
Storage-attached indexing (SAI) has been one of the most anticipated features in Apache Cassandra® 5.0. Query patterns are much more flexible and performant, there’s far less coding required, and the path to adding application functionality is far easier.
This is part three of a series in which we’ve been showing you how to replace your Solr deployment with SAI on Astra DB.
In part one, we demonstrated the basics of SAI to show how easy it is to read from a movies database by searching for terms on non-primary key columns indexed by SAI. In part two, we dug deeper and replaced complex Solr schema with SAI indexes which leveraged Lucene analyzers, tokenizers and token filters.
Yes, there's more! In this post, we'll go beyond just text searches and term-matching. We'll show you how to modernize your apps with semantic search to retrieve data not just based on words that match the search but by using the contextual meaning behind them to return highly relevant results with large language models (LLMs) and generative AI. Let's go!
In the last episode
We continued to use a notional application with movie data and images sourced from The Movie Database (TMDB), a community-built movie and TV database.
With text analyzers, we showed that you could query your database beyond just simple text-matching against search terms. Adding a stemming filter like Lucene's PorterStemFilter:
CREATE CUSTOM INDEX ON movies_by_id (title) USING 'StorageAttachedIndex'
WITH OPTIONS = { 'index_analyzer' : '{
"tokenizer" : {"name":"standard"},
"filters" : [ {"name":"lowercase"}, {"name":"porterstem"} ] }'
};enabled us to search for titles with the search term "extraction" normalized to "extract" and get matches that included "Extract", "Extracted," and "Extraction" in the movie title.
We showed how we can query indexed CQL collections using the CONTAINS and CONTAINS KEY operators:
SELECT * FROM ... WHERE genres CONTAINS 'Action';
SELECT * FROM ... WHERE cast CONTAINS KEY 'Thor';We also replaced multi-term Solr searches like:
SELECT * FROM ... WHERE solr_query = 'genres:Action AND Thriller';with the SAI query:
SELECT * FROM ... WHERE genres CONTAINS 'Action' AND genres CONTAINS 'Thriller';We replaced multi-field Solr searches like:
SELECT * FROM ... WHERE solr_query = 'title:extraction AND release_year:2020';with a multi-indexed column SAI query:
SELECT * FROM ... WHERE title:'extraction' AND release_year=2020;And an even more complex search for movies with "Thor" or "Avengers" in the title that stars Chris Hemsworth:
SELECT * FROM ...
WHERE (title:'Extraction' OR title:'Avengers')
AND cast CONTAINS 'Chris Hemsworth';
It's just semantics
Matching text from search terms isn’t always effective in retrieving relevant results, because sometimes words that are spelled the same might not mean the same thing. For example, consider the word "capital" in these two sentences:
-
The capital of Australia is Melbourne.
-
How much capital is required for the investment?
In the first sentence, the word "capital" refers to a city that is the main administrative centre of a country or region. In the second sentence, it refers to monetary value. Despite having the same spelling and pronunciation, they are two distinct words with different meanings (semantics).
If we ran a text search for "capital," a search engine would return results that would match for capital cities even when we are interested in financial capital (and vice versa).
Semantics matter. In the age of AI, the traditional text search is no longer good enough. Enter semantic search.
Embeddings
Semantic search is an advanced searching technique which uses natural language processing (NLP) and machine learning algorithms to understand the underlying meaning and context of a user's query to deliver more accurate and relevant results.
We can extract the essence of unstructured data using LLMs and generate vector embeddings. Embeddings are arrays of vectors (floating point numbers) which are numerical representations of data or objects in multidimensional space where each dimension is an encoding of a feature or attribute which captures the semantic essence of objects or things.
By encoding the data in our database as vectors, we can perform mathematical operations on the embeddings to measure similarity between vectors. Doing so enables us to quickly locate the top N rows in the table which are most similar (most semantically relevant) to the user query.
