
When building a retrieval-augmented generation (RAG) system, you want to achieve highly relevant results to queries. This helps to provide the best context to a large language model to synthesize a result. One option when trying to improve relevance is to use alternative methods of scoring.
In this post, we’ll explore using a method called ColBERT to improve retrieval in your RAG application.
Common issues with RAG
The basic RAG application turns input text into chunks, uses an embedding model to generate vectors for each chunk, and stores them in a vector database like Astra DB. Data is then retrieved by using the same embedding model to generate a vector for a query and searching the vector database for the most similar data chunks using a similarity metric like cosine similarity.
This can be very powerful, but some issues can arise:
-
Unusual terms, like names, that aren't in the training data for an embedding model make it hard for the model to accurately represent the terms within the vector
-
Getting the chunking strategy wrong can result in loss of context, leading to poor search results. Turning one passage of text into a vector is an attempt to squash all the meaning in the passage into a single vector and that can be sensitive to the way data is chunked.
In practice
I recently spoke about this at the AI Engineer World's Fair and wanted a way to demonstrate this issue. I gathered all the conference session descriptions and stored them in Astra DB using the OpenAI text-embedding-ada-002 model to generate vectors for the content. I built a simple interface to search and display the results. I then tried several searches on uncommon terms in the data.
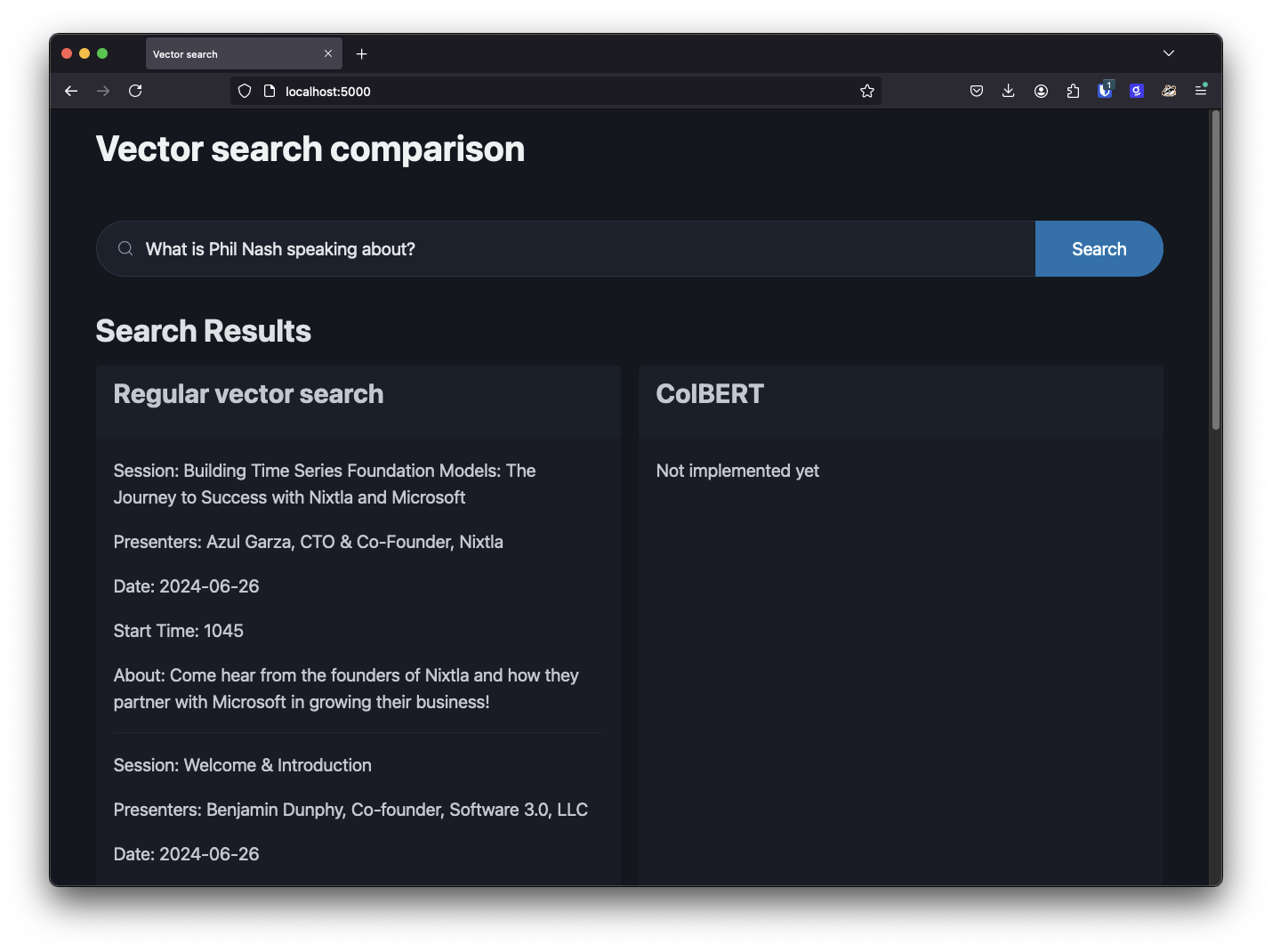
After trying several unusual terms, it turned out that asking about my own session resulted in search results that weren't relevant. I guess that shouldn't have surprised me—ask ChatGPT 3.5 about me and it describes someone else. In this context, "Phil Nash" is an unusual term.
