

Thoughts on polyglot persistence, multi-model databases, and how to make sense of it all.
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
This is the fourth article a series in which I’m answering questions that I received from a reader of of my book Cassandra: The Definitive Guide, 2nd Edition (O’Reilly), who is interested in how the hotel data model presented in the book would work in practice.
Previously we’ve discussed how to navigate relationships between different data types, how to maintain unique identity of data over time, and how to reconcile your data model with your architecture. That last article is particularly relevant to our discussion here, so I’d encourage you to read that first if you haven’t already.
One of the questions my reader asked is whether some portions of the data model in the book would be appropriate to store in an other kind of database — for example, storing mappings of hotel names to IDs in a key-value store:
A sample key like AZ123 (presented in Chapter 9) would be hard to know ‘by heart’. Would you use a separate Key/value store to manage those ID’s and the hotel names?
This is really a question about polyglot persistence and multi-model approaches. Let’s dig into these topics a bit and see what we can discover.
Old School Application Design
Before we talk about polyglot persistence and multi-model though, let’s first take a quick trip in the wayback machine.
Consider how most backend applications were developed even just a few years ago. As you see in the figure below, the classic architecture approach was to build a single monolithic application (or “server”), interfacing with a single relational database containing multiple tables. Of course there were occasional other storage mechanisms used, such as file-based storage, but this was the basic paradigm.
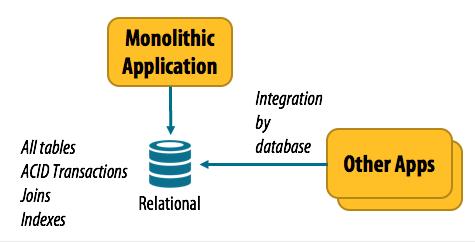
Monolithic applications experience the strengths and weaknesses of RDBMSs
The great thing about this approach was that you could have all your data in one place, and even have transactions with ACID semantics spanning multiple tables. You could add any indexes you wanted to speed up queries, and you could perform complex joins across tables.
These databases worked so well that sometimes we were even tempted to use them as the interface between systems. This “integration by database” came to be considered an anti-pattern as we realized how brittle these integrations were — usually when we updated an application database only to find that it broke other apps.
This application architecture served us well for many years, and is still appropriate for some applications. The problem is that it just doesn’t work for cloud-scale distributed applications.
Cloud Architecture, NoSQL and Microservices
The recognition of the scalability challenges of the classic monolithic architecture approach led to the rise of new approaches for architecting cloud-based systems. At the data tier, this led to the creation of Apache Cassandra® and other NoSQL databases. Rather than delving too far into the history here, I’ll refer you to Chapter 1 of the book for a brilliant analysis of these developments from my co-author Eben Hewitt.
Along with the emergence of new databases came the introduction (or revival) of multiple different models. Document, key-value, column oriented, and even graph databases started to emerge, and we as architects and developers began to take advantage of these new models.
At the same time, the Service-Oriented architecture trend of the early 2000s matured into the microservice architectural style, as we began to move away from the powerful but heavyweight infrastructure such as the Enterprise Service Bus.
The microservice architecture approach has become very popular for building cloud-based applications, and for good reason. The ability to develop, manage and scale services independently gives us a ton of flexibility in terms of implementation choices, infrastructure technology and horizontal scalability.
Polyglot Persistence
One key benefit of the microservice style is the encapsulation of persistence. We are free to select a different persistence technology according to the needs of each service. The approach of selecting data stores according to the characteristics of each data type is known as polyglot persistence, as popularized by Martin Fowler. Polyglot persistence is a natural fit for microservices.
The figure shows a example of a set of microservices and how we might approach selecting a different model for each service. Note that I’m not trying to enumerate all of the appropriate use cases for each type of database could be appropriate. My intent is to highlight the strengths of each of these type of database and why the polyglot approach can be attractive.
