

Googleに質問して、Wikipediaへのリンクが表示され、クリックしてWebサイトを読み込み、答えを見つけるためにスクロールしなければならなかったことが何度ありましたか?
Wikipediaが検索エンジンの検索結果の上位にあるのは、信頼できるサイトであり、人々がその情報が信頼できるもので、権威がある、と考えているからです。では、なぜWikipediaで直接検索しないのでしょう?実は、Wikipediaに直接アクセスして質問を試みると、関連ページのリストとともに、「存在しません」というエラーが表示され、答えを探し続けることになるかもしれないからなのです。
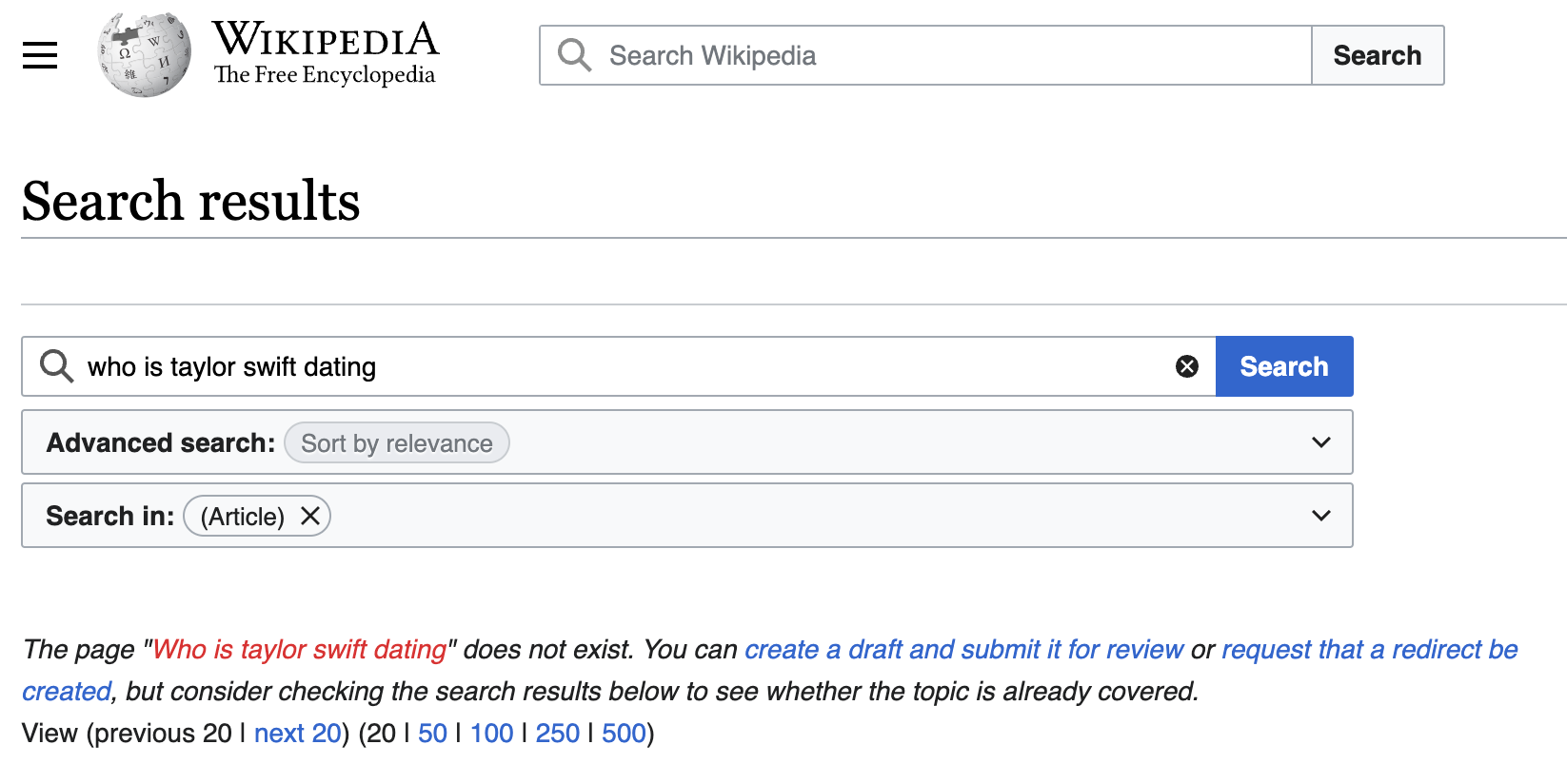
私たちはWikipediaと、彼らが知識を「民主化」するために行ってきたすべてのことが大好きなので、この問題に正面から取り組むことにしました。そこで私たちはWikiChat、Wikipediaに質問し、自然言語による回答を得る方法を、以下のツールを使って開発しました:Next.js、LangChain、Vercel、OpenAI、Cohere, そして DataStaxAstra DB。
WikiChatはWikipediaの人気トップ-1000ページでブートストラップされ、Wikipediaのリアルタイム更新フィードを使用して情報ストアを更新します。Astra DBの素晴らしい機能の一つは、これらの更新を同時に取り込み、インデックスを再作成し、インデックスを再構築するための遅延なくユーザーがクエリーできるようにする能力です。
