

Extracting knowledge graphs using a large language model (LLM) is time-consuming and error-prone. These difficulties arise because the LLM is being asked to extract fine-grained, entity-specific information from the content. Inspired by the benefits of vector search, especially the ability to get good results from ingesting content with relatively little cleaning, let’s explore a coarse-grained knowledge graph – the content knowledge graph – focused on the relationships between content.
If you want to jump right in, you can also check out the this notebook.
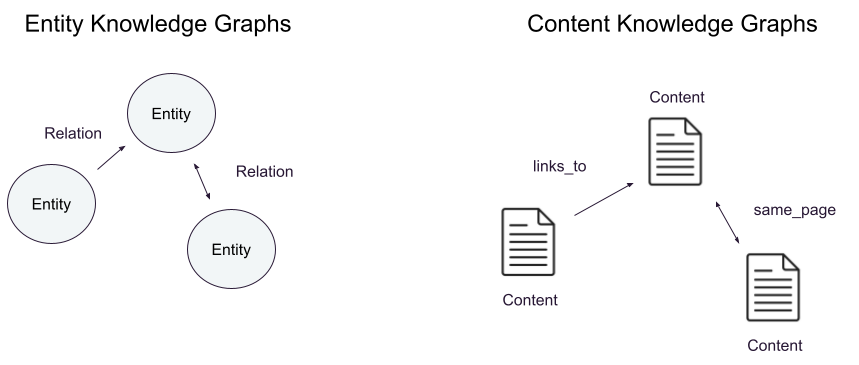
Entity-centric knowledge graphs
Historically, knowledge graphs have had nodes represent specific concepts (or entities) and edges represent specific relationships between those concepts. For example, a knowledge graph built with information about me and my employer might look something like the following:
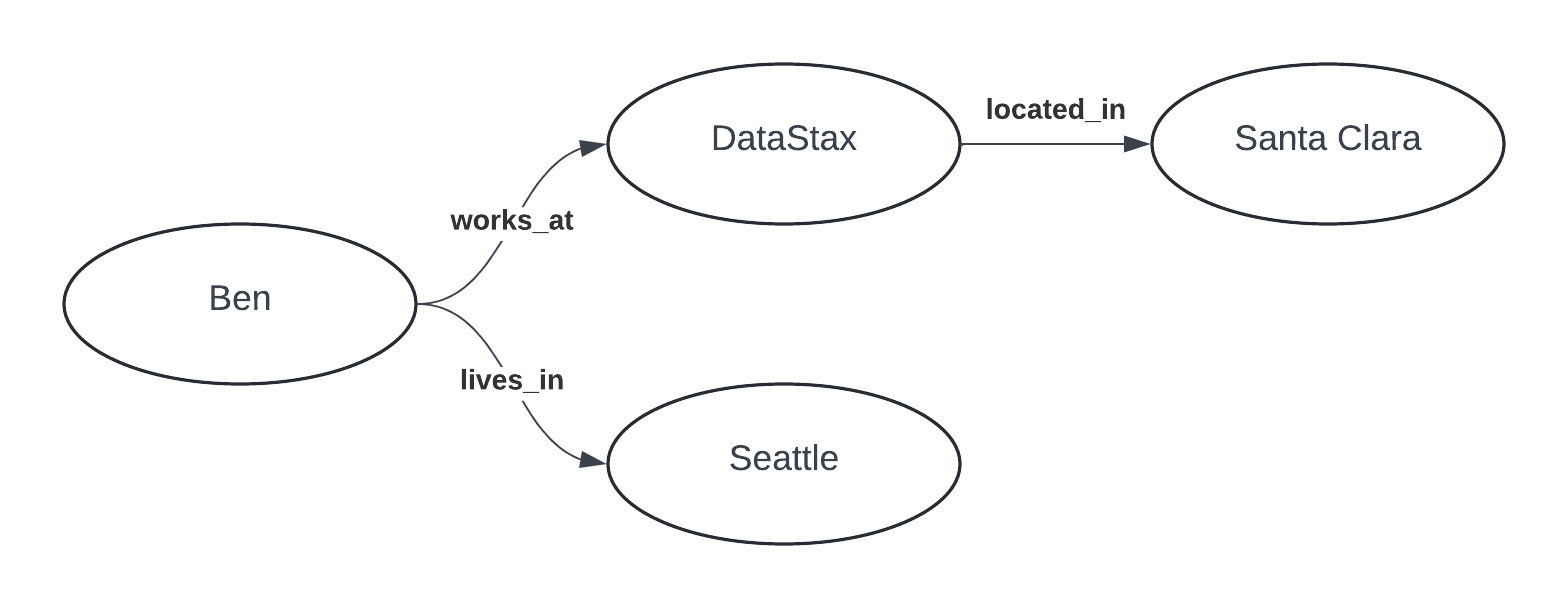
This fine-grained, entity-centric knowledge graph allows for a variety of queries to be expressed using a graph query language like Cypher or Gremlin. Recently, knowledge graphs have become popular as an alternative way to store and retrieve information for consumption by an LLM as part of advanced retrieval augmented generation (RAG) techniques. The ideas are compelling: The knowledge graph captures relationships between information that vector similarity search would miss, and LLMs make it possible to extract knowledge graph triples (source, relationship, target) from unstructured content with only a prompt. This is why this historic concept seems relevant to so many.
