

Many of us saw the ChatGPT Vision announcement a few weeks ago, which represents an incredible step forward in the utility of large language models (LLMs). Having a model that can now understand images in addition to text opens up a large avenue of new use cases, and unlocks entire segments of image data for use in generative AI settings.
Some of these use cases are being loudly shared on social media (interior design, teaching biology, etc.), but these posts only scratch the surface on what multimodal text and image models have to offer. Now that ChatGPT can “see, hear, and speak,” we can provide it with even more contextual information to augment its output. I’m talking, of course, about retrieval augmented generation (RAG).
Even the most powerful LLMs (as well as Large Multimodal Models or LMMs, a term Microsoft recently coined) can generate hallucinations. By feeding them the most recent and accurate context from your data, which now includes images, you can steer them toward producing more accurate and relevant results. This can be accomplished by adapting RAG to a multimodal use case instead of its standard text-only implementation.
In this post, we'll walk you through a hands-on example of how to populate a multimodal vector store with CLIP and Astra DB, use open-source MiniGPT-4 to answer questions based on text and images, and employ RAG to provide it with contextual understanding to mitigate hallucinations and improve relevance to your data.
What is a multimodal model?
Before diving deep into the mechanics and impact of RAG on multimodal models, it's essential to first understand what we mean by "multimodal."
In the AI space, a "mode" or "modality" refers to a distinct type or form of data that can be fed into (input) or produced by (output) a model. Think of modalities as the various languages or dialects through which a model communicates. Each modality offers unique information, and when combined, they can provide a holistic and comprehensive understanding of the input data.
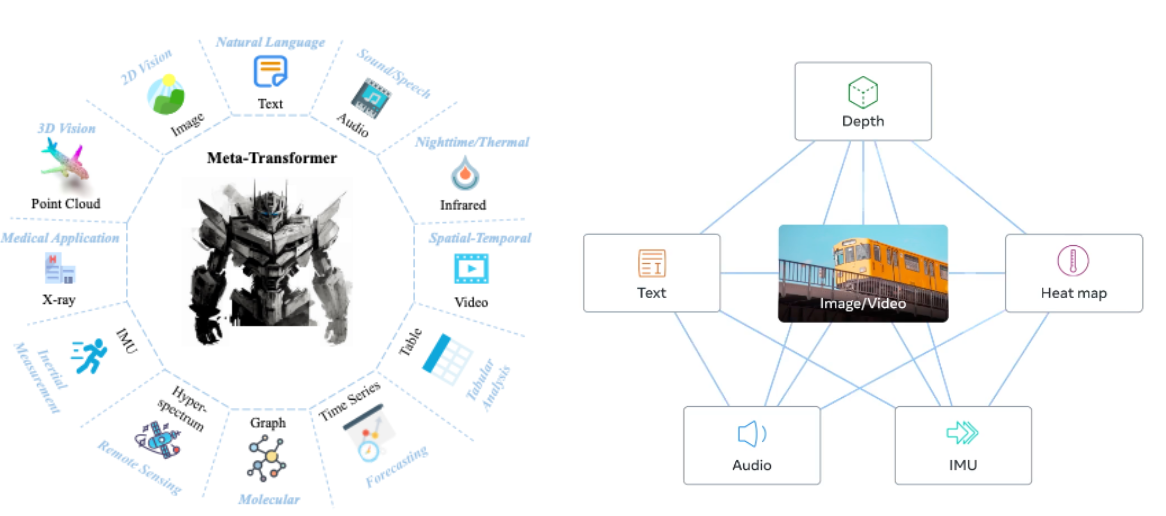
Recent multimodal works Meta-Transformer (left) and ImageBind (right)
The AI landscape is brimming with groundbreaking multimodal models. While "multimodal” might evoke images of text and pictures dancing in tandem, the scope is much broader. Multimodal models can manifest as:
- LLMs Like GPT-4, these models primarily deal with vast volumes of textual data but have been expanded to accommodate other modalities.