WikiChatのソースコードが入手可能Githubから私たちがどのように作り上げたのか、深く掘り下げてお読みください。
アーキテクチャ
多くのretrieval-augmented generation (RAG) アプリケーションと同様に、このアプリは、ナレッジベースを作成するデータ取り込みスクリプトと、会話エクスペリエンスを提供するWebアプリの2つの部分で設計されています。
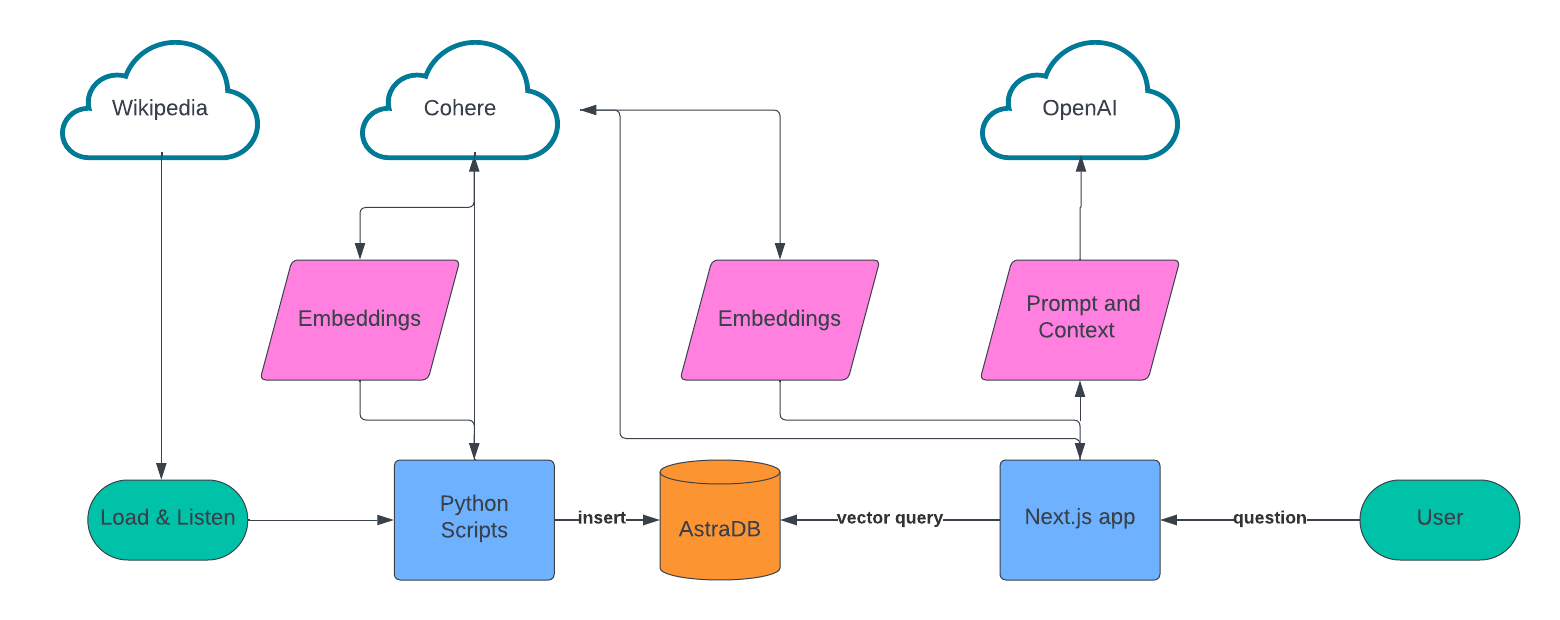
データの取り込みでは、スクレイピングするソースのリストを作成し、LangChainを使用してテキストデータをチャンクし、Cohereを使用して埋め込みを作成し、embeddingsこれらすべてをAstra DBに格納しました。
会話型UXについては、Next.js、VercelのAIライブラリ、Cohere、OpenAIをベースにしています。ユーザーが質問をすると、Cohereを使用してその質問の埋め込みを作成し、ベクター検索を使用してAstra DBにクエリを実行し、Astra DB using vector searchその結果をOpenAIにフィードして、ユーザーへの会話応答を作成します。
セットアップ
このアプリケーションを自分で構築する、または既存のリポジトリを立ち上げて実行するために必要なものがいくつかあります:
- A free Astra DB account
- 無料のCohereアカウント
- 1つのOpenAIアカウント
