

The seamless integration between Cassandra and Solr that is provided by DataStax Enterprise (DSE) allows Cassandra columns to be automatically indexed by Solr through its secondary index API, as the picture below (click to enlarge) from DataStax Enterprise Documentation:
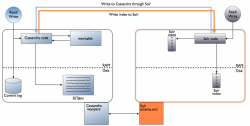
Each insert or update of a Cassandra row triggers a new indexing on Solr, inserting or updating the document that corresponds to that Cassandra row. This work is done automatically on the behalf of the inserts, updates and deletions of rows (a deletion will automatically remove the corresponding Solr document). There is usually a direct mapping between Cassandra columns and Solr document fields.
There are, however, cases where we may want to map a single Cassandra column to multiple Solr document fields. This requires some pre-processing hooks to modify the Solr document before the proper indexing takes place on Solr side. To address this requirement, DSE provides two classes -- FieldInputTransformer and FieldOutputTransformer -- that can be extended to allow the developer to plugin code that will customize the Solr document just before indexing.
To illustrate its use, let's assume that we need to store a JSON object as a text field in the CQL3 table below:
| id | json |
|---|---|
| 1 | '{"city":"Austin","state":"TX", "country":"USA"}' |
| 2 | '{"city":"San Francisco","state":"CA", "country":"USA"}' |
| 3 | '{"city":"Seattle","state":"WA", "country":"USA"}' |
Even though we store the JSON object as a text field into Cassandra, we would like to have the ability to index and query individual JSON fields on Solr. So, let's begin our walkthrough example by creating a keyspace, called solr_fit, and our example table, called cities:
|
|
As we can see above, the whole JSON object is represented by a single Cassandra column.
1. Project Setup
To develop the FIT extension we'll need dse.jar to be on the classpath of our FIT plugin project during compilation. Either we can point to it from within your IDE (Eclipse, Netbeans, etc) or create a Maven based project. If the FIT project is based on Maven, as the example here, then the developer needs to install dse.jar as a local maven dependency, as it's not in available at DataStax (or any other) maven repo. This can be accomplished by the following command on terminal:
|
|
This will install the jar as a Maven dependency under the developer's $HOME/.m2/repository. Then we can add the following dependency to our pom.xml:
|
|
The same needs to be done with DSE's lucene-solr jar located at $DSE_HOME/resources/solr/lib/solr-4.6.0.3.4-SNAPSHOT-uber.jar, so that we can add the dependency as below:
|
|
|
|
Further details about Maven based projects can be referenced at the official site: http://maven.apache.org. Once the project is compiled, we should copy the compiled jar of our project to $DSE/resources/solr/lib/ of each DSE node that is part of our Solr cluster. For development purposes, a single DSE node is enough.
2. Project files
On the Solr side, we need create a schema.xml and solrconfig.xml file. Let's start with the former. In this schema we specify the individual fields that compose the JSON object besides the fields defined in the Cassandra table. As we can see below, the individual JSON fields were specified as fields to be indexed by Solr even tough those fields (city, state, country) don't exist in the respective Cassandra's table nor are available as Solr copyFields.
|
|
The corresponding solrconfig.xml should include the following top-level tags that specify the full qualified name of our custom classes in charge of parsing the Cassandra column.
|
|
In this example, our json object is serialised and unserialised as a Java object called City, a simple POJO. Below is its class definition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
The FieldInputTransformer and FieldOutputTransformer classes must be extended to define a custom column-to-document field mapping like the one in our JSON example. FieldInputTransformer takes an inserted Cassandra column and modifies it prior to Solr indexing, while FieldOutputTransformer parses a Cassandra row just before returning the result of a Solr query.