- Embedding models Models like CLIP, which are adept at creating embeddings for data, enabling models to understand the context and relationships between diverse data types.
- Diffusion models Examples include Stable Diffusion and DALL·E, which spread information across nodes, enabling intricate data interplay.
While the current spotlight might be on text and image models (owing to their vast applications and tangible outcomes), the horizon of multimodal models extends far beyond this. Audio, video, sensor data, and even real-time physiological markers can be incorporated, widening the possibilities and applications of these models. Recent research (pictured above) has even begun designing frameworks to combine many different modalities into a single shared embedding space.
Code walkthrough
[UPDATE 11/6/23] As of OpenAI Dev Day, developers now have access to the ‘gpt-4-vision-preview’ model, and we have released a revised Colab notebook for people to take advantage of this model that is easier to set up, more accurate, and less expensive.
Now let’s dive into some code to see how to actually implement this in practice. A caveat: at the time of writing, GPT Vision API access wasn’t available. This means we will instead make do by using an open source alternative, MiniGPT-4, in our example. You can loosely follow along with this Google Colab for the code and outputs. However, note that in order to instantiate and run the MiniGPT-4 model locally, you will need access to a machine with > 32GB RAM and > 24GB GPU memory.
We will walk through the following steps:
- Setting up a multimodal vector store using DataStax Astra DB
- Setting up a functioning multimodal chat model using MiniGPT-4
- Combining the two using the RAG pattern to enable multimodal chat
Multimodal vector store
A multimodal vector store is very similar to a typical "text only" vector store, with just a couple of differences that I’ll call out along the way. Let’s start by downloading the first of 2,313 chunks of the laion2b-en dataset to seed our vector store with some image and caption pairs. The files we are downloading include the image URL, text caption for the image, CLIP embedding of the image, CLIP embedding of the caption, and some varied metadata fields.
!mkdir multimodal_data
import numpy as np
import pandas as pd
from huggingface_hub import hf_hub_download
REPO_ID = "laion/laion2b-en-vit-l-14-embeddings"
for filename in [
"img_emb/img_emb_0000.npy",
"text_emb/text_emb_0000.npy",
"metadata/metadata_0000.parquet",
]:
hf_hub_download(repo_id=REPO_ID, filename=filename, repo_type="dataset",
local_dir="multimodal_data")
img_embs = np.load("multimodal_data/img_emb/img_emb_0000.npy")
text_embs = np.load("multimodal_data/text_emb/text_emb_0000.npy")
metadata_df = pd.read_parquet("multimodal_data/metadata/metadata_0000.parquet")Now, we need a vector store to put them in. We’ll use Astra DB, which is extremely easy to set up and can handle high volumes of both read and write traffic. You can follow the steps here to quickly create a new vector database. Once done, you’ll need to grab the database ID and auth token to use in the below code. This will create a table that we’ll use later to store our vectorized images and captions.
import cassio
from cassio.table import MetadataVectorCassandraTable
cassio.init(
token="YOUR TOKEN HERE",
database_id="YOUR DB ID HERE",
)
mm_table = MetadataVectorCassandraTable(
table="multimodal_demo_vs",
vector_dimension=768, # CLIP VIT-L/14 embedding dimension
)So far, these steps have been the same as setting up a traditional “single modal” vector store. However, one consideration of multimodal stores is that we need a strategy for determining an embedding from a multimodal document. In other words, which vector do we search on if both a caption and image are present? We end up following the CM3Leon work from Meta and simply average together all embeddings taken from a document to create a single embedding.