Astra DBにサインアップ後、新しいベクトルデータベースを作成する必要があります。続けてアカウントにログインしてください。
次に、新たなサーバーレスのベクトルデータベースを作成します。お好きな名前を付け、ご希望のプロバイダーとリージョンを選択してください。
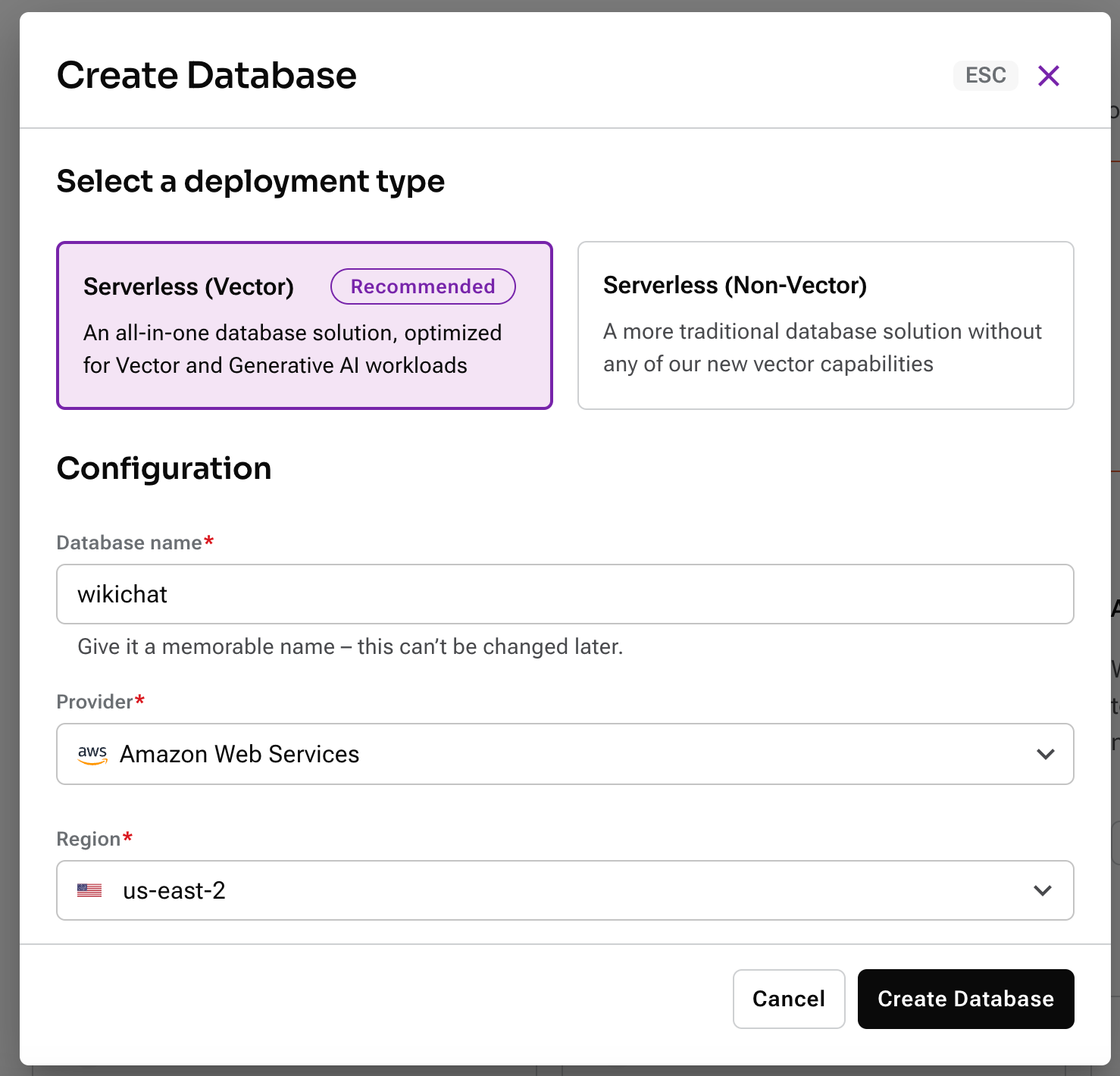
データベースのプロビジョニングを待つ間、プロジェクトのルートにある.env.exampleを.envにコピーしてください。このアプリケーションを構築するために使用するAPIの秘密の認証情報と設定情報を保存するために使用します。
データベースが作成されたら、新しいアプリケーション・トークンを作成してください。
ポップアップウィンドウが表示されたら、”copy” ボタンをクリックし、その値を.envファイル内のASTRA_DB_APPLICATION_TOKENにペーストしてください。次に、API endpointをコピーします:

その値を、,envファイルのASTRA_DB_ENDPOINTにペーストして下さい。
Cohereアカウントにログインして、API Keysに進んでください。開発用に使用できるトライアルAPIキーがあります; その値をコピーして、COHERE_API_KEYキーの下に保存してください。
最後に、OpenAIアカウントにログインして、新しいAPI keyを作成してください。そのAPI keyをenvにOPENAI_API_KEYとして保存してください。
以上です - さあ、コードを書く時間です!