3. FieldInputTransformer
The code below shows our custom FieldInputTransformer. We should override two methods: evaluate() and addFieldDocument(). The first one checks if the column should be parsed or not by looking at the column name. If it returns true then addFieldDocument is called to transform the Cassandra row into a Solr document to be indexed. We are using Jackson at line 42 to parse the Cassandra text field column into a City object. Lines 29 to 32 we retrieved Solr schema fields that we need to specify during indexing. Finally, at lines 34 to 35 we insert each field into the Solr document.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
|
4. FieldOutputTransformer
The corresponding FieldOutputTransformer code should override one of the Field methods (where is string, int, float, etc). In our example, we override the stringField method only as this is the original field type of the "json" field in the CQL3 table. In this method we receive the original value of the row as raw text and parse it as we did in JsonFieldInputTransformer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
Both these classe are compiled, packaged and copied into $DSE_HOME/resources/solr/lib/.
5. Schema Creation
To create a Solr core, we need to upload schema.xml and solrconfig.xml resources, as shown below:
|
|
After uploading the Solr resources and creating the core we can check the schema via Solr admin UI by accessing the following URL: http://localhost:8983/solr/#/solr_fit.cities/schema
6. Execution
Now, let's insert some example data into cities table:
|
|
This feature allows the searching for individual fields (city, state, country) from both Solr HTTP interface as well as CQL.
As we can see below, a simple CQL3 query shows that the JSON document is stored in a single Cassandra column:
|
|
Things start to get interesting when we use the solr_query facility to retrieve the rows matching a single field of the JSON document as the example below. Let's start by querying the cities table using a solr_query expression. The first query retrieves all the rows from the cities table whose country is USA:
|
|
The second query retrieves cities whose name start with Seat:
|
|
Finally, let's query the cities in the California state:
|
|
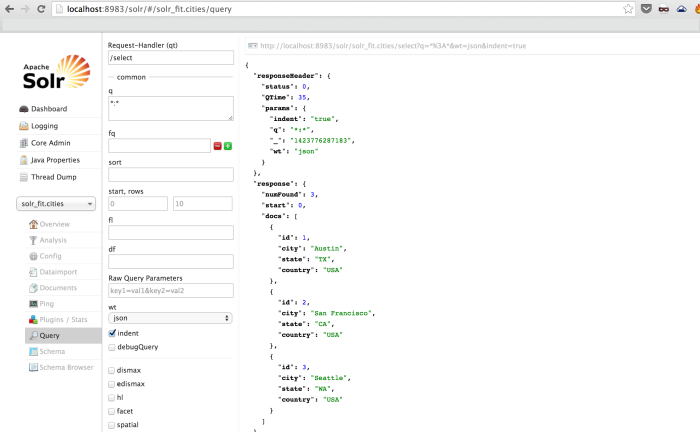
We can see the same queries can be executed by the Solr admin UI. Below we see the retrieval of all the sample rows:
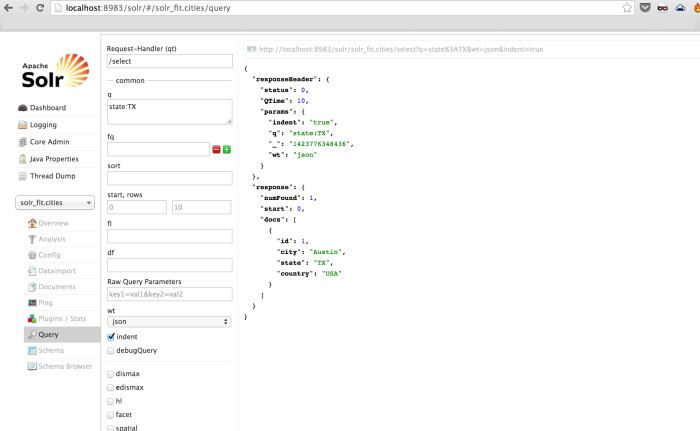
This example shows the recovery of a single field as above:
7. Debugging
For debugging and development purposes, it's recommended to rely on logging facilities of a single DSE node. Log messages should appear in /var/log/cassandra/system.log.
8. Conclusion
This blog introduced a flexible way of pre-processing Cassandra rows that are indexed as Solr documents by DSE. The approach shown in this post can be used to parse binary files too, like the example bundled with DataStax Enterprise.