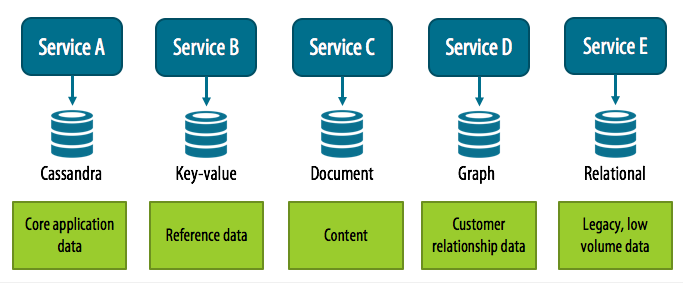
Polyglot persistence applied to a microservice application
For example, the team developing Service A might choose to use Cassandra because it is managing core application data at large scale. For example, inventory data for a retail application might be a very good fit for Cassandra’s tabular format.
Perhaps Service B supports very simple semantics of looking up reference values by well known keys. For example, descriptive data for a product catalog.
Another Service C might be primarily concerned with serving up content for a website and a document store could be a great fit for that data.
Service D might be all about navigating complex relationships between data such as customer data and the history of their contacts with various departments in the organization.
Finally, we might also have a legacy system or services that use relational technology, or perhaps we have a service that manages a lower volume of data, or data that doesn’t change often. A relational database might be adequate for those cases.
Should an Individual Service be Polyglot?
It’s also possible that we could design a service that actually sits on top of multiple databases. To extrapolate a bit from my reader’s question, we could create a Hotel Service that used a key-value store as an index, mapping between hotel names and IDs, while storing the descriptive data about a hotel in Cassandra’s tabular format.
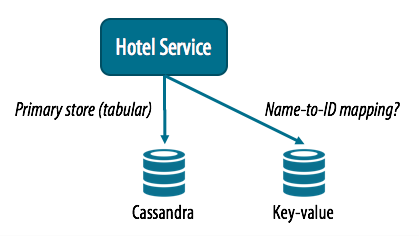
A polyglot service?
In my opinion, the name-to-ID mapping could be accomplished equally well within Cassandra, without the complexity of managing a separate KV store.
In fact, this is my typical recommendation — that a given microservice stick to a single database where feasible. If you find a situation in which you feel that a single service needs to sit on top of two different databases, consider whether the scope of that service might be getting too large. You might want to consider splitting that service into smaller services.
Limitations of Polyglot Persistence
The main drawback of polyglot persistence is the cost of supporting multiple technologies, both in terms of initial development and operations.
The primary development cost is the cost of training up developers on each new database technology. This can be significant, especially if you are in a more fluid environment where developers change teams frequently.
The other driver is the operational cost of supporting multiple databases. This can be a problem when database management is centralized and that team must maintain a high level of competence in multiple technologies, but it may be less of a problem in a true DevOps shop where development teams have to support the databases they select in production.
The Multi-Model Database
Database vendors have recently begun to build and promote multi-model databases as an alternative or complement to the polyglot persistence approach. The term “model” references the primary abstraction provided by a data store, such as tabular (both relational and non-relational), column store, key-value, document, or graph. We can think of a multi-model application as one that uses more than one type of data store, while a multi-model database is one that supports more than one abstraction.
A Multi-Model Example
DataStax Enterprise is an example of a multi-model database, since at it’s core it supports Cassandra’s partitioned row store (tabular) model, with a graph abstraction built on top of that (DSE Graph). It’s also simple to build your own key-value and document style abstractions on top of the core model, as shown in the figure below. In this way, we could modify the polyglot approach shown above to leverage a single underlying database engine for all of our services.
