
Unstructured.io has established itself as the go-to choice for getting any kind of data ready for ingestion by large-language models. They solve a key challenge that developers wrangle with when building retrieval-augmented generation apps: how to handle the broad range of enterprise data formats. It’s the reason we’ve partnered so closely with Unstructured, and it’s why we’re excited to announce our latest integrations with them: our updated Astra Data Loader, which now supports PDFs, and the inclusion of Unstructured flexible document ingestion capabilities in the low-code IDE Langflow.
These integrations inject even more of Unstructured’s document-processing capabilities directly into the DataStax AI platform, making it easier than ever for developers to prepare and ingest a wide variety of document types for their generative AI applications.
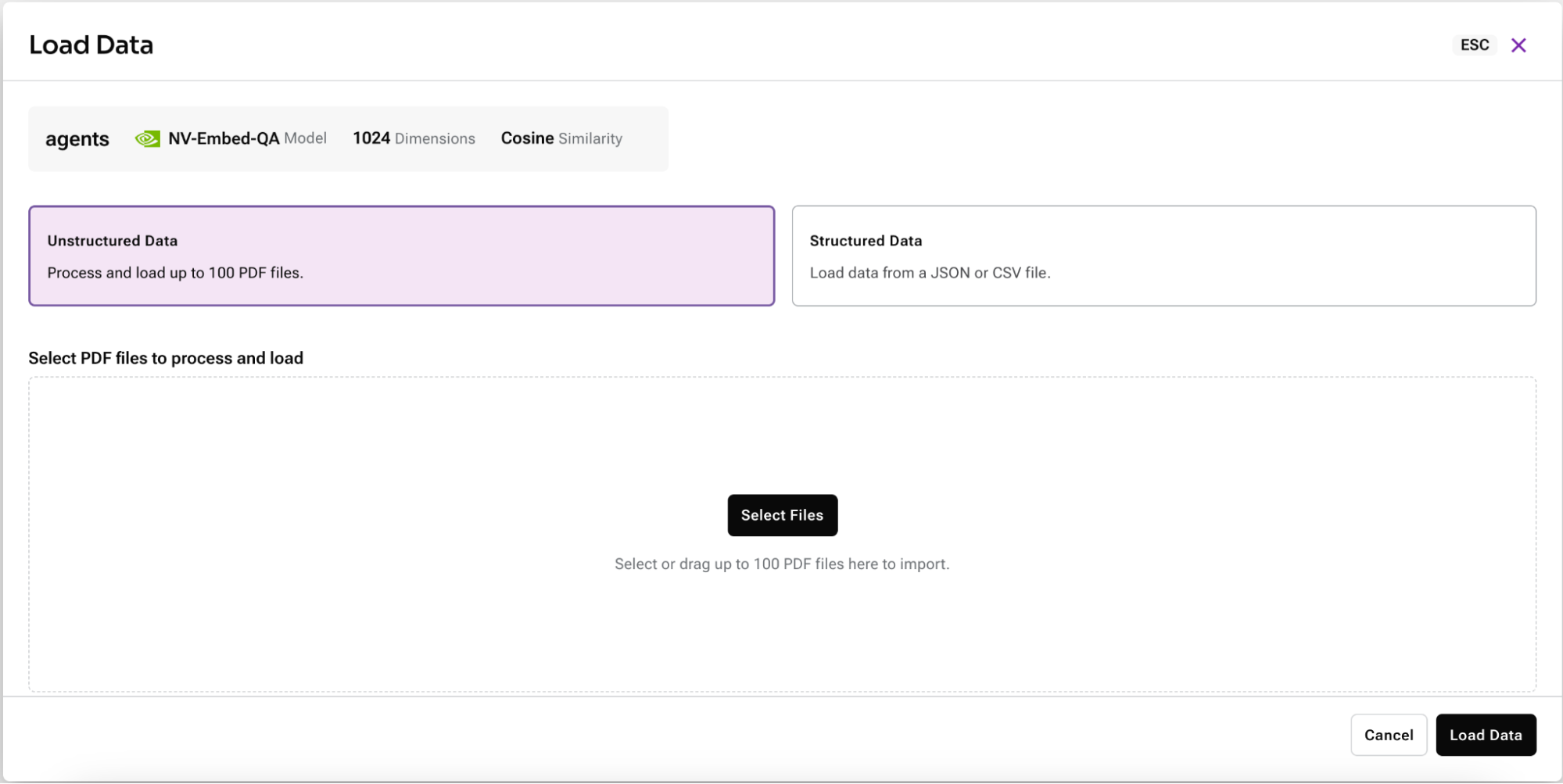
Astra Data Loader: Seamless PDF processing
The enhanced Astra Data Loader now supports PDF files, offering a streamlined process for ingesting unstructured data. The process is very simple, and handled entirely in the Astra DB portal. To kick off the upload process, simply log in to Astra and select your database. From the Data Loader choose "Load unstructured data" to upload one or more PDF files.
The process can handle files of any size. Then automated processing in the Data Loader handles everything else, leveraging Unstructured.io's capabilities to partition and chunk documents. If Vectorize is configured, embeddings are automatically generated with your preferred provider. Your data is available immediately. Browse and query your processed data and embeddings directly in the Data Explorer.
This enhancement simplifies what was once a complex, multi-step process into a few clicks within the Astra DB portal.
