting
- Count the number of rows inserted and check that they match what you are expecting
- Check columns based on values; for example, count the number of rows that have NULLs in particular columns
- Sum the amount fields if there are any
- Verify that there are no errors in the log files
This is harder to do with Apache Cassandra due to:
- Data modeling: denormalizing and duplicating data is correct and the right approach. Additionally, primary keys should be values that will be used for data retrieval rather than an incremental value.
- Upserts: if your data model is not done correctly and your primary key is not unique, you might be updating data rather than inserting new rows – a valid operation, you will not get an error.
- Wide rows: counting the number of “rows” won’t match the source when you have composite partition keys. Additionally, nodetool tablestats “Number of partitions (estimate)” is just that – an estimate
- Data Distribution: SELECT COUNT(*) will fan out the query to all the nodes and is not recommended with CQL as it can time out or return inconsistent value if you have a large amount of data
- Queries: the biggest data modeling challenge when first using DSE is the limitation on which field you can filter on
That being said, you do have options:
- DSE Analytics: integrates real-time and batch operational analytics capabilities with an enhanced version of Apache Spark™
- Benefits: SparkSQL allows you to execute relational queries over distributed datasets using a variation of SQL language
- Limitations: Depending on the size of the data and hardware, these queries can take longer to execute
- DSE Search: provides advanced search capabilities and more efficient ways of indexing data based on Apache Solr™
- Benefits: provides near real-time query functionality for filtering on non-primary keys and partial text
- Limitations: queries run with CL=LOCAL_ONE so environment needs to be monitored closely to avoid dropped mutations and repairs need to run on a regular basis. Additionally, indexing needs to be completed and up-to-date before being able to leverage DSE Search for reconciliation.
- Other Options
- CQL aggregates: min, max, avg, sum, and count are built-in functions starting with DSE 5.0. This should only be used for a single partition; otherwise, there can be a performance impact.
- Cassandra Count: a more efficient way to count the number of rows, written by Brian Hess, fellow Solutions Engineer at DataStax
- User Defined Aggregates (UDA)/User Defined Functions (UDF): manipulate data in queries by creating custom functions
Here are some examples of how you can use these options to reconcile between your source system and DSE:
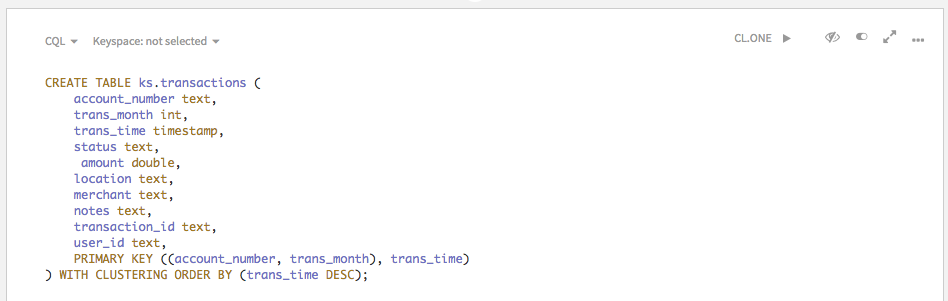
Let’s use this table for the examples:
DSE Analytics
DSE 6.0 introduced a new feature called AlwaysOn SQL, a highly-available, secure SQL service for analytical queries, which can be executed in Studio directly. Remember to run queries with CL=LOCAL_QUORUM for precise results.
1. Return total number of rows:

2. Validate date field, ex, rows with transaction date prior to 2000:

3. Validate fields, ex rows where merchant is blank:

4. Return total of amount:

DSE Search
You will need to create a SEARCH INDEX on the table first. Note: example below will index all the columns, which you might not want to do in a live environment.

1. Return total number of rows:
2. Validate date field, ex, rows with a transaction date prior to 2000:
3. Validate fields, ex rows where merchant is blank:
4. Return total of amount: Not doable with DSE Search
Other Options
CQL Sum: select sum(account_number) from ks.transactions where account_number = ‘12345ABCD’ and trans_month = 1;
Cassandra Count: ./cassandra-count -host 127.0.0.1 -keyspace ks -table transactions
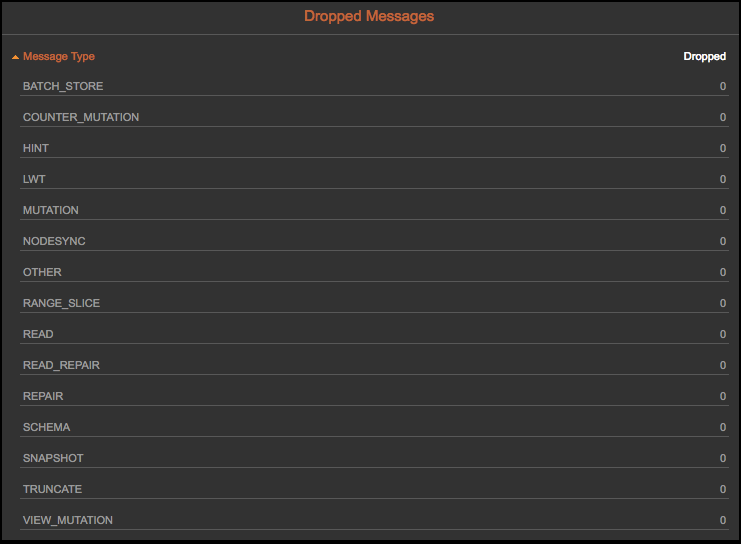
As you can see, these are different ways to help you identify reconciliation differences between your data, your source system, and DSE. Due to the delay in indexing all the data and only being able to query with consistency LOCAL_ONE, DSE Analytics with Apache Spark integration is the recommended method.
Once you have identified discrepancies, you will still need to investigate these differences. Regarding that last reconciliation point on checking log files, make sure you monitor your application log as well as system.log file on each of the nodes.
You can also monitor your DSE cluster through Opscenter, for example, ensure that there are no dropped messages that could impact your reconciliation queries (alternatively via nodetool tablestats).









