

Hello again and welcome to part 2 of my 3 part series on moving from Cassandra tables to using DataStax Enterprise Search. If you haven’t read part 1 yet go take a look as it contains the backstory for this series.
In part 1 we looked at the types of searches we perform in KillrVideo, scratched the surface on how those searches were implemented, and then I asked a set of questions that lead us into why we might use DSE Search. Here in part 2, I’ll discuss why we moved to using DSE Search, detail what the transition encompassed, and explain considerations I took into account when making the switch.
One thing I’d like to point out before we get started is the Cassandra only approach that we replaced with DSE Search is perfectly valid. At times I make the case for why the Search approach is better IMO for our particular situation, but it is not broken or anything along those lines and it follows established denormalized query-first design patterns.
The move to DSE Search
So, we decided to switch from using only Cassandra tables for our searches to using DSE Search. That part is obvious enough, but some of you might be curious as to why we made this move.
All of the searches worked perfectly fine with Cassandra tables, they performed well, and honestly the code to implement was not terribly complex so what was it that pushed us over the edge?
It was the need to expand searches to include more than tags, provide more comprehensive, “fuzzy” searches, and enable more flexibility for future search enhancements.
Why, why, why
If you remember from part 1, I detailed what the various searches were all doing. One common denominator was the use of the tag column for all of our searches. Now, we wanted to expand our searches to include both video name and description columns along with tag. Sure, I could modify the existing schema to include the new columns, but then I would have a data migration to worry about to populate the new columns on existing rows. I would also have to touch all code points that intersected with any of the searches, update entity classes, change CQL queries, and potentially change or add code logic to handle the new columns not to mention the inflexibility of it all if I needed to add another column(s) down the line.
Now in all frankness I would have to do some of this if we switched to using DSE Search, but as you’ll see it’s more of a removal task than a data model and design change. While writing this article it also dawned on me I have the benefit of hindsight since we’re already using Search. It’s easy to say “well just do it this way”, but when coming at this fresh and looking at what we were trying to accomplish it was a no brainer. Comparing the Cassandra, Search, Analytics, and Graph workloads available to DSE the requirements here almost read like a product page for Search. It’s the right tool for the job.
Time to get dirty
Ok, we made the decision to use DSE Search and now it’s time to update the application. Before I started hacking at code though I needed to figure out what I was dealing with from a query perspective. Remember from part 1 of this series we have the following Cassandra only CQL queries to perform our searches.
// typeahead
SELECT tag FROM tags_by_letter WHERE first_letter = ? AND tag >= ?
and
// tag and "more videos like this"
SELECT * FROM videos_by_tag WHERE tag = ?
Not very hard, but we need multiple, specialized tables to handle our searches.
In order to start using DSE Search I needed to create a search index. At this point I just want to point out my intent here is not to be a whole guide on how to create and implement search indexes. The focus is on our case moving from Cassandra tables to DSE Search. I will go over some of the highlights just to connect some dots and break down the sections that are relevant for this post. If you are not familiar with how to create Search indexes I highly suggest you take a look at this blog post on creating search indexes in DSE 5.1 along with the documentation on the same topic. If you want a total deep dive on DSE Search I highly suggest you check out the DataStax Academy course on DSE Search and prepare to have your mind blown.
Back to it
Here is the schema defined for our videos table. It was mostly auto-generated after enabling Search with dse_tool. If you are curious about how the schema is configured take a look here. Why the videos table? Because it holds all of the information necessary for our searches, namely, tags (as before), name, and description and since the videos table is populated on each video upload we get everything we need without having to write to multiple denormalized tables. As a matter of fact, implementing our searches against the videos table allowed us to remove the VideoAddedHandlers class and the asynchronous Cassandra queries contained within, but I am getting ahead of myself.
For our current discussion lets focus on the following snippet:
<!-- For search autocomplete functionality, copy name and tags fields to search_suggestions field -->
<field indexed="true" multiValued="false" name="search_suggestions" stored="true" type="textSuggest" />
<copyField source="name" dest="search_suggestions" />
<copyField source="tags" dest="search_suggestions" />
&m;
Notice the field name of “search_suggestions” and both the “name” and “tags” copyField's. We essentially copied name and tag column information into a single field called “search_suggestions”. This will come into play here in a moment.
