

Where do data modeling and architecture converge?
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
n this series of articles, I’m answering a series of questions that I received from a reader of of my book Cassandra: The Definitive Guide, 2nd Edition(O’Reilly), who asked several questions about how the hotel data model presented in the book would work in practice. Previously we’ve discussed how to navigate relationships between different data types and how to maintain unique identity of data over time.
In this article, we’ll look at the relationship between data modeling and architecture. I’ve often heard questions like:
“Which comes first? Should the data model drive the architecture, or vice versa?”
In my view, data modeling and architecture are two vital elements of the development of an application, and neither should dominate the other. It’s like the confluence of two rivers. At the first point of contact, the domains appear distinct, but as you look downstream they begin to blend and flow together, and the end result is a single unified whole. That’s the ideal we’re looking for in this relationship.
The proper relationship of data modeling and architecture
In my experience, data modeling is sometimes treated as an independent activity from architecting. The training materials I’ve seen for Cassandra data modeling tend to reinforce this pattern, focusing only on development of schema without regard to the underlying architecture. While you could certainly argue that this brings a proper focus to the training, try taking that same approach in your application development. You’ll most likely be left with an awkward mapping exercise.
As you can probably guess, I believe developing architecture and data modeling independently is a mistake. Whenever possible, I recommend developing data models and architecture iteratively, as we’ll discuss below.
Start data modeling from scratch
This is true even in cases where there are existing systems to which you are interfacing, which have their own views of the data that your application will need to take into account. You can always check your data models against those other data models later.
This approach may allow you to set aside assumptions about your domain that will overly constrain your design. Take the hotel domain model from the book, for instance. If we’ve been working in that domain for a while, we might assume that the inventory that should be tracked is the rooms that people sleep in. If I start my domain models with a clean slate, I can ask questions like — how would my model account for reserving meeting rooms at the hotel?
As it turns out, the hotel entity-relationship diagram from the book demonstrates the idea of just representing “rooms”. That was not an accident. The room entity could even be generalized further to “reservable spaces” or perhaps “products”.
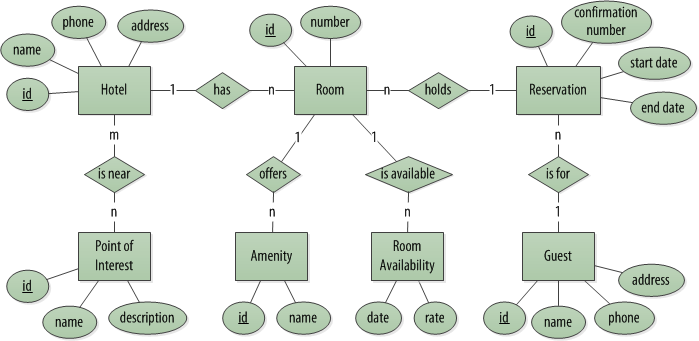
Entity-relationship diagram for a hotel application with a generalized “room” concept
Set your architecture strategy aside (for a moment)
know we often have an architectural approach in mind before we start new application work, whether we’re intending to build a monolith (hopefully just as a proof of concept, amirite?) or a set of microservices. We need to set that approach aside for a little while and let the data model come to the forefront for a bit. Don’t worry, we’ll get back to it soon enough.
Developing data modeling and architecture together
So, the time has come to test out my assertion that data modeling and architecture should be done together in an iterative style. Let’s look at one example of how this might work.
Domain-driven design (DDD) and bounded contexts
You may have heard quite a bit of talk over the past couple of years about Domain Driven Design (DDD) and its relevance to the microservices movement. Following the principles of DDD as articulated by Eric Evans in his excellent book on the topic, I’ve taken the hotel logical data model from the book and started identifying bounded contexts by drawing blue boxes around them. As I’m doing this, I’m looking for high cohesion within a context and low coupling with other contexts.