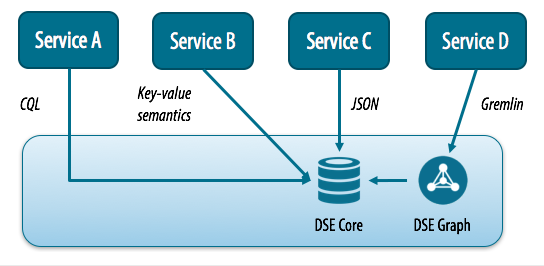
Interacting with DataStax Enterprise as a Multi-Model Database
Here’s how it would work:
- Tabular: our primary application services like Service A could interact with the DSE Core directly using the Cassandra Query Language (CQL).
- Key-value: Although neither the Apache nor DataStax distributions of Cassandra provide an explicit key-value API, services like Service B can interact with Cassandra as a key value store by constraining the table design to only support key and value columns. For example:
CREATE TABLE hotel.hotels (
key uuid PRIMARY KEY,
value text); // or if you prefer, “blob”
- Document: Cassandra supports document-style interaction in terms of JSON documents, which could be used by services like Service C. Note that because Cassandra does require a schema for tables, you can’t insert arbitrary JSON that defines new columns on the fly, which is a characteristic that one might typically associate with document databases.
- Graph: For services that support highly interconnected data like Service D, DSE Graph is a highly scalable graph database that is built directly on top of DSE Core Cassandra. DSE Graph supports the powerful and expressive Gremlin API from Apache TinkerPop. I plan to delve into this API in more detail in a future series.
The Multi-Model Value Proposition
In considering whether to invest in a multi-model database (or use multi-model features of a database you already have in place), you’ll want to consider the same development and operational costs we discussed above regarding the polyglot persistence approach.
Using a multi-model database can help with operational simplicity. Even if different development teams are using different APIs and modes of interaction with the backend database platform, we gain efficiency by only having a single platform to manage.
The main thing to keep in mind in selecting which multi-model database to use is that each database will typically have a single native underlying model, with other models layered on top of that. The layered data models are likely to exhibit characteristics of that underlying primary model.
For example, the latest ThoughtWorks Technology Radar (Vol. 16) highlights the characteristics that DSE Graph demonstrates as a graph model layered on top of Cassandra, and the tradeoffs involved:
Built on top of Cassandra, DSE Graph targets the type of large data sets where our longtime favorite Neo4j begins to show some limitations. This scale has its trade-offs; for example, you lose the ACID transactions and run-time schema-free nature of Neo4j, but access to the underlying Cassandra tables, the integration of Spark for analytical workloads, and the powerful TinkerPop/Gremlin query language make this an option worth considering.
In my experience, I’ve found that eventual consistency is sufficient for the vast majority of data in cloud applications. The quote highlights another important consideration in the multi-model space — the integration and interaction between the different models and engines. For example, DSE supports the ability to accessing graph data via Spark (DSE Analytics) for analytic purposes. There is a lot more we could discuss here, and I plan to do that in future articles.
Making your move
Now that we’ve considered the merits of polyglot and multi-model approaches, how should we go about deciding on an approach for large scale cloud applications. Here’s the approach I favor:
- Use a microservice architecture, giving each service control over its own persistence. Where possible, leverage a multi-model database for all services, allowing services to vary in what model they choose to interact with data. Use Cassandra (i.e. DSE Core) as your primary model for cloud-level scalability and availability, layering key-value and document semantics on top of this as needed
- Use a graph database (i.e. DSE Graph) for highly relational data, especially in cases where the relationships between entities have as many or more attributes than the entities themselves, or you need to capture multiple relationships between the same entities.
- Preserve legacy investments in relational/SQL technology when you don’t have to make a change. For example, when your use case doesn’t require large scale, low latency, and high availability at the same time.
- Hopefully this gives you a good framework to think about how and where to support multiple models in your application.
In upcoming articles, we’ll look at techniques for extending your data models to support additional queries, and how to make sure your data models support high performance at scale.
In upcoming articles, we’ll look at techniques for extending your data models to support additional queries, and how to make sure your data models support high performance at scale.