However, extracting this fine-grained knowledge graph from unstructured information is difficult, time-consuming and error-prone. To get the best results, you (and a domain expert) will need to:
-
process all of your unstructured content with the LLM to extract information,
-
guide the LLM on the kinds of nodes and relationships you wish to extract by creating a “knowledge schema” (or ontology),
-
inspect the graph of extracted information to make sure the LLM is extracting the correct details, and
-
reprocess all the content when you change the knowledge schema.
Between the need for human experts and applying the LLM to all of the content, the cost of building and maintaining this graph is high. Bottom line: There’s a reason that most examples of using knowledge graphs for RAG operate on just a few sentences or paragraphs.
Using entity-centric knowledge graphs is much harder to scale and to get good results from than just chunking the content and dumping it into a vector store. Is there any way we could bring the benefits of vector search to knowledge graphs – specifically, making construction as easy as chunking and embedding the content while also preserving the original content until the LLM knows the question to be answered?
Content-centric knowledge graphs
If we start with nodes representing content (chunks of text, for example) instead of fine-grained concepts or entities, the nodes of the graph are exactly what is stored when using vector search. Nodes may represent a specific text passage, an image or table, a section of a document or other information. These represent the original content, allowing the LLM to do what it does best: process the context and pick out the important information. When building the fine-grained graph, this happens before the question is known, forcing speculation and/or human guidance on which facts matter.
In fact, this is part of why we believe these content-centric knowledge graphs are better: LLMs excel at processing large amounts of context, and doing so when they know the question enables them to find the most useful needles in the haystack. Entity-centric knowledge graphs require reducing the information to the simple annotations on edges, making them less useful as context to LLMs.
Edges between nodes represent a variety of structural, semantic and metadata-based properties. For instance, a chunk containing a hyperlink could have a `links_to` edge pointing at the linked content. Or two chunks with common keywords might have an edge indicating the similar content `has_keywords: [...]`. A text passage may link to an image or table in the same section that it references or passages in a document could link to definitions of key terms.
Starting from three documents about Ben and DataStax, a coarse-grained graph similar to the previous example might be:
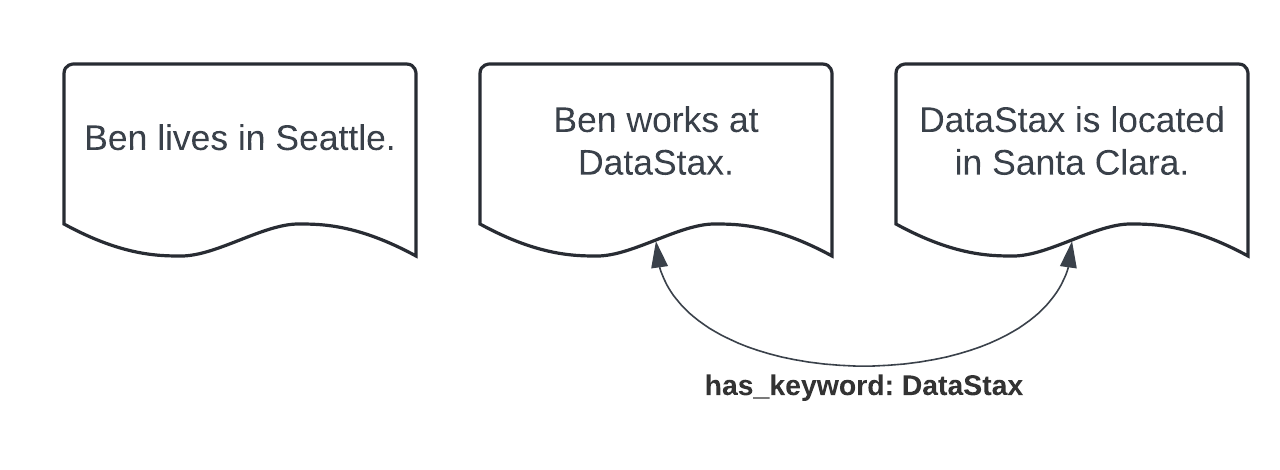
Since the nodes are chunks of documents, the graph wouldn’t change if the article on DataStax had more information, such as when it was founded. With the fine-grained approach, we would need to decide whether that extra information should be extracted.