Then take a look at the “Basic fields” section:
<!-- Basic fields -->
<field indexed="true" multiValued="false" name="added_date" stored="true" type="TrieDateField"/>
<field indexed="true" multiValued="false" name="location" stored="true" type="TextField"/>
<field indexed="true" multiValued="false" name="preview_image_location" stored="true" type="TextField"/>
<field indexed="true" multiValued="false" name="name" termVectors="true" stored="true" type="TextField"/>
<field indexed="true" multiValued="true" name="tags" termVectors="true" stored="true" type="TextField"/>
<field indexed="true" multiValued="false" name="userid" stored="true" type="UUIDField"/>
<field indexed="true" multiValued="false" name="videoid" stored="true" type="UUIDField"/>
<field indexed="true" multiValued="false" name="location_type" stored="true" type="TrieIntField"/>
<field indexed="true" multiValued="false" name="description" termVectors="true" stored="true" type="TextField"/>
As I mentioned above most of this was auto-generated. This includes indexes for all of the columns in the videos table which allows us to perform searches against any of the columns in our table. For our case we are using tags, name, and description. If you are curious about why we might want the other columns I refer you to OutOfScopeOfThisArticleException. It is something I will cover in the future. The important takeaway is we have the needed columns indexed.
Some of you might be thinking “wait, isn’t this more complex than just creating some Cassandra tables like you had before?”. It’s about the same IMO. We’re defining fields and their types in a schema, just a different type of schema, but once we do this we are all set to go…for all of our searches!
Back to creating our index
I’ve pulled the following out of KillrVideo’s bootstrap script. We use this to create all of the initial database artifacts needed to run KillrVideo on cluster creation. This may obviously be different for you depending on your setup, but it should give you the general idea. We are using dsetool to both create and reload our core against the videos tables in our killrvideo keyspace.
echo '=> Creating search core'
dsetool -h $YOUR_CLUSTER_IP create_core killrvideo.videos schema=$YOUR_SCHEMA_LOCATION/videos.schema.xml solrconfig=$YOUR_SCHEMA_LOCATION/videos.solrconfig.xml -l $USERNAME -p $PASSWORD
echo '=> Reloading search core'
dsetool -h $YOUR_CLUSTER_IP reload_core killrvideo.videos schema=$YOUR_SCHEMA_LOCATION/videos.schema.xml solrconfig=$YOUR_SCHEMA_LOCATION/videos.solrconfig.xml -l $USERNAME -p $PASSWORD
Once this completes, that’s it. Search indexes are in place and ready for use. As we insert data into the Cassandra based videos table our indexes will automatically be updated. No extra queries, explicit code, or anything else needed.
One more thing on this whole schema thing before I move on. Search index creation will be a whole lot easier in the upcoming DSE 6. I’ll have some posts digging into this in the near future and I’m totally stoked to say the least so keep an eye out for updates.
Let’s take stock
I think it’s a good idea to summarize where we’re at so far. We’ve effectively replaced our 2 Cassandra only tables with a Search core loaded against the videos table, and we’ve loaded that same core for use within our database. Within our search core we created a field named “search_suggestions” that combines data from the tags and name columns into a single field and now we can start performing searches using DSE Search against any of the fields we created in the search schema above.
Cassandra based search vs. DSE Search comparisons
So now comes the fun part where we get to take a look at how the different Cassandra and Search based searches compare.
“Typeahead” search
Let’s start with the “typeahead” search from the search bar. For our examples I’m using query parameters with value ‘d’. This is the same as if I typed ‘d’ in the search bar from the UI.
Here’s the original CQL:
SELECT
tag
FROM
tags_by_letter
WHERE
first_letter = 'd' AND tag >= 'd';
Here’s the CQL with Search in place:
SELECT
tags, name
FROM
videos
WHERE
solr_query='{"q":"search_suggestions:d*", "paging":"driver"}';
Right away there are a couple differences to point out.
One, notice that in the original query I am selecting only the tag column. This is because the tags_by_letter table only includes tags, there is nothing else to extract. The purpose of the table is to provide tags in a very efficient manner. In the Search based query I am selecting both tags and name in this case, but I could get any column from the videos table if I wanted to.
Also, notice the difference between the tag and tags columns between the two queries. Since the Search based query is pulling from the videos table we return a set of tags in the tags column compared to a single tag per row.