データの取り込み
scriptsディレクトリーには、WikiChatのために取り込まれたすべてのデータを処理するPythonスクリプトがあります。これは、まず、人気のあるWikipediaの記事の初期バッチを読み込み、次に、Wikipediaの公開されているイベントストリームを使って英語の記事の変更を監視します。
注:イベントストリームには、ボット、トークページの変更、さらにはシステムをテストするために送られたカナリー・イベントなど、様々な形式の更新が含まれます。ソースに関わらず、各記事は取り込まれるまでに5つのステップを通過します。
データ取り込みのステップに入る前に、Data APIを使ってAstraに保存するデータを簡単に見てみましょう。Data APIは、JSON Documentを使ってデータを保存し、Collectionsにまとめます。デフォルトでは、ドキュメント内のすべてのフィールドがインデックスづけされ、埋め込みベクトルを含むクエリーに使用することができます。WikiChatアプリケーションには、以下の3つのCollectionsを作成しました :
article_embeddings- 各ドキュメントには、記事のテキストチャンクと、Cohereを使用して作成されたエンベディング・ベクトルが格納されています。これはWikiChatがチャットの質問に答えるために必要な核となる情報です。article_metadata- 各ドキュメントには、取り込んだ単一のの記事に関するメタデータが保存されています。その中には、最後に取り込んだ際に含まれていたチャンクに関する情報も含まれています。article_suggestions- このコレクションには、スクリプトにより最後に処理された5つの記事を追跡するために継続的に更新されている単一のドキュメントが含まれており、それぞれの記事について、最初の5つのチャンクまたは最も最近更新された5つのチャンクのいずれかが含まれています。
scripts/wikichat/database.pyファイルは、astrapyクライアント・ライブラリーを初期化し、Data APIを呼び出してコレクションを作成し、それらを操作するためのクライアントサイド・オブジェクトを作成します。我々が行う必要がある唯一のデータモデリングは、各コレクションに格納するPythonクラスです。これらは scripts/wikichat/processing/model.py ファイルで定義します。ファイルの前半は、後述するパイプラインを通して記事を渡すために使用するクラスを定義し、後半はAstraに格納したいクラスを定義します。これらのクラスは全て標準的なPythonのデータクラスとして定義されています。また、Astraに格納されるクラスはdataclasses-jsonを使用します。このライブラリーはAstraに格納されているPython辞書との間でデータクラスの階層をシリアライズすることができるからです。
例えば、ChunkedArticleMetadataOnlyクラスはarticle_metadataコレクションに格納されていて、次のように定義されています:
@dataclass_json
@dataclass
class ChunkedArticleMetadataOnly:
_id: str
article_metadata: ArticleMetadata
chunks_metadata: dict[str, ChunkMetadata] = field(default_factory=dict)
suggested_question_chunks: list[Chunk] = field(default_factory=list)このクラスのオブジェクトを(scripts/wikichat/processing/articles.py/update_article_metadata())に格納しようとするときは、このクラスにdataclass_jsonによって追加されたto_dict()メソッドを使います。これは、astrapyがJSONドキュメントとして保存するための基本的なPython辞書を作成します。
METADATA_COLLECTION.find_one_and_replace(
filter={"_id": metadata._id},
replacement=metadata.to_dict(),
options={"upsert": True}
)読み返すと, (同じファイル内の calc_chunk_diff()で),from_dict()が使用され、保存されたJSONドキュメントからオブジェクト階層全体が再構築されています。
resp = METADATA_COLLECTION.find_one(filter={"_id": new_metadata._id})
prev_metadata_doc = resp["data"]["document"]
prev_metadata = ChunkedArticleMetadataOnly.from_dict(prev_metadata_doc)アウトラインとデータアクセスの説明が終わったところで、各記事をどのように処理するか見ていきましょう。記事はPythonのAsynchronous I/Oを使って構築された処理パイプラインを通されます。Asynchronousプロセスは、Wikipediaからの更新の突発的な性質に対処するためと、スクリプトが必要とするさまざまなリモートコールを待つ間確実に処理を継続させるために使用されます。処理パイプラインには5つのステップがあります。
load_article()はwikipedia.orgから記事を取得し、Beautiful Soupを使ってHTMLからtextを取り出します。chunk_article()は記事をチャンクに分割し、それらを使用してその意味を表す埋め込みベクトルを作成します。テキストはLangChainのRecursiveCharacterTextSplitterによりチャンクされ、チャンクのsha256ハッシュはチャンクが等しいかどうかを比較するためにメッセージダイジェストとして計算されます。calc_chunk_diff()は、最初にAstraをチェックして、この記事に関する以前のメタデータがあるかどうかを確認し、次に現在の記事を記述する "Diff"を作成します。現在のすべてのチャンクのハッシュが、前回その記事を参照したときのハッシュと比較されます。以前に見たことのない記事は、新しいテキストのチャンクだけを含み、以前に見た記事は新しいチャンク、削除されたチャンク、変更されていないチャンクの組み合わせを含みます。vectorize_diff()213は、Cohereを呼び出して、記事中の新しいテキストのチャンクに対する埋め込みを計算します。"Diff" を計算した後にCohereを呼び出すのは、変更されていないテキストのチャンクに対するベクトルの計算を避けるためです。store_article_diff()は、Astraを更新して、この記事について現在わかっていることを保存します;これには3つのステップがあります。update_article_metadata()は、article_metadataコレクションの記事のメタデータと、article_suggestionsコレクションの両方を更新し、ユーザー・インターフェースが新しい質問を提案できるように最近の更新を追跡しています。insert_vectored_chunks(2)は、すべての新しいチャンクとそのベクトルをarticle_embeddingsコレクションに挿入します。delete_vectored_chunks()は、更新された記事にはもう存在しないすべてのチャンクを削除します。
