

DataStax Enterprise 6.9, DataStax Hyper-Converged Database (HCD), and DataStax Astra DB combine the best of NoSQL and vector databases, powered by Apache Cassandra®. We provide the premier solution for modern generative AI applications that supports diverse data formats required by these apps. The growing popularity of GenAI is also driving the need for high-performance embedded retrieval included to enhance search, improve efficiency with accuracy, and enable better user experience with more natural language queries that support both semantic and contextual references.
To that end, the latest NVIDIA NeMo Retriever NIM inference microservices announced today by NVIDIA will come pre-installed as the default embedding service in Astra DB.
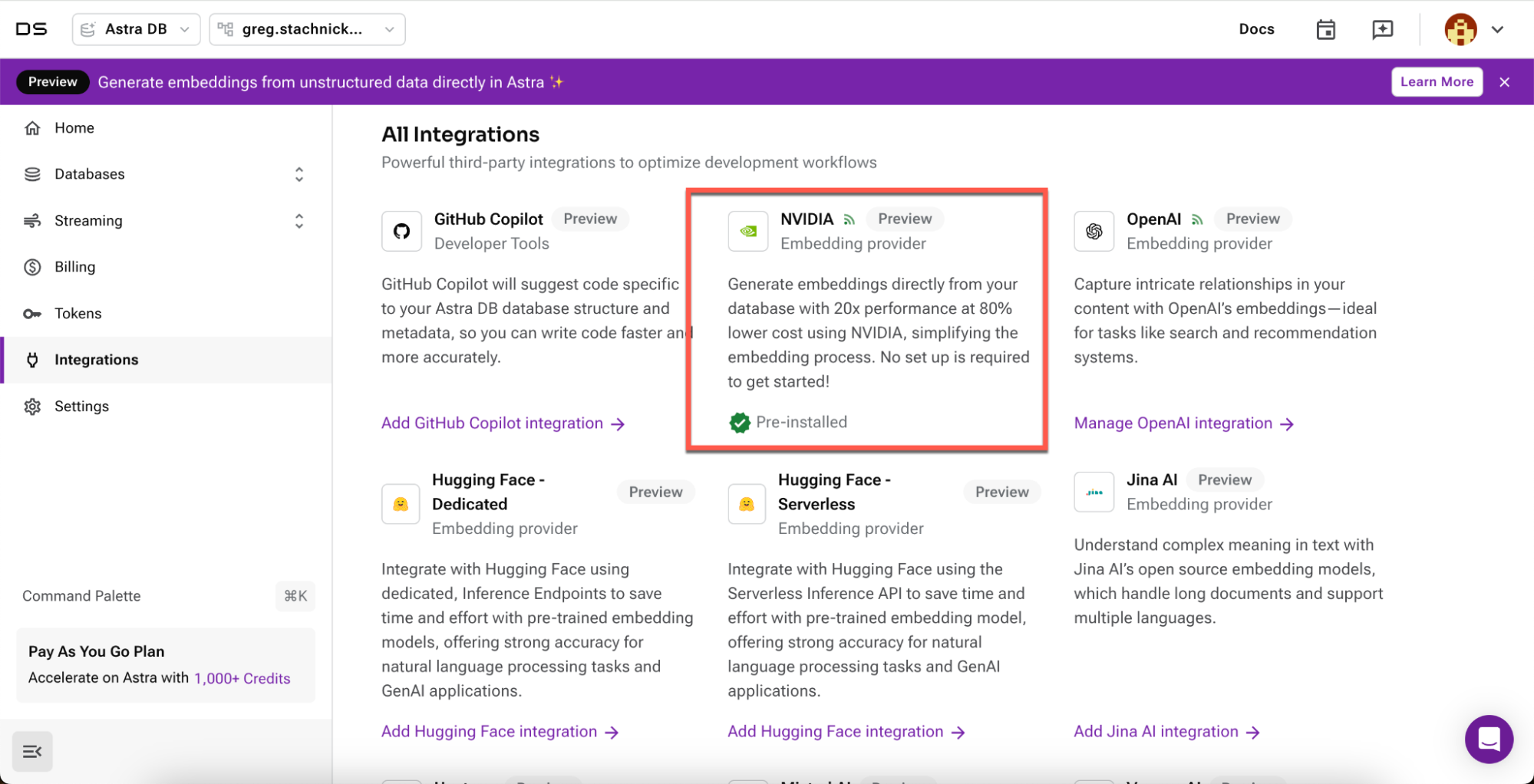
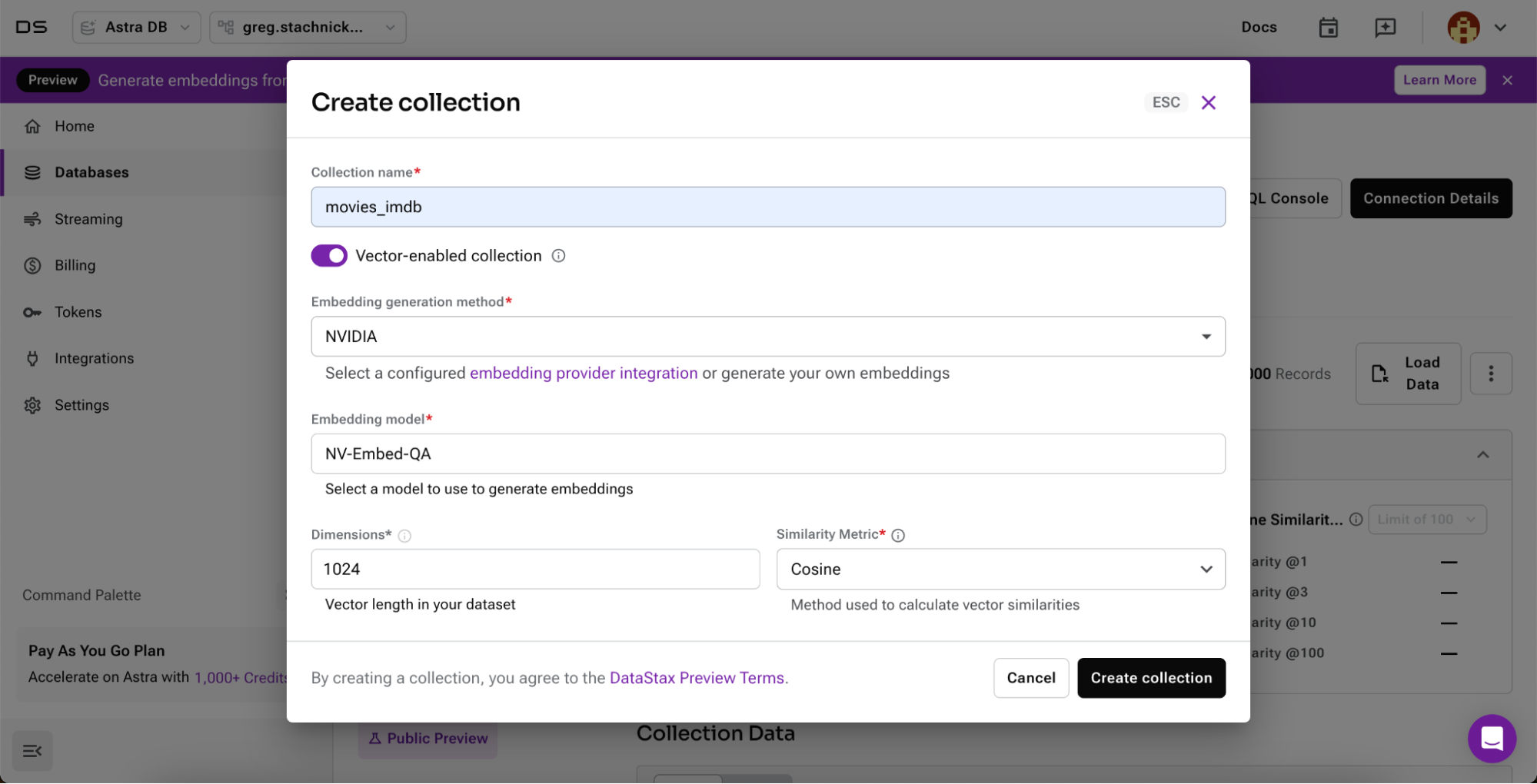
We recently launched Astra Vectorize in Astra DB, which simplifies embedding configuration and generation. By handling embedding generation directly at the database level, Astra Vectorize ensures your database not only stores but also intelligently indexes and searches your data. In addition to supporting external embedding providers, DataStax hosts the NeMo Retriever microservice within the Astra infrastructure and makes it available to AWS free-tier users. When users create a new collection, the embedded NeMo Retriever NIM will be selected by default. Anytime data is written to the database, embeddings will be automatically generated from NeMo Retriever.