The final piece is probably the most obvious of all, the WHERE clause. In the original query we are using both our partition key and clustering column to find rows that have the letter ‘d’ with tags >= ‘d’. I should note this will return an alphabetically ordered list of results because of how clustering columns work. In the Search query we are looking for any words starting with the letter ‘d’ from the “search_suggestions” field. This field is a combination of all tags and names. Don’t forget tags is a set of tags per row.
I’m totally glossing over the “paging” parameter you see above in the Search query. We will get to that in part 3.
Now comes the fun. Watch what happens when I execute each query. Also remember that our goal was to expand our search results to provide more complex and varied results.
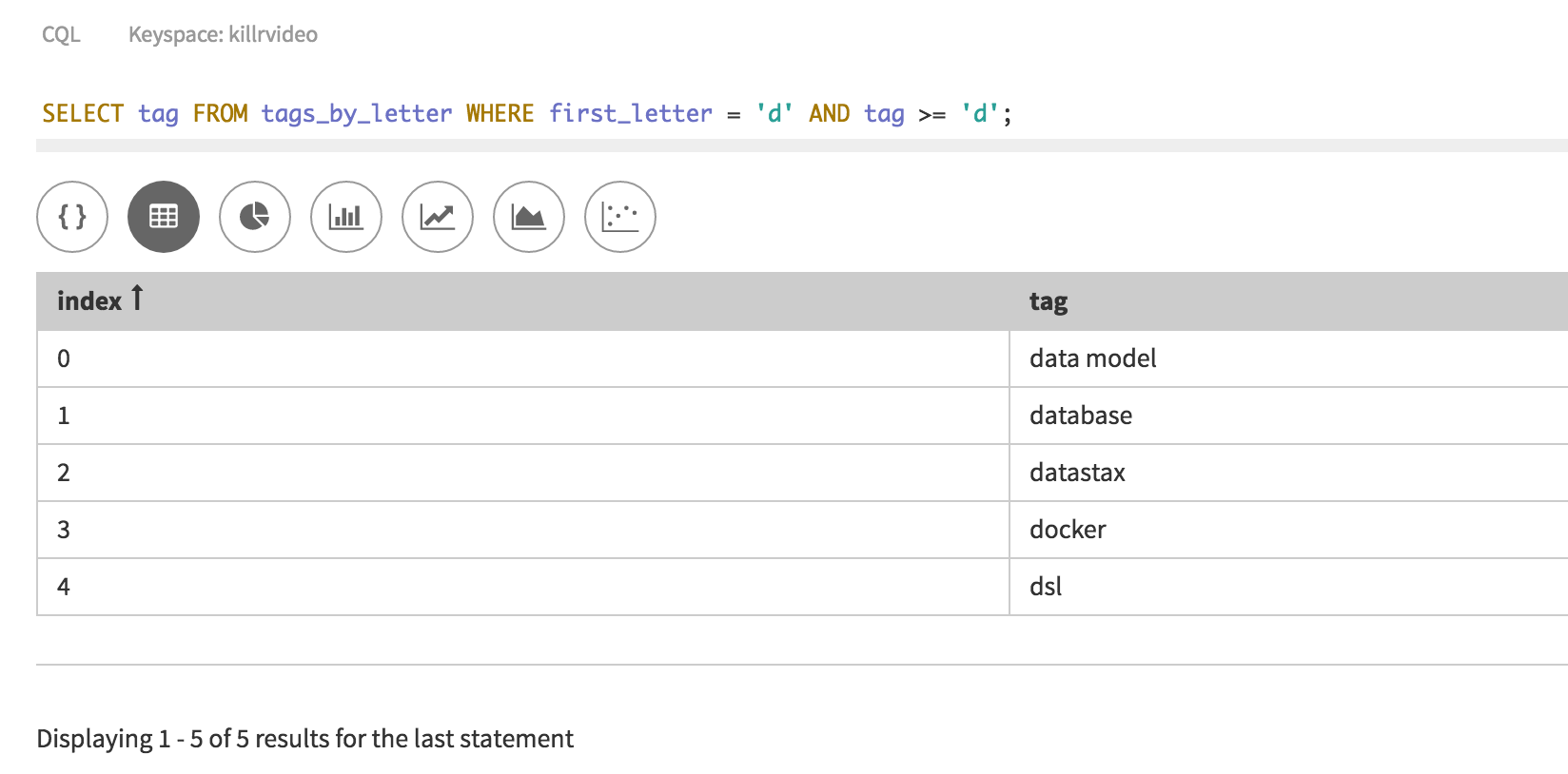
I’d like to point out there is no LIMIT clause in my query and this is from a database with thousands of videos.