I’ll also note that CLIP embeddings are normalized by default when computed via the HuggingFace CLIPProcessor, and the embeddings present in the LAION dataset we downloaded are already normalized, so there is no need for us to run additional normalization before storing the embeddings.
import numpy as np
def merge_mm_embeddings(img_emb=None, text_emb=None):
if text_emb is not None and img_emb is not None:
return np.mean([img_emb, text_emb], axis=0)
elif text_emb is not None:
return text_emb
elif img_emb is not None:
return img_emb
else:
raise ValueError("Must specify one of `img_emb` or `text_emb`")Finally, we can ingest all of these image/text pairs into our vector store.
from tqdm import tqdm
def add_row_to_db(ndx: int):
# NOTE: These vectors have already been normalized
row = df.iloc[ndx]
img_emb = tmp_img[ndx]
text_emb = tmp_text[ndx]
emb = merge_mm_embeddings(img_emb, text_emb)
return table.put_async(
row_id=row["key"],
body_blob=row["caption"],
vector=emb,
metadata={
key: row[key]
for key in df.columns
if key not in ["key", "caption"]
},
)
all_futures = []
for ndx in tqdm(range(len(all_futures), len(df))):
all_futures.append(add_row_to_db(ndx))
for future in tqdm(all_futures):
future.result()Our vector store is now ready to query! Let’s move on to setting up the models.
Multimodal chat model
Here, we use MiniGPT-4, a compact open-source model based on Vicuna and CLIP that may not outshine ChatGPT Vision in terms of performance, but serves well for demonstrational purposes and for offering insights into potential applications. As multimodal models become more generally accessible (looking at you, ChatGPT Vision), you’ll be able to replace this step in the pipeline with a much more powerful model.
To start, we can clone a forked version of the MiniGPT-4 repo that is easier to configure, and download the necessary model weights we will use.
import os
import sys
from huggingface_hub import hf_hub_download
if not os.path.exists("MiniGPT-4-RAG-Demo"):
!git clone https://github.com/rsmith49/MiniGPT-4-RAG-Demo.git
sys.path.append("MiniGPT-4-RAG-Demo/")
# Download minigpt-4 weights for Vicuna-7B
hf_hub_download(
repo_id="Vision-CAIR/minigpt4",
filename="prerained_minigpt4_7b.pth",
repo_type="space",
local_dir="./",
)Now, we can initialize the model and get a chat session ready.
from minigpt4.common.config import Config
from minigpt4.common.dist_utils import get_rank
from minigpt4.common.registry import registry
from minigpt4.conversation.conversation import (
Chat as MiniGPT4Chat,
CONV_VISION_Vicuna0,
CONV_VISION_LLama2,
)
class TmpArgs:
options = None
cfg_path = "MiniGPT-4-RAG-DEMO/eval_configs/minigpt4_eval.yaml"
CONV_VISION = None
def init_chat() -> MiniGPT4Chat:
"""Initialize a basic chat session with MiniGPT-4
We make some quality of life changes and fit into the expected
infrastructure of the MiniGPT-4 repo in order to load the model for
inference locally
"""
global CONV_VISION
conv_dict = {'pretrain_vicuna0': CONV_VISION_Vicuna0,
'pretrain_llama2': CONV_VISION_LLama2}
print('Initializing Chat')
cfg = Config(TmpArgs())
model_config = cfg.model_cfg
# Config adjustments
# This enables loading the non-quantized model for better performance
model_config.low_resource = False
model_cls = registry.get_model_class(model_config.arch)
model = model_cls.from_config(model_config).to('cuda:0')
CONV_VISION = conv_dict[model_config.model_type]
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
vis_processor =
registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
chat = MiniGPT4Chat(model, vis_processor, device='cuda:0')
print('Initialization Finished')
return chatNow we can ask our multimodal model all kinds of questions about images!
chat = init_chat()
chat.upload_image("http://images.cocodataset.org/val2017/000000039769.jpg")
chat.query("What is this a picture of?")# Model Output
This appears to be a photograph of two cats lying on a pink blanket,
with two remote controls on the left and right sides of the image.