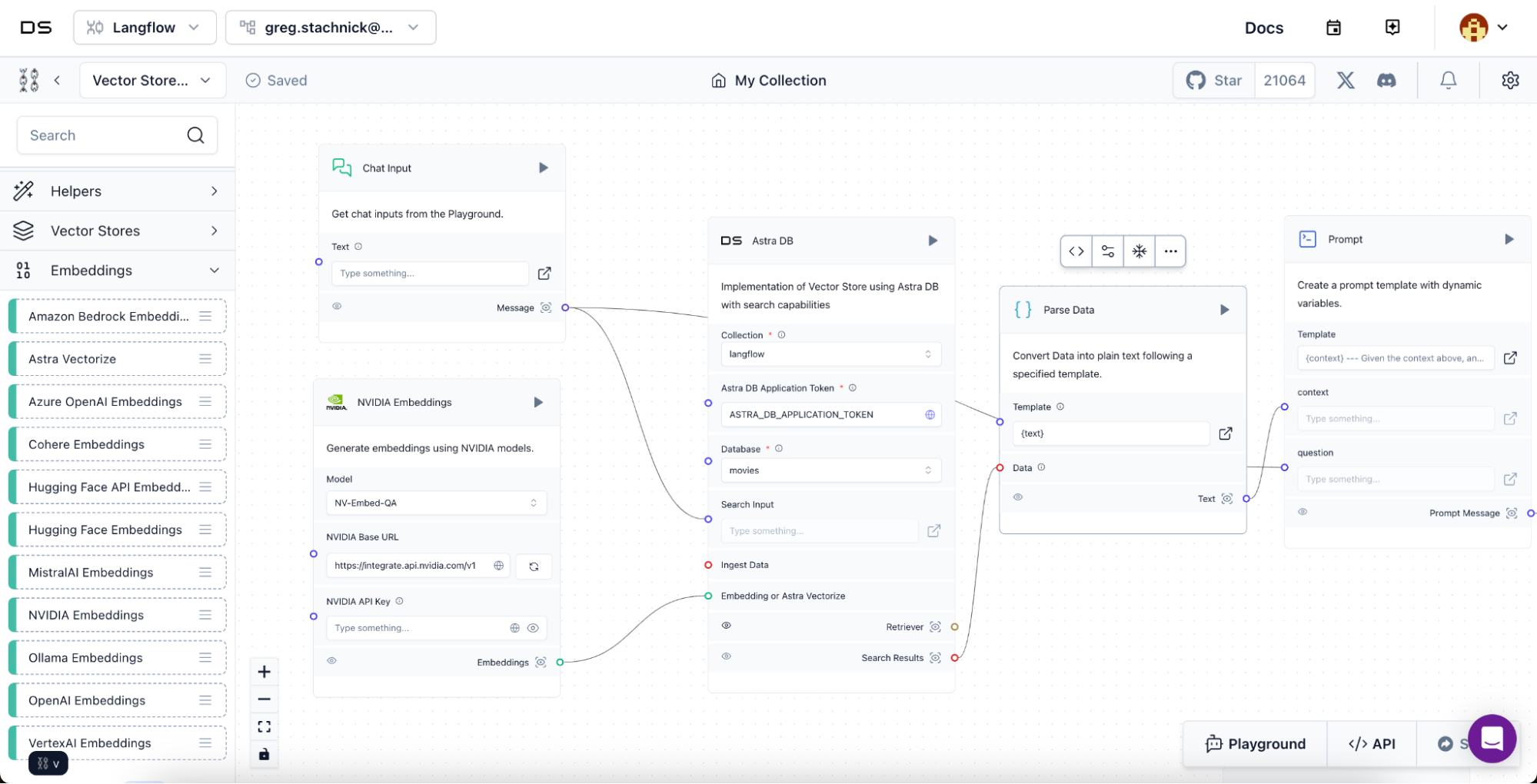
NeMo Retriever NIM embedding and reranking microservices are also available as embedding services in Langflow, our visual framework for building AI applications with multi-agent and retrieval-augmented generation (RAG) systems. The drag-and-drop interface for writing code allows users to visually connect different AI components and build complex workflows, using various AI building blocks, including language models, vector stores, and other AI tools.
We chose to integrate NeMo Retriever because it provides two key features:
- An embedding model to transform diverse data—such as text, images, charts, and video—into numerical vectors while capturing their meaning and nuance. Embedding models are fast and computationally less expensive than traditional LLMs.
- A reranking model that ingests data and a query, scores the data according to its relevance to the query, and trims results to include only the most relevant responses. Such models offer significant accuracy improvements while being computationally complex and slower than embedding models.
To understand the impact of performant RAG solutions, DataStax recently benchmarked the NVIDIA NV-Embed-QA vector embedding model (for generating vector embeddings) and the DataStax Astra DB Vector database (for storing and managing vectors at scale). DataStax ran the test harness (Open Source NoSQLBench) on the same machine as the model, deployed on Docker containers. The performance tests measured the following four key metrics:
- Embedding latency - Time to generate an embedding
- Indexing / query latency - Time to store / query the generated embedding
- Overall throughput - Number of processed inputs through the system per second