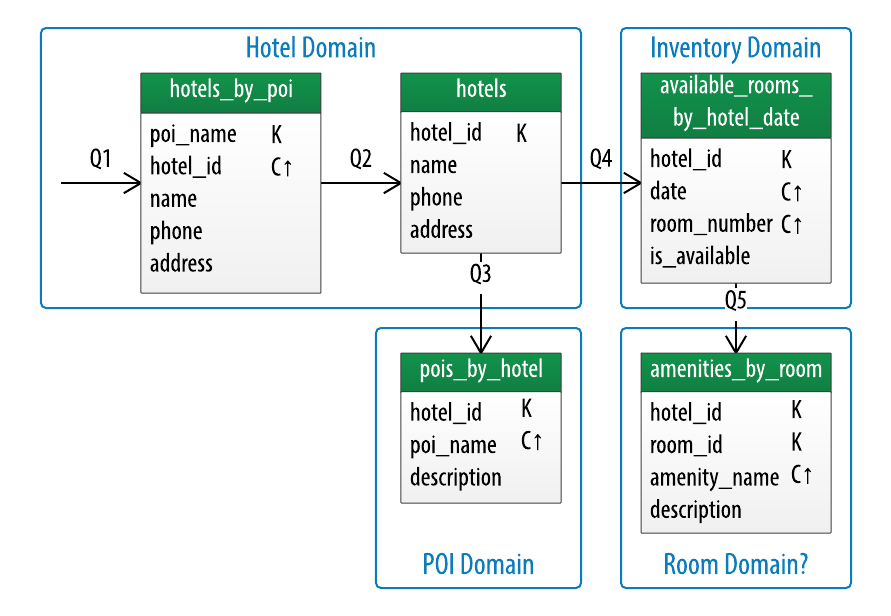
Logical data model for a hotel application with candidate bounded contexts
As you can see, I’ve identified a “hotel” domain, a “POI” domain, an “inventory” domain, and a candidate “room” domain.
This idea of a “room” domain feels a bit questionable to me because it’s data that has a lot of cohesion with the hotel data. Both hotel and room data are relatively static and descriptive. However, they are needed at different times, according to the access patterns defined for our application. We’ll defer a decision on this until later.
As I mentioned above, we’re looking for low coupling between contexts. In the case of this model, the coupling is quite low — although there are references between types across context boundaries, they are all just identifiers.
Although identifying bounded contexts was a straightforward exercise in this particular case, I definitely don’t want to oversimplify this step of the process. You may encounter cases where the information overlap between two bounded contexts is more complex than just ID references. I’d recommend you have a look at this excellent presentation from Eric Evans on using DDD to drive microservice design, especially how to manage what he calls “interchange contexts”. These may result in new types specific to the interface between two contexts, which could drive additional content into our data models.
Using bounded contexts for microservice identification
Now, let’s take those candidate bounded contexts use them to refine our physical data model. For example, looking at the hotel physical data model from the book, I’ll regroup the tables according to the services that I’m proposing to assign as their owners:
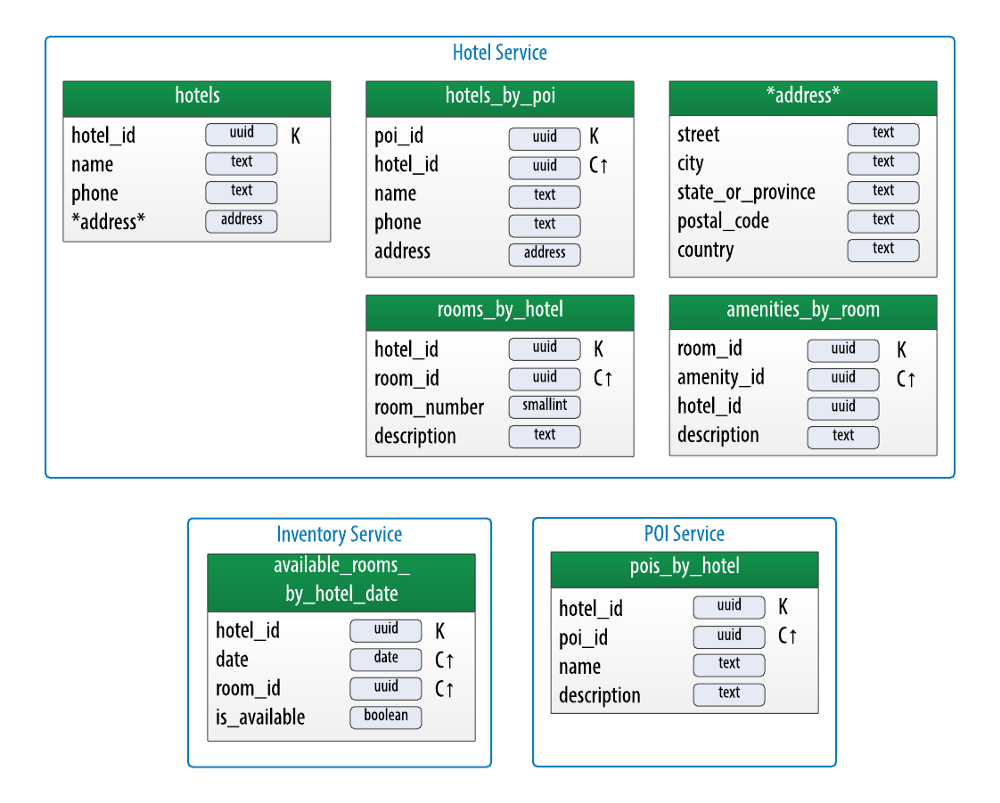
Physical data model for a hotel application, organized by microservices
As you can see, the bounded contexts we identified above are strong indicators of service boundaries. For example, the hotel domain from above leads directly to having a Hotel Service, the inventory domain to an Inventory Service, and so on.
You will also notice that I’ve decided to collapse the room elements into the hotel service, rather than having a separate Room Service (pun acknowledged, but not intended). My reasoning in this case is that room data and hotel data share the same lifecycle from a data maintenance perspective. That is to say, our application will generally be updating room data and hotel data at the same time
Don’t be alarmed if the process of identifying bounded contexts or services causes rework to your data models. That’s the whole purpose of this feedback loop — to inject that dose of reality that allows you to arrive at the best design.