But of course, sometimes we can ask a question that the model does not have the right context to answer.
chat.reset()
chat.query("What does the Apache Cassandra logo look like?")# Model Output
The Apache Cassandra logo is a blue and white image that depicts a stylized
representation of the Cassandra database cluster in the form of a node. The node is represented by a circle with a blue background, while the Cassandra
logo is represented by the words "Apache Cassandra" in white letters. The Cassandra logo also includes an icon of a leaf, which represents data storage and retrieval in the Cassandra database.
I’ve included the Cassandra logo for comparison below.

Unfortunately, the model hallucinates, giving us a description of a completely fabricated logo. To combat this, we have to add the final component to our example: retrieval.
Extending the multimodal model with RAG
Let’s start by incorporating some images into the model’s context to help it out. This can be done via the RAG pattern. This pattern requires two things: a way to embed our query, and a way to use it to do a vector search on our vector store for similar documents. Here is where we’ll do some of the heavy lifting in implementing new behavior.
We’ll first initialize our multimodal embedding model, CLIP, and define a function to embed user queries.
import torch
from transformers import CLIPProcessor, CLIPModel
clip_model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda:0")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
def _embed(img_url: str | None, text: str | None) -> torch.Tensor:
"""Get an embedding based on an Img URL and/or Text"""
if img_url is None and text is None:
raise ValueError(f"Must specify one of img_url or text")
img_emb = None
text_emb = None
if img_url is not None:
image = img_from_url(img_url)
img_emb = clip_model.get_image_features(
clip_processor(text=None, images=image,
return_tensors="pt")["pixel_values"].to("cuda:0")
)[0].to("cpu").detach().numpy()
assert img_emb.shape == torch.Size([768])
if text is not None:
text_emb = clip_model.get_text_features(
clip_processor(text=[text], images=None, return_tensors="pt",
padding=False)["input_ids"].to("cuda:0")
)[0].to("cpu").detach().numpy()
assert text_emb.shape == torch.Size([768])
emb = merge_mm_embeddings(img_emb, text_emb)
return embNext, we’ll create a chat class that incorporates the most relevant image as context into the conversation. This class should contain methods for: querying our vectorstore to return relevant image contexts, storing new images in the vectorstore to expand our context dataset, and running the whole RAG pipeline by passing a query to the model and outputting its response. Let’s walk through these core methods one at a time.
from typing import Any, Dict, List
from uuid import uuid4
class RAGChat(Chat):
def __init__(
self,
*args: Any,
table: MetadataVectorCassandraTable | None = None,
**kwargs: Any,
):
super().__init__(*args, **kwargs)
if table is None:
table = mm_table
self.table = table
def query_vectorstore(
self,
text: str | None = None,
img_url: str | None = None,
**ann_kwargs,
) -> List[Dict[str, Any]]:
...
def embed_and_store_image(self, url: str, caption: str | None = None) -> int:
...
def query(self, text: str, debug: bool = True, **generate_kwargs) -> str:
...Our first step is to send a request to our vector store, and get back a list of relevant images that we can use as context for the model. This is relatively simple using the cassio package, as we can simply embed our query text and/or image, passing that embedding to the “metric_ann_search” method of our vectorstore, and return the ordered results.
def query_vectorstore(
self,
text: str | None = None,
img_url: str | None = None,
**ann_kwargs,
) -> List[Dict[str, Any]]:
emb = _embed(img_url=img_url, text=text)
results_gen = self.table.metric_ann_search(
vector=emb,
metric="cos",
**ann_kwargs,
)
return list(results_gen)Next, we need to be able to add new data to our vector store. Thankfully, we’ve already written logic that can embed a text/image pair. Using this, we simply pass that embedding along with a randomly generated row ID, the text caption, and the image URL to the “put” method of our vector store.