- Cost - Hardware and software cost to process tokens
DataStax ran the benchmarks on a single NVIDIA A100 Tensor Core GPU, which demonstrated increased performance from ~181 ops/second to almost 400 ops/sec. Tuning NVIDIA TensorRT software with a tokenization/preprocessing model improved performance by another 25%. We then switched to the NVIDIA H100 80GB Tensor Core GPU (a single a3-highgpu-8g instance running on Google Cloud), which resulted in throughput doubling to 800+ ops/sec.
We also looked at configurations that lowered the latency, and found that it’s possible to achieve ~365 ops/sec at a ~11.9 millisecond average embedding + indexing time, which is 19x faster than popular cloud embedding models + vector databases.
Today, the Astra DB vector database uses DiskANN to process 4,000 inserts per second and make them immediately searchable. While this keeps the data fresh, the tradeoff is reduced efficiency. DataStax is working with NVIDIA to accelerate vector search algorithms by integrating RAPIDS cuVS to improve efficiency and maintain data freshness.
When combined with NVIDIA NIM and NeMo Retriever microservices, Astra DB, DataStax Enterprise (DataStax’s on-premises solution), and DataStax HCD provide a fast vector DB RAG solution that’s built on a scalable NoSQL database that can run on any storage medium. Out-of-the-box integration with Astra DB and Langflow makes it easy for developers to replace their existing embedding model with NIM. We’ve also integrated and performance-tested NVIDIA NeMo Guardrails into its platform and shown that fast RAG applications need not come at the expense of safety.
To get started, sign up for Astra DB to try out simplified embeddings powered by NVIDIA NeMo Retriever.