In our movies app, users can type anything in the dialog box to search for movies. The app doesn't have to parse the query string as filters for a specific column or field. It just uses the user's free-form query as is. For example, here is a user's search for action or drama movies starring Chris Hemsworth:

For a more comprehensive explanation, see the guide, "What are Vector Embeddings?".
Vectorize
Let's look at vector embeddings in action. For our movies application, we will use OpenAI's text embedding model text-embedding-3-small. We generate embeddings using the following Python code:
from openai import OpenAI
openai_client = OpenAI()
def generate_embeddings(input_text):
response = openai_client.embeddings.create(
input=input_text,
model="text-embedding-3-small"
)
return response.data[0].embeddingSince Astra DB is a vector database, we can store the embeddings alongside the movie data in the same table. To do this, we need to extend the table to add a new column of type vector which will store an array of 1,536 float (the text-embedding-3-small generates embeddings with 1536 dimensions):
ALTER TABLE movies_by_id ADD embeddings vector<float, 1536>;The updated table definition now looks something like this:
CREATE TABLE movies_by_id (
movie_id text PRIMARY KEY,
cast map<text, text>,
embeddings vector<float, 1536>,
genres set<text>,
imdb_id text,
overview text,
release_date date,
release_year int,
runtime int,
title text,
)Remember to index the new embeddings column so we can query it with SAI:
CREATE CUSTOM INDEX ON movies_by_id (embeddings)
USING 'StorageAttachedIndex';In our app, we generated embeddings on input_text , which is a combination of the movie title, overview, genres and cast:
input_text = str(title) + " " + str(overview) + " " + str(genres) + " " + str(cast)We have included the genres and the list of cast when we generated the embeddings so users can include phrases like "action movies" or "starring Gal Gadot" in their search query to extend the capability of the app.
Because the data is already loaded to the table, we had to iterate over the movies in the DB, generated the embeddings by calling generate_embeddings() above, then saved the embeddings in the table with:
def store_embeddings(movie_id, embeddings):
session.execute(
"""
INSERT INTO movies_by_id (movie_id, embeddings)
VALUES(%s, %s)
""",
(movie_id, embeddings)
)
A better search
Vector search uses the approximate nearest neighbour (ANN) search algorithm to find the "closest" vectors in multidimensional space.
In its simplest form, we perform a vector search by querying the SAI index using ANN to find the nearest vectors (with ORDER BY and LIMIT clauses) to the vector embedding equivalent of the user's query string. The CQL query which returns the 3 nearest vectors looks like:
SELECT ... FROM movies_by_id
ORDER BY embeddings
ANN OF <query_vector>
LIMIT 3;Obviously, we need to generate an embedding of the user's query by making an API call to the embedding model. The Python function we used looks like this:
from openai import OpenAI
openai_client = OpenAI()
response = openai_client.embeddings.create(
input=user_query,
model="text-embedding-3-small"
)
query_vector = response.data[0].embeddingAnd here is an example of the code for generating a list of movies:
vector_search = "SELECT * FROM movies_by_id ORDER BY embeddings ANN OF %s LIMIT 3"
movies = session.execute(vector_search, [query_vector])Yes. That's all there is. A simple SELECT statement executes a vector search. I'll pause here to let it sink in…
[Pause]
OK, are you ready? Let's break it down:
-
it is just a single CQL
SELECTstatement -
that performs an
ANNsearchOFthe vector embedding of the user's query string -
of the top three movies (
LIMIT 3) -
ORDER BYthe nearest embeddings (vectors) of the combined movie title, overview, genres and cast.
The user query string can be any phrase, sentence, even a long paragraph that describes what the user is looking for. But the key here is that unlike a Solr search query, which matches text in the search terms, vector search performs mathematical operations on the embeddings to search through the database records to locate the closest semantic match.