チャットボットのユーザー・エクスペリエンスの構築
Wikipediaから人気のあるデータを事前に読み込み、コンテンツのリアルタイムな更新を設定し、チャットボットを構築する準備が整いました!このアプリケーションでは、フルスタックのReact.js WebフレームワークであるNext.jsを使うことにしました。このWebアプリケーションの最も重要な2つのコンポーネントは、Webベースのチャットインターフェースと、ユーザーの質問に対する回答を取得するサービスです。
チャットインターフェイスはVercelのAI npm libraryによって提供されています。このモジュールにより、開発者は数行のコードでChatGPTのような体験を構築することができます。このアプリケーションでは、Webアプリケーションのルートを表す`app/page.tsx`ファイルにこのエクスペリエンスを実装しています。ここで、いくつかのコード・スニペットを紹介します:
"use client";
import { useChat, useCompletion } from 'ai/react';
import { Message } from 'ai';
The ”use client”;ディレクティブは、このモジュールがクライアントでのみ実行されることをNext.jsに伝えます。import文は、VercelのAIライブラリーをアプリケーションで利用できるようにします。
const { append, messages, isLoading, input, handleInputChange, handleSubmit } = useChat();これはuseChat Reactフックを初期化するもので、ユーザーがチャットボットと対話するときのステータスとほとんどのインタラクティブなエクスペリエンスを処理します。
const handleSend = (e) => {
handleSubmit(e, { options: { body: { useRag, llm, similarityMetric}}});
}ユーザーが質問をしたとき、その情報をバックエンドのサービスに渡し、答えを出すfunctionです。
const [suggestions, setSuggestions] = useState<PromptSuggestion[]>([]);
const { complete } = useCompletion({
onFinish: (prompt, completion) => {
const parsed = JSON.parse(completion);
const argsObj = JSON.parse(parsed?.function_call.arguments);
const questions = argsObj.questions;
const questionsArr: PromptSuggestion[] = [];
questions.forEach(q => {
questionsArr.push(q);
});
setSuggestions(questionsArr);
}
});
useEffect(() => {
complete('')
}, []);これは、もう1つの重要なフック、インデックスを作成したWikipediaから最近更新されたページに基づいて提案された質問をロードするために使用するフックを初期化します。onFinishハンドラは、サーバーから受け取った JSON ペイロードを使用して、UI に表示される setSuggestionssetSuggestions を設定します。これらの提案された質問がどのように作成されるのか、サーバー側で掘り下げて見てみましょう。
始める前に、あらかじめいくつかの質問を準備

前述のように、ユーザーが最初にWikiChatをロードしたとき、最近更新され、アプリケーションによって取り込まれたWikipediaのページに基づく、いくつかの候補の質問が提供されます。しかし、どのように最近更新されたページから候補の質問に行きつくのでしょう?何が起こっているのか確認するために、/api/completion/route.ts を調べてみましょう:
import { AstraDB } from "@datastax/astra-db-ts";
import { OpenAIStream, StreamingTextResponse } from "ai";
import OpenAI from "openai";
import type { ChatCompletionCreateParams } from 'openai/resources/chat';ここでは、以下のリソースをインポートしています:Astra DBクライアント、いくつかのVercelのAI SDKのヘルパー、OpenAIクライアント、そして後で説明するヘルパー・タイプです。
const{
ASTRA_DB_APPLICATION_TOKEN,
ASTRA_DB_ENDPOINT,
ASTRA_DB_SUGGESTIONS_COLLECTION,
OPENAI_API_KEY,
} = process.env;
const astraDb = new AstraDB(ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ENDPOINT);
const openai = new OpenAI({
apiKey: OPENAI_API_KEY,
});次に、.env ファイルで設定したキーに基づいて、Astra DBとOpenAIクライアントを初期化します。
const suggestionsCollection = await astraDb.collection(ASTRA_DB_SUGGESTIONS_COLLECTION);
const suggestionsDoc = await suggestionsCollection.findOne(
{
_id: "recent_articles"
},
{
projection: {
"recent_articles.metadata.title" : 1,
"recent_articles.suggested_chunks.content" : 1,
},