Now, here is the Search query.
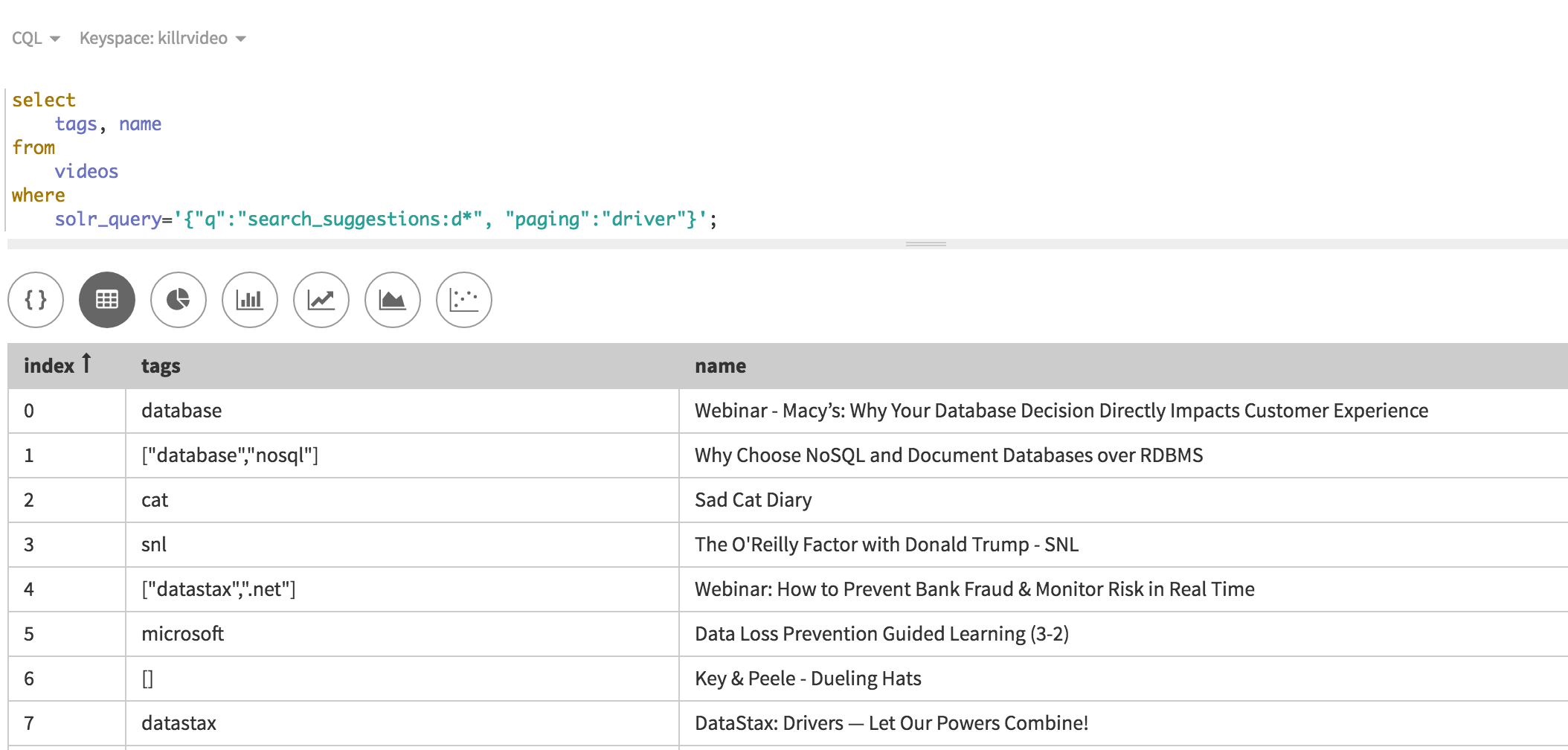
………
……………
……………………..

Notice not only the amount of results, but that we are matching across both the tags and name columns and we are matching within the set of values in the tags column. I could have added description or any other relevant column from the videos table if I wanted to by simply adding it to my query.