The main benefits of this approach compared to fine-grained knowledge graphs are:
-
Lossless — The original content is preserved within the nodes, meaning no information is discarded (not extracted) during the creation process. This reduces the need to re-index information as your needs change and allows the LLM to do what it does best: extract answers from that context based on the question.
-
Hands-off — No experts necessary to tune the knowledge extraction. You add some edge extraction based on keywords, hyperlinks or other properties of the data to your existing vector-search pipeline, and then links are automatically added.
-
Scalable — The creation process can be implemented using simple operations on the content, with no need to invoke an LLM to create the knowledge graph.
Creation
Unlike a fine-grained graph, the process to create these coarse-grained graphs is far simpler. No domain expert is needed. Instead, the content is loaded, chunked and written to the store. Each of the chunks can be run through a variety of analyses to identify links. For instance, links in the content may turn into `links_to` edges and keywords may be extracted from the chunk to link up with other chunks on the same topic.
We make use of several techniques for adding edges. Each chunk may be annotated with URLs that it represents, as well as HREFs that it references. This allows capturing explicit links between content, as well as representing cases such as a document linking to a definition within the same page through the use of fragments. Additionally, each chunk may be associated with keywords, and all chunks with a given keyword will be linked together.
More techniques for linking are being developed, including automatic links based on properties of the chunks as well as using structural properties such as locations on the page.
Retrieval
Retrieval on these coarse-grained graphs combines the benefits of vector search and knowledge graph traversal. Starting points can be identified based on similarity to the question and then additional chunks selected by following edges, with a bound on how deep (distance from vector search nodes) to traverse.

Including nodes that are related via both embedding distance (similarity) and graph distance (related) leads to a more diverse set of chunks. Many of the edges in the graph will lead to information that deepens the context without being directly relevant to the question. These relationships allow expanding the context or limiting the context to “nearby” content. This additional related information improves the quality of answers and reduces hallucinations.
Case Study: Astra support articles
We loaded 1,272 documents from the DataStax Astra DB support site and some external pages linked from them. This took less than five minutes to scrape, parse the HTML, extract hyperlinks, convert the content to markdown and write resulting documents to the Astra DB store.
This required almost no work on my part beyond basic data cleaning and a few lines to populate metadata describing the links. Specifically, I didn’t look at the data or try to create a knowledge schema (ontology) capturing the information I wished to extract. This is important, because I’m not sure what parts of the 1,272 documents would be useful for the questions that may be asked.
I could have reduced the code by using more of LangChain’s built-in document loading functionality, but it had problems because it wanted to load all the pages into memory before writing them out, so I had to manage the iteration myself.
For the content-centric graph, we'll use the GraphStore class available as part of ragstack-ai-langchain. The package ragstack-ai-knowledge-store also needs to be installed.
import cassio
from langchain_openai import OpenAIEmbeddings
from ragstack_langchain.graph_store import CassandraGraphStore
# Initialize AstraDB connection
cassio.init(auto=True)
# Create embeddings
embeddings = OpenAIEmbeddings()
# Create knowledge store
graph_store = CassandraGraphStore(embeddings)
...
# Add documents to knowledge store
graph_store.add_documents(docs)While you can set the metadata for links yourself, there are also convenient utilities for doing so automatically. For our purposes, we wish to do the following to each HTML document:
-
Use a CSS selector based on the source URL to locate the content (such as exclude the navigation, etc. from the chunk and links)
-
Extract links from the HTML content
-
Convert the HTML content to markdown
While LangChain Document Transformers provide parts of this, they aren’t easily composable, so we just write some code to clean the HTML:
from markdownify import MarkdownConverter
from ragstack_langchain.graph_store.extractors import HtmlLinkEdgeExtractor
markdown_converter = MarkdownConverter(heading_style="ATX")
html_link_extractor = HtmlLinkEdgeExtractor()
def convert_html(html: Document) -> Document:
url = html.metadata["source"]