});データの取り込みプロセスについてご説明し、Wikipediaの記事のうち最近更新された5つの記事をデータベースのドキュメントに格納した話を思い出してください。ここでは、クライアントのfindOnefunctionを使って、そのドキュメントにクエリーをかけます。projection オプションを使うと、指定したドキュメントの属性のみを返すようにクライアントに指示することができます。
const docMap = suggestionsDoc.recent_articles.map(article => {
return {
pageTitle: article.metadata.title,
content: article.suggested_chunks.map(chunk => chunk.content)
}
});
docContext = JSON.stringify(docMap);ドキュメント取得後、それを使って「ページタイトル」と「コンテンツ」のペアの単純な配列オブジェクトを作成します。
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo-16k",
stream: true,
temperature: 1.5,
messages: [{
role: "user",
content: `You are an assistant who creates sample questions to ask a chatbot.
Given the context below of the most recently added data to the most popular pages
on Wikipedia come up with 4 suggested questions. Only write no more than one
question per page and keep them to less than 12 words each. Do not label which page
the question is for/from.
START CONTEXT
${docContext}
END CONTEXT
`,
}],
functions
});最近更新されたWikipediaページのデータ (タイトルとコンテンツ) が得られたので、これをアプリの推奨質問に変換する方法が気になるかもしれません。わからないときは LLM に聞いてみてください。
OpenAIのチャット完了APIを呼び出す際に、適切な質問を構築するために渡されたデータを使用するようLLMに要求するプロンプトを構築します。より創造的な回答を得るために、どのような質問か、どれくらいの長さか、温度を1.5(値の範囲は0~2)に設定する、などの指示を与えます。
functions の最後のパラメータでは、custom functionを渡すことができます。この場合、OpenAIから戻ってくるレスポンスの "shape "を定義するためにこのfunctionを使用しています。 これにより、簡単に解析し、ユーザー・インターフェースに提案された質問を追加することができます。
const functions: ChatCompletionCreateParams.Function[] = [{
name: 'get_suggestion_and_category',
description: 'Prints a suggested question and the category it belongs to.',
parameters: {
type: 'object',
properties: {
questions: {
type: 'array',
description: 'The suggested questions and their categories.',
items: {
type: 'object',
properties: {
category: {
type: 'string',
enum: ['history', 'science', 'sports', 'technology', 'arts', 'culture',
'geography', 'entertainment','politics', 'business', 'health'],
description: 'The category of the suggested question.',
},
question: {
type: 'string',
description: 'The suggested question.',
},
},
},
},
},
required: ['questions'],
},
}]; このペイロードの奥深くに、私たちが定義し、返されることを期待している2つの重要な値があります。1つ目はcategoryで、アプリケーション・ユーザー・インターフェースでアイコンを設定するために使用する一握りの定義済みの値の1つの文字列です。2つ目はquestionで、ユーザー・インターフェースでユーザーに表示する質問の候補を表す文字列です。
質問に答えるためにRAGを使用する

import { CohereEmbeddings } from "@langchain/cohere";
import { Document } from "@langchain/core/documents";
import {
RunnableBranch,
RunnableLambda,
RunnableMap,
RunnableSequence
} from "@langchain/core/runnables";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { PromptTemplate } from "langchain/prompts";
import {
AstraDBVectorStore,
AstraLibArgs,
} from "@langchain/community/vectorstores/astradb";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { StreamingTextResponse, Message / } from "ai"; これらのインポートにより、Langchain JS SDKの関連部分を利用できるようになります。LLMとしてCohereとOpenAIを、ベクトルストアとしてAstra DBをLangchainのビルトイン・サポートとして使っていることにすでにお気づきでしょう。
const questionTemplate = `You are an AI assistant answering questions about anything
from Wikipedia the context will provide you with the most relevant data from wikipedia
including the pages title, url, and page content.