So, ok, we have more results, we have more variation in results, but you might notice we have a lot of repeated terms where the Cassandra based query returned a more succinct set of results. In my case I handled this with a little regex and a TreeSet that ensures I don’t have repeats and results are ordered alphabetically naturally within the set. As a matter of fact here is that very snippet:
// Use a TreeSet to ensure 1) no duplicates, and 2) words are ordered naturally alphabetically
final Set suggestionSet = new TreeSet<>
();
/**
* Here, we are inserting the request from the search bar, maybe something
* like "c", "ca", or "cas" as someone starts to type the word "cassandra".
* For each of these cases we are looking for any words in the search data that
* start with the values above. */
final String pattern = "(?i)\\b" + request.getQuery() + "[a-z]*\\b";
final Pattern checkRegex = Pattern.compile(pattern);
int remaining = rows.getAvailableWithoutFetching();
for (Row row : rows) {
String name = row.getString("name"); Set tags = row.getSet("tags", new TypeToken() {});
/**
* Since I simply want matches from both the name and tags fields
* concatenate them together, apply regex, and add any results into
* our suggestionSet TreeMap. The TreeMap will handle any duplicates.
*/
Matcher regexMatcher = checkRegex.matcher(name.concat(tags.toString()));
while (regexMatcher.find()) {
suggestionSet.add(regexMatcher.group().toLowerCase());
}
if (--remaining == 0) {
break;
}
}
It was a small price to pay for taking this particular approach and there was no noticeable performance degradation in doing so. I will explore some other options coming up here in the future.
Almost there
Bear with me for another example to bring this together. In the following case I purposely removed the constraint on my pagesize to illustrate the difference in results. Remember with our Cassandra only query we returned just 5 tags out of thousands of videos. These were simply the only tags that started with the letter ‘d’ in the database. So, nothing wrong with this, it is doing exactly what it was designed for, but we wanted to provide a “richer” experience and expand beyond tags. With Search in place we could now do exactly that and provide a definite increase in variation all while working right out of the videos table. I could expand this further to include any column in my table by simply modifying my query, no data model change needed.