def embed_and_store_image(self, url: str, caption: str | None = None) ->
int:
row_kwargs = dict(
row_id=str(uuid4()),
body_blob=caption,
metadata={"url": url},
vector=_embed(img_url=url, text=caption),
)
self.table.put(**row_kwargs)
return row_kwargs["row_id"]Finally, we tie it all together. When a user submits a query, we want to first search our vectorstore for similar images, then add them as context to our multimodal chat model. Sometimes the images that are pointed to from our vector store might fail to be uploaded to the model (most often because the URL is no longer working), so we skip any images that fail to load. Once we’ve uploaded an image, we proceed as above and have the model generate the next turn in the conversation.
def query(self, text: str, debug=True, **generate_kwargs) -> str:
results = self.query_vectorstore(text=text, n=3)
if debug:
print("Search Results:", [
{
key: result[key]
for key in ["row_id", "body_blob", "distance"]
}
for result in results
])
print("-" * 80)
# Try all results in case links are broken or tokenization issues
for ndx, result in enumerate(results):
img_url = result["metadata"]["url"]
try:
self.upload_image(img_url)
if debug:
print(f"Successfully tokenized IMG {ndx}: {img_url}")
print("-" * 80)
break
except Exception as e:
print(f"Could not tokenize IMG {ndx}: {img_url}, got the
following error:")
print(e)
print("-" * 80)
return super().query(text, **generate_kwargs)Almost there! Now, let’s add our image of the Cassandra logo to the vector store, and try our query again.
rag_chat = RagChat()
rag_chat.embed_and_store_image(
url="https://i0.wp.com/blog.knoldus.com/wp-content/uploads/2018/08/cassandra.pn
g",
caption="Cassandra logo",
)
rag_chat.query("What does the Apache Cassandra logo look like?")# Model Output
The Apache Cassandra logo is a blue eye with long eyelashes and a white background. The eye is the symbol of the Cassandra database, which is a distributed NoSQL database that is designed to handle large amounts of data.
The eye also symbolizes the ability to see and understand the data that is stored in the database.
We did it! MiniGPT-4 can now give us a much more accurate description of the Cassandra logo, just because it has access to this data in its store. We can try some more queries; I noticed the subset of LAION that we uploaded contained a fair number of Pulp Fiction posters. Let’s see if MiniGPT-4 can give us some halloween costume ideas.
rag_chat.reset()
rag_chat.query("What are some outfits from Pulp Fiction?")# Model output
The outfits in Pulp Fiction are a mix of classic and modern styles. Some of the outfits include:
* John Travolta's character, Vincent Vega, wears a black suit and tie with a white shirt and black shoes.
* Samuel L. Jackson's character, Jules Winnfield, wears a black suit and tie with a white shirt and black shoes.
* Uma Thurman's character, Mia Wallace, wears a long, white dress with a black belt and high heels.
* Bruce Willis's character, Butch Coolidge, wears a black leather jacket and jeans.
These are just a few examples of the outfits in Pulp Fiction. The film is known for its iconic fashion and style.
The image chosen via vector search and used as context to the model is shown below. Pretty cool that the model can now use relevant data from our DB to answer questions!

Conclusion
While the ChatGPT Vision announcement heralded a new era in AI capabilities, the journey has just begun. The challenge now is to harness these capabilities effectively, reduce errors, and broaden applications. With tools like RAG in conjunction with multimodal inputs to models, we're well on our way to a future where AI doesn't just read or view, but holistically understands, offering insights and solutions that were previously deemed unattainable.
Imagine asking your AI assistant to find the best CPU to buy, and have it reference a chart of performance comparisons between leading brands to formulate its response. How much time would be saved by a chatbot that can leverage not just the text of research papers, but also the accompanying figures in answering your question? Multimodal models, especially in tandem with RAG, open so many new and exciting doors to the future. As developers, researchers, and AI enthusiasts, we stand at the precipice of this new frontier, ready to explore, innovate, and redefine the boundaries of what's possible.
Want to learn more? Join us at Cassandra Summit on December 12 and 13 in San Jose, Calif. Register now!