I tried this with a few other speaker names; for some the results were good, and for others, the relevant session wasn’t found. It's important to note that we are working with a similarity search here, not keyword search, but if you were building a chatbot that could tell you about the conference, these results wouldn't be very helpful.
What can we do about this?
An alternative way of vectorizing and retrieving the data is a method called Contextualized Late Interaction over BERT (ColBERT). ColBERT was first described in a paper in 2020, followed in 2021 by a paper on on ColBERTv2.
Instead of turning a passage of text into a single vector, ColBERT uses Google's open source BERT model to create a vector for each token in a piece of text. Tokens represent words or parts of words; models like BERT learn to understand the relationships between tokens. OpenAI has a good demonstration of how a sentence can be turned into tokens.
BERT is a contextual model, when it creates a vector of a single token, it takes into account the tokens before and after this token. This enables the creation of a sliding window of context for each token. This turns out to capture much better context for terms that weren't part of the training data.
In practice, this generates vectors of 128 dimensions for each token in a piece of text. In the implementation you'll see below, this data is stored in Astra DB by storing the original text in one row, followed by a row for each token and vector associated with that text.
For retrieval, we use the same process on a query then compare against the document embeddings in the database. Rather than go into depth on exactly how this works in this article, I recommend you read Jonathan Ellis's article on overcoming the limits of RAG with ColBERT which breaks down how to do this in Python and CQL.
Instead, for the rest of this post we'll look at how you can put ColBERT into production using Astra DB.
Implementing ColBERT with Astra DB
DataStax has implemented ColBERT search in Astra DB through both LangChain and LlamaIndex. Here's how you would use ColBERT through LangChain.
Using ColBERT in a Python application
To use this in your application you will need an DataStax account and an Astra DB database. Once you have the database, grab the database ID and an application token.
In a Python application install the LangChain RAGStack variant and the ColBERT implementation:
pip install ragstack-ai-langchain ragstack-ai-colbert
To ingest your data, you'll need a list of texts that you want to embed. You create a ColbertEmbeddingModel, a CassandraDatabase and put them together to create a ColbertVectorStore that works like any other vector store in LangChain. You can then ingest the text by passing your texts to the vector store.
from ragstack_colbert import CassandraDatabase, ColbertEmbeddingModel, ColbertVectorStore
embedding = ColbertEmbeddingModel()
database = CassandraDatabase.from_astra(
astra_token=YOUR_ASTRA_DB_TOKEN,
database_id=YOUR_ASTRA_DB_ID,
keyspace="default_keyspace"
)
vstore = ColbertVectorStore(
database=database,
embedding_model=embedding
)
results = vstore.add_texts(texts=YOUR_LIST_OF_TEXTS, doc_id="myDocs")To search against this ColBERT enabled vector store, you need to set up the database in a similar way, though in this case importing the ColbertVectorStore from the LangchainColbertVectorstore, and then perform a search as you normally would with a LangChain vector store.