If referencing the text/context refer to it as Wikipedia.
At the end of the response add one markdown link using the format: [Title](URL) and
replace the title and url with the associated title and url of the more relavant page
from the context
This link will not be shown to the user so do not mention it.
The max links you can include is 1, do not provide any other references or annotations.
if the context is empty, answer it to the best of your ability. If you cannot find the
answer user's question in the context, reply with "I'm sorry, I'm only allowed to
answer questions related to the top 1,000 Wikipedia pages".
<context>
{context}
</context>
QUESTION: {question}
`;
const prompt = PromptTemplate.fromTemplate(questionTemplate);質問テンプレートは、LLMのプロンプトを作成するために使用するもので、可能な限り最良の答えを提供するために、さらなる文脈を追加することができます。そして、Wikipediaのソースページへのリンクをマークダウン形式で提供するように指示していることに注目してください。後でユーザー・インターフェースで答えをレンダリングするときに、これを活用します。
const {messages, llm } = await req.json();
const previousMessages = messages.slice(0, -1);
const latestMessage = messages[messages?.length - 1]?.content;
const embeddings = new CohereEmbeddings({
apiKey: COHERE_API_KEY,
inputType: "search_query",
model: "embed-english-v3.0",
});
const chatModel = new ChatOpenAI({
temperature: 0.5,
openAIApiKey: OPENAI_API_KEY,
modelName: llm ?? "gpt-4",
streaming: true,
}); POST functionの中で、チャット履歴(メッセージ)の値を受け取り、その値を使ってpreviousMessagesとlatestMessageを定義します。次に、LangChain で使用するために Cohere と OpenAI を初期化します。
const astraConfig: AstraLibArgs = {
token: ASTRA_DB_APPLICATION_TOKEN,
endpoint: ASTRA_DB_ENDPOINT,
collection: “article_embeddings”,
contentKey: “content”
};
const vectorStore = new AstraDBVectorStore(embeddings, astraConfig);
await vectorStore.initialize();
const retriever = vectorStore.asRetriever(10);それでは、LangChain用のAstra DBベクトルストアを設定します。ここで、コレクションの接続認証情報、クエリ元のコレクション、DBから戻ってくるドキュメントの上限10個を指定します。
const chain = RunnableSequence.from([
condenseChatBranch,
mapQuestionAndContext,
prompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName: "chatChain"});
const stream = await chain.stream({
chat_history: formatVercelMessages(previousMessages),
question: latestMessage,
/});ここでLangChainマジックが起こる✨
まず、一連のRunnableを渡してRunnableSequenceを作成します。この時点で知っておくべきことは、RunnableSequenceは先頭から始まり、それぞれのRunnableを実行し、その出力を入力として次のRunnableに渡すということです。
シーケンスを定義した後、チャット履歴と最新の質問を使ってシーケンスを実行します。このシーケンスでは多くのことが行われているので、それぞれを調べてみましょう。
const hasChatHistoryCheck = RunnableLambda.from(
(input: ChainInut) => input.chat_history.length > 0
);
const chatHistoryQuestionChain = RunnableSequence.from([
{
question: (input: ChainInut) => input.question,
chat_history: (input: ChainInut) => input.chat_history,
},
condenseQuestionPrompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName:"chatHistoryQuestionChain"});
const noChatHistoryQuestionChain = RunnableLambda.from(
(input: ChainInut) => input.question
).withConfig({ runName: "noChatHistoryQuestionChain"});
const condenseChatBranch = RunnableBranch.from([
[hasChatHistoryCheck, chatHistoryQuestionChain],
noChatHistoryQuestionChain,
]).withConfig({ runName: "condenseChatBranch"}); シーケンスの中の最初の Runnable は condenseChatBranchです。このコードの目的は、WikiChatを賢くし、以前に質問された内容を認識させることです。例を用いて説明しましょう:
- 質問1:Star Warsの悪役は誰?