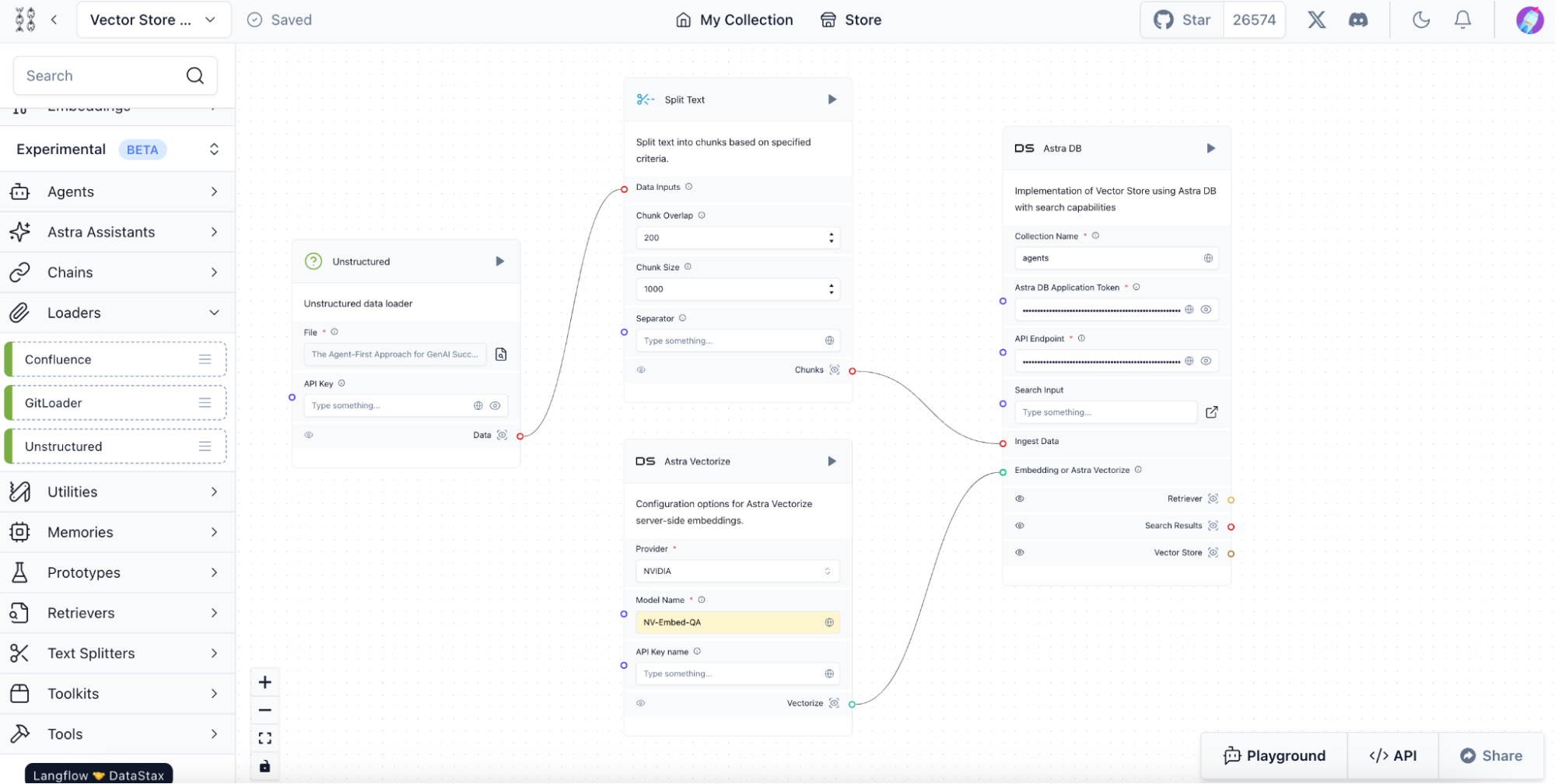
Langflow Unstructured component: Flexible document ingestion
For developers using self-managed Langflow, our low-code development platform built on LangChain, we're introducing a new Unstructured component:
- Broad file support - Upload a variety of file types, including PDFs, images, videos, Word documents, and PowerPoint presentations.
- Cloud or local processing - Use your Unstructured API key for cloud processing, or leverage a local Unstructured installation.
- Seamless integration - Easily store the processed JSON output in Astra DB and use it in your GenAI applications.
This component enables developers to incorporate advanced document processing into their self-managed Langflow applications with flexibility and ease.
Empowering developers
These integrations address a critical pain point in the GenAI development process. By simplifying data preparation and ingestion, we help developers to:
- Focus on innovation rather than data-processing challenges
- Efficiently handle large documents and a wide variety of file types
- Improve search relevancy through better document chunking and embedding generation
- Accelerate the development of RAG applications
By bringing powerful document processing capabilities directly into our platform, we're enabling developers to focus on what matters most: creating innovative, intelligent applications that drive business value.
We invite you to explore these new features and experience firsthand how they can accelerate your generative AI development process. Read more about our Unstructured integrations, or visit the Astra Data Loader docs and the Langflow docs to get started.
The future of generative AI is here, and with Astra DB, it's more accessible than ever.
Register now for the upcoming livestream, “Getting Your Data AI-Ready with Unstructured and DataStax.”