In this example, the app will take the user's search string just the way it is, generate the embeddings, then execute the search for superhero movies where women are the lead actors:
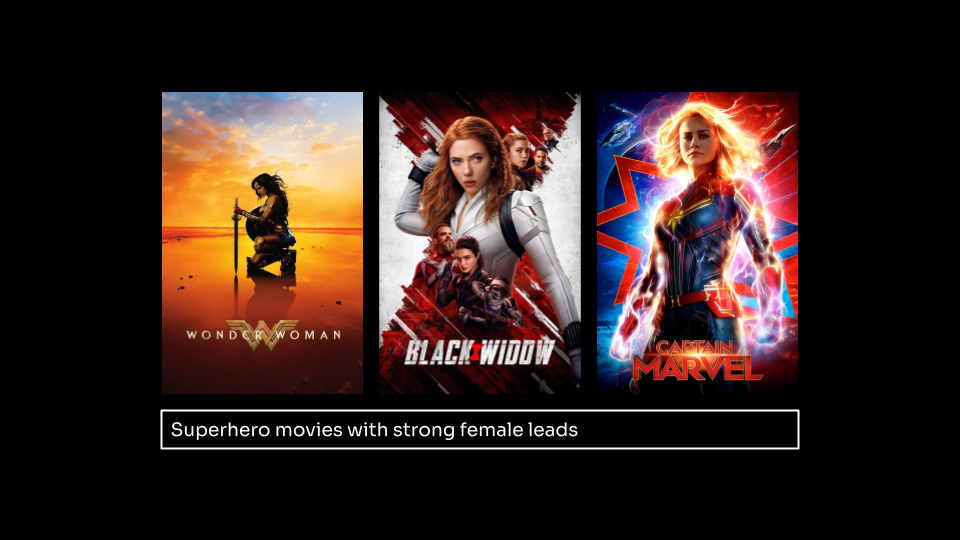
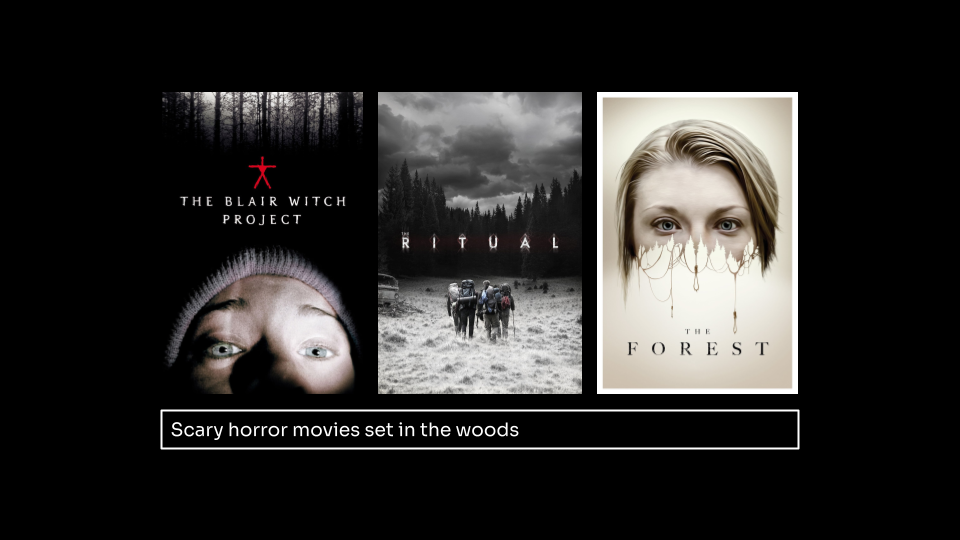
Another search for horror movies set in a forest:
Or a search for the apocalypse:

Try it today!
Vector search is a powerful tool enabled by SAI that takes advantage of advancements in large LLMs and GenAI.
We don't think it's a drop-in replacement for Solr's full text search capabilities. We think vector search with SAI is an even better replacement.
Check out the Vector Search Quickstart guide and try Astra DB for free—or book a demo with our data architects for a guided tour of SAI in action!