Microservices in context
To close out our architecture development, let’s look at how the services identified above map into a larger architecture:
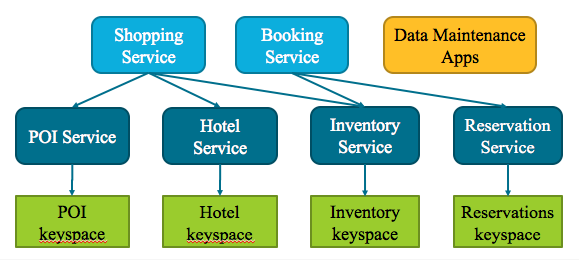
Notional microservice architecture for a hotel application
The services we identified are primarily concerned with managing data, so we’ll give them each control over their own data storage by putting their tables in separate keyspaces.
I’ve included a Reservation Service corresponding to the other portions of the data model presented in the book. We’ll layer some additional services on top of our data-focused services to orchestrate business processes like shopping and booking hotel rooms. Note how our lower level services are reused as part of these business processes. We might also add a web application to allow the hotels to perform data maintenance.
This separation between data-focused and business process focused services is not an innovation, it’s a classic SOA technique. It’s also not the only way to approach microservice architecture, but it is definitely a technique that has worked well for me in multiple systems. You can find more on this approach in my session from last year’s Strata conference in NYC:
Putting it all together
Here’s a way of summarizing what we just did as a repeatable process. I’m not trying to describe a complete architecture process or reintroduce the classic waterfall stages of high-level design and detailed design. I’m just trying to highlight where architecture might come into play in our data modeling.

Candidate process for blending architecture and data modeling
Here are the highlights of how we work architecture into our data modeling process:
- Typically, we’ve already selected an overall architectural strategy for the application based on the context of the problem we’re trying to solve — for example, microservice style.
- We introduce the DDD approach of identifying bounded contexts as a feedback loop into our logical data modeling process
- When we create our physical data model, the bounded contexts become candidate microservices. We assign ownership of key data types to each microservice. We identify other microservices that help implement business processes by orchestrating the underlying data-focused services .
- As we design and implement each microservice, we can make independent decisions about how it persists data. In the next article, we’ll discuss this polyglot persistence approach in more detail.
Hopefully this article has given you some food for thought that will help you as you consider the various data types in your domain and how they relate to your underlying architecture.