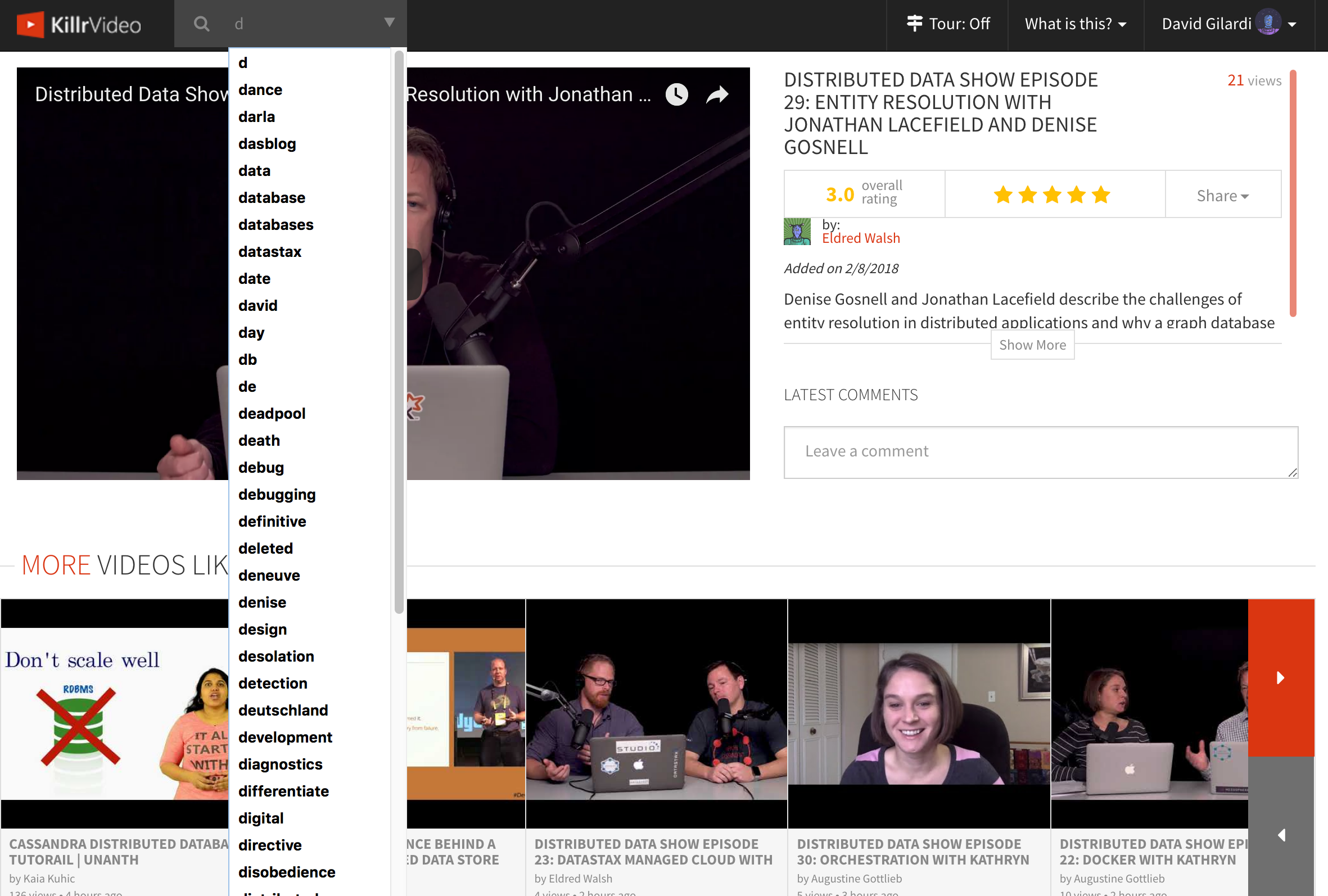
Hopefully the amount, and variation of, the options in my search bar are obvious. Compare this to the 5 results we had previously.
I don’t know about you, but I could use a break right about now.
Ok, moving on.
Tag search and the “more videos like this” section
I’m just going to go ahead and combine these because the original Cassandra only searches are effectively the same. For reference we are talking about the following query using ‘dsl’ as the query parameter for the
Ok, moving on.
Tag search and the “more videos like this” section
I’m just going to go ahead and combine these because the original Cassandra only searches are effectively the same. For reference we are talking about the following query using ‘dsl’ as the query parameter for the tag column:
SELECT * FROM videos_by_tag WHERE tag = 'dsl';
From the UI perspective this query was used both if an end-user clicked on any of the tag buttons on the video detail page and when viewing the “More videos like this” section at the bottom of the video detail page. The former case would simply pass the clicked tag value to the back-end and execute a query similar to what you see above. In our example it would be as if I clicked on the “dsl” button below.
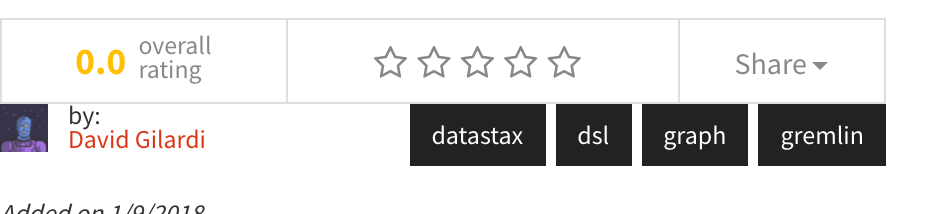
The latter case would essentially loop through all of the different tags associated with a video and execute the above query for each tag in the list. In our example we have 4 queries for “datastax”, “dsl”, “graph”, and “gremlin”. The results were then combined and used to populate the “more video like this” section.
Something to point out
At this point I’m sure you have noticed that tags are a core component of how searches are powered. The UI enforces including at least one tag on video upload and they are included in the design for every search. However, we loosened this restriction when pulling videos from the back-end using the generator service. We did this because the difference in the amount of videos available to us without tags compared to those with tags under the various topics we are pulling from YouTube is pretty huge. There are also some pretty useful/cool videos out there that don’t include tags. For each of the Cassandra only searches, if there are no tags, you get no videos, nothing.