- 答え:Darth Vader
- 質問2:彼の子供たちは誰?
最初の質問の意味がわからなければ、2番目の質問は意味をなしません。そこで、if/else文のように機能するRunnableBranchを定義します。RunnableのhasChatHistoryがtrueであれば、LangchainはchatHistoryQuestionChainを実行し、そうでなければnoChatHistoryChainを実行します。
hasChatHistoryCheckは、チェーンを初期化したときに定義したchat_history inputに空でない値があるかどうかをチェックするだけです。
このチェックがtrueの場合、chatHistoryQuestionChain Runnableは質問とチャット履歴をLLMに送り、より適切な質問を作成します。condenseQuestionPrompt がどのように機能しているのか確認しましょう:
const condenseQuestionTemplate = `Given the following chat history and a follow up
question, If the follow up question references previous parts of the chat rephrase the
follow up question to be a standalone question if not use the follow up question as the
standalone question.
<chat_history>
{chat_history}
</chat_history>
Follow Up Question: {question}
Standalone question:`;
const condenseQuestionPrompt = PromptTemplate.fromTemplate(
condenseQuestionTemplate,
);ここで、チャット履歴を考慮し、LLMに質問されたことがフォローアップの質問かどうかを確認するような具体的な指示を出すプロンプトを定義します。先ほどの例で言えば、LLMは "Who are his children? "という質問を受け、チャット履歴を見て、"Who are Darth Vader's children? "と書き換えます。なんと賢いチャットボットでしょう!
もしチャット履歴がない場合には、noChatHistoryQuestionChain はno-opとして機能し、ユーザーが質問した内容をそのまま返します。
const combineDocumentsFn = (docs: Document[]) => {
const serializedDocs = docs.map((doc) => `Title: ${doc.metadata.title}
URL: ${doc.metadata.url}
Content: ${doc.pageContent}`);
return serializedDocs.join("\n\n");
};
const retrieverChain = retriever.pipe(combineDocumentsFn).withConfig({ runName:
"retrieverChain"});
const mapQuestionAndContext = RunnableMap.from({
question: (input: string) => input,
context: retrieverChain
}).withConfig({ runName: "mapQuestionAndContext"});メインシーケンスの次はmapQuestionAndContextで、前のステップからの出力(ユーザーの質問)が渡され、Astra DBから最も近いマッチングドキュメントを検索し、文字列に結合します。
この文字列は次のステップに渡され、先ほど定義したプロンプトになります。その後、この完全に展開されたプロンプトをLLMに渡し、最終的にLLMからの出力を LangChain StringParser.に渡します。
return new StreamingTextResponse(stream);最後にしなければならないのは、Langchain streamをStreamingTextResponse として返すことで、ユーザーはワイヤーを伝わってくるLLMの出力をリアルタイムで見ることができます。
まとめ
ここまで、非常に多くの情報がありました。Wikipediaで最も人気のあるページや最近更新されたページについての質問に答えることができるインテリジェントなチャットボットを作るためにカバーしたすべての事柄を再確認しましょう:
- Wikipediaの人気記事1,000件をかきあつめて初期データセットをロード。
- リアルタイムの更新を受信し、差分のみを処理する。
- LangChainを使ってテキストデータを知的にチャンキングし、Cohereを使って埋め込みデータを生成する。
- アプリケーションとベクトルデータをAstra DBに格納.。
- VercelのAIライブラリを使ったWebベースのチャットボットUX (User Experience) の構築。
- ベクトル検索をAstra DB上で実行
- OpenAIを使って、正確で文脈を考慮した応答を生成。
最新バージョンのWikiChatはVercelにデプロイされていて、https://wikich.at32にて確認することができます。
すべてのコードはGithyb上でオープンソースとして公開されています。ですから、ご自由にお読みいただき、有用と思われる部分があれば再利用してください。
実際の動きを見てみたいですか?私たちとパートナーのLangChainによる1月24日のライブストリーミングにご参加ください。Astra DB、LangChain.JS、Next.jsを使用して、本格的なRAGアプリケーションを構築します。
コードやAstra DBでの構築経験、新しいData APIについて質問がある場合は、私をX (Twitter)で見つけてください。どうぞお楽しみください!