# Use the URL as the content ID.
html.metadata[CONTENT_ID] = url
# Apply the selectors while loading. This reduces the size of
# the document as early as possible for reduced memory usage.
soup = BeautifulSoup(html.page_content, "html.parser")
content = select_content(soup, url)
# Extract HTML links from the content.
html_link_extractor.extract_one(html, content)
# Convert the content to markdown
html.page_content = markdown_converter.convert_soup(content)
return htmlAgain, because the knowledge graph implements the vector store interface, it’s easy to create a retriever and use it in a LangChain expression:
# Depth 0 doesn't traverse edges and is equivalent to vector similarity only.
retriever = graph_store.as_retriever(search_kwargs={"depth": 0})
def format_docs(docs):
formatted = "\n\n".join(f"From {doc.metadata['content_id']}: {doc.page_content}" for doc in docs)
return formatted
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)Question
The question I used in all the examples is a relatively simple one about how Astra DB implements vector indexing.
"What vector indexing algorithms does Astra use?"
The answer to this question requires reading multiple parts of the documentation and connecting that with information available on externally linked sites.
Vector only

The answer is relatively shallow – just talking about how the library used to implement vector search (JVector). This answer is correct, but it doesn’t include any details about the algorithms that Astra DB uses or how it actually works.
If we look at the pages retrieved to answer the question – those with the highest similarity to the question – we see that it didn’t get to any of the deeper documentation:
-
https://docs.datastax.com/en/astra-db-serverless/get-started/concepts.html
-
https://docs.datastax.com/en/cql/astra/getting-started/vector-search-quickstart.html
-
https://docs.datastax.com/en/astra-db-serverless/databases/embedding-generation.html
-
https://docs.datastax.com/en/astra-db-serverless/get-started/astra-db-introduction.html
Depth 1 traversal
Changing the retriever to perform traversal is easy and gives us better results.
# Depth 1 does vector similarity and then traverses 1 level of edges.
retriever = knowledge_store.as_retriever(search_kwargs={"depth": 1})
The answer is better; it explains how JVector implements a graph-based index for scalable vector searches and how the documents are immediately available.
Note that the results take a lot longer to generate – 17.5 seconds (vs 6.1s for vector search only). Following the edges from the first four documents we retrieved with vector search led to 31 total documents being retrieved. The extra tokens took the LLM a bit longer to make sense of, although they still did a great job coming up with the answer. At the same time, it doesn’t feel like it deeply answers the question. Perhaps because there was so much for the LLM to consider, it didn’t get to the most concise answer it could.
What if there was a way to retrieve fewer documents, while maximizing diversity? A way to follow the edges when they provided additional relevant information, especially when it increased the diversity of what was retrieved? We can modify maximum marginal retrieval (MMR) to do exactly this.
MMR traversal
The MMR traversal search performs a combination of vector and graph traversal to retrieve a specific number of documents. Unlike traditional MMR, after a node is selected, its adjacent nodes become candidates for retrieval as well. This allows the MMR traversal to explore the graph, using the diversity parameter to decide how much to prefer similar nodes versus how much to prefer diverse nodes retrieved via vector search or graph traversal.
As with switching to traversal, using this technique is an easy change to the `retriever`:
retriever = knowledge_store.as_retriever(
search_type = "mmr_traversal",
search_kwargs = {
"k": 4,
"fetch_k": 10,
"depth": 2,
},
)
This answer seems even better. Not only does it talk about how JVector is implemented, but it provides details on some of the techniques that it uses to handle the search and update efficiently.
If we take a look at what was retrieved, we see that it only retrieved four documents (after considering 15 in total). It retrieved a combination of similar results (such as the getting started and indexing concepts) as well as the deeper results (the documentation for JVector) needed to answer the question.
-
https://docs.datastax.com/en/astra-db-serverless/get-started/concepts.html
-
https://docs.datastax.com/en/astra-db-serverless/cli-reference/astra-cli.html
-
https://github.com/jbellis/jvector
-
https://docs.datastax.com/en/cql/astra/developing/indexing/indexing-concepts.html
Conclusion
Content-centric knowledge graphs are available for preview as part of RAGStack. You can also check out the notebook from the case study. We are working on contributing them to LangChain, as well as a variety of exciting improvements to how edges are created and traversed. Stay tuned for exciting follow-ups in this area.