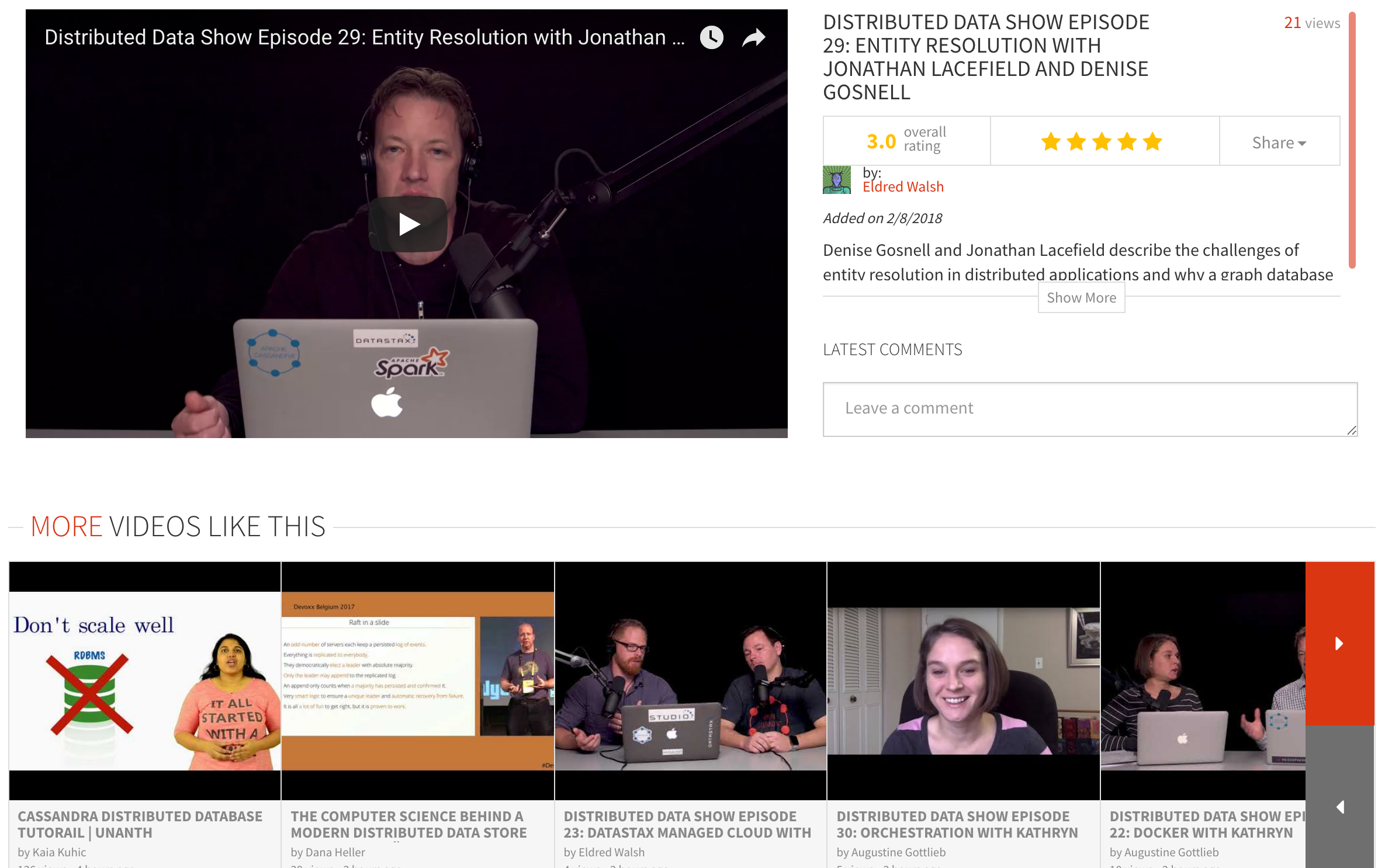
Case in point, take a look at the above image. There are no tags at all, yet if you look at the “more videos like this” section at the bottom notice how relevant our results are when compared to the video we are viewing. This is a nice example of how using Search allowed us to provide a more comprehensive experience by making it easy to include multiple facets of data and even cover the case of missing one of our key pieces of data. In the previous solution the “more videos like this” section would be empty.
Let’s wrap this up
Ok, so we talked about why we made the switch to using DSE Search, looked at some of the details of how this was done, discussed some considerations taken into account, and then viewed some result comparisons. That’s a good amount of stuff, but it’s not the full picture. My goal here was to demonstrate how using DSE Search enhanced our search capability and didn’t require us to radically change our overall design. Hopefully I accomplished my goal.
In part 3, we’ll dive into simplifying our code base by removing the pieces we no longer needed after moving to Search, tie up some loose ends, and look at advanced search capabilities we got for “free” simply because we are using Search.
See you soon :D