from ragstack_colbert import CassandraDatabase, ColbertEmbeddingModel
from ragstack_langchain.colbert import ColbertVectorStore as LangchainColbertVectorStore
colbert_embedding = ColbertEmbeddingModel()
colbert_database = CassandraDatabase.from_astra(
astra_token=YOUR_ASTRA_DB_TOKEN,
database_id=YOUR_ASTRA_DB_ID,
keyspace="default_keyspace"
)
colbert_vstore = LangchainColbertVectorStore(
database=colbert_database,
embedding_model=colbert_embedding
)
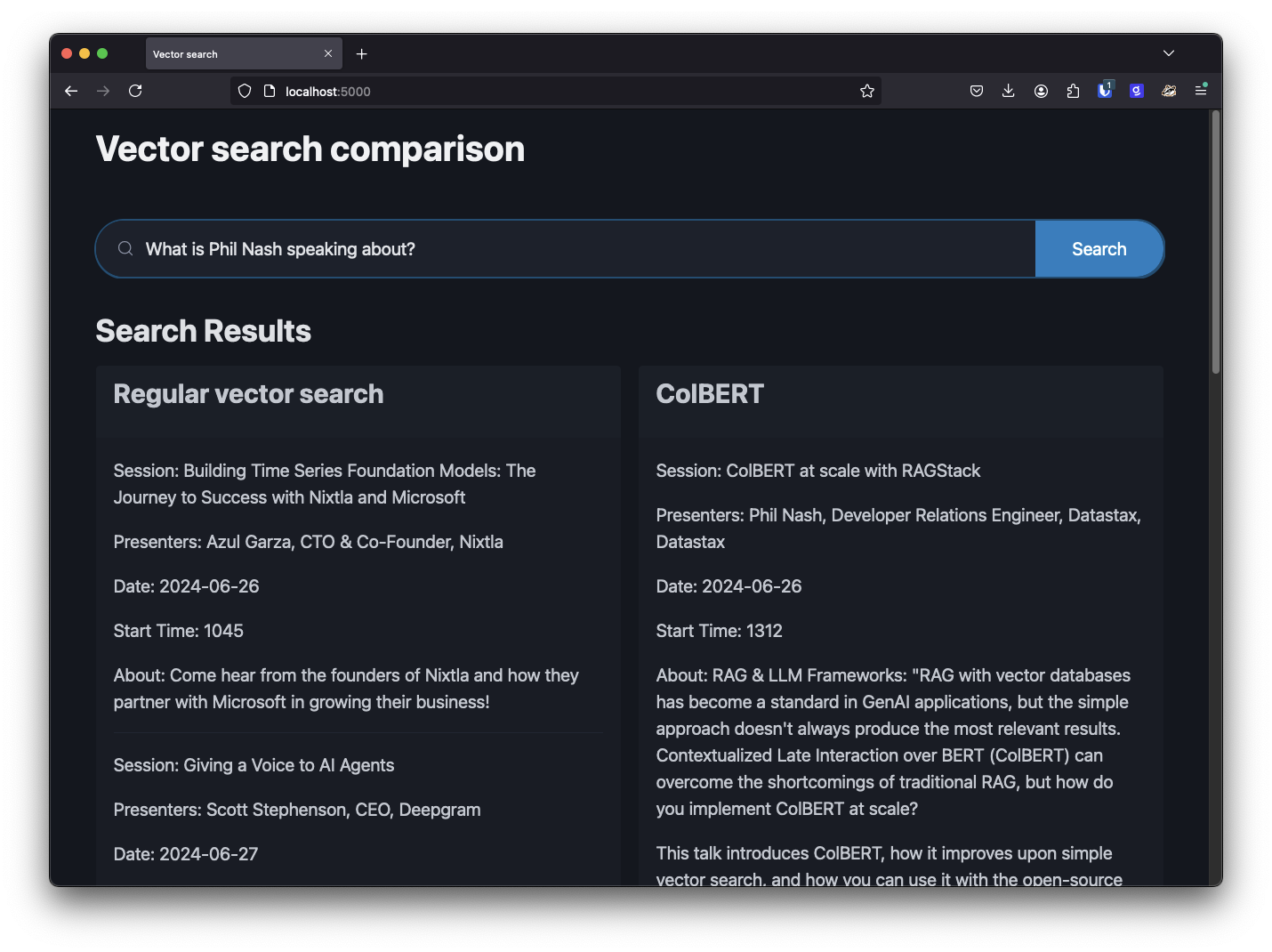
query = "What is Phil Nash speaking about?"
results = colbert_vstore.similarity_search(query)When I implemented this in the example application the results were much more relevant, and feeding the results to a language model would have resulted in an accurate generated response.
Drawbacks
ColBERT does provide greater accuracy than regular vector search, particularly around unusual terms or names. It also overcomes issues with chunking strategies with the sliding window of context that makes it easier to match a query against a passage. But, as in anything in software development, there are trade-offs:
-
Size - Because we store a vector for each token in a document, ColBERT requires a lot more storage capacity. Each stored vector is 128 dimensions, but we require a vector per token. For a dataset with 10 million passages (which is ~25% of the English-language Wikipedia), the OpenAI-v3-small model requires 61.44GB, while the ColBERT model requires 768GB. So storage is at least an order of magnitude more.
-
Latency - To narrow down the results we perform a similarity search for each vector in the query. And then we must rank the results using ColBERT's scoring mechanism. All of this is a lot more work than a single vector search against an index. So ColBERT is likely to take longer than regular vector search.
If either the speed of retrieval or keeping storage costs down are the most important thing to your application, then ColBERT is likely not the right solution for you. However if accuracy and relevance in your retrieval is, then I would recommend exploring ColBERT.
Conclusion
ColBERT is a highly accurate retrieval option you can use when building your RAG systems. It's available in Astra DB through both LangChain and LlamaIndex. If you need greater accuracy and can handle the increased storage and latency, ColBERT might be the solution for you.
Check out the code to the example application on GitHub and try it out yourself. If you're looking for more on how to use ColBERT, take a look at the documentation for using ColBERT with Astra DB.









