

Langflow, DataStax’s drag-and-drop IDE, offers an intuitive, low-code approach to building PDF chatbots that can understand and answer questions about your documents. This powerful, open-source tool is accessible to both beginners and experienced developers. Here’s a quick look at how easy it is to build an app that enables you to chat with PDFs.
Setting up your PDF chatbot
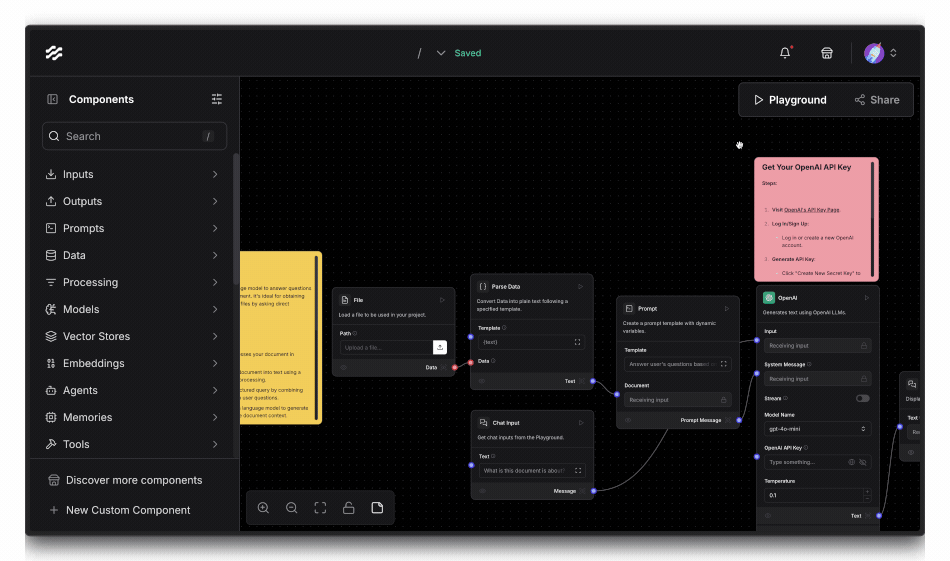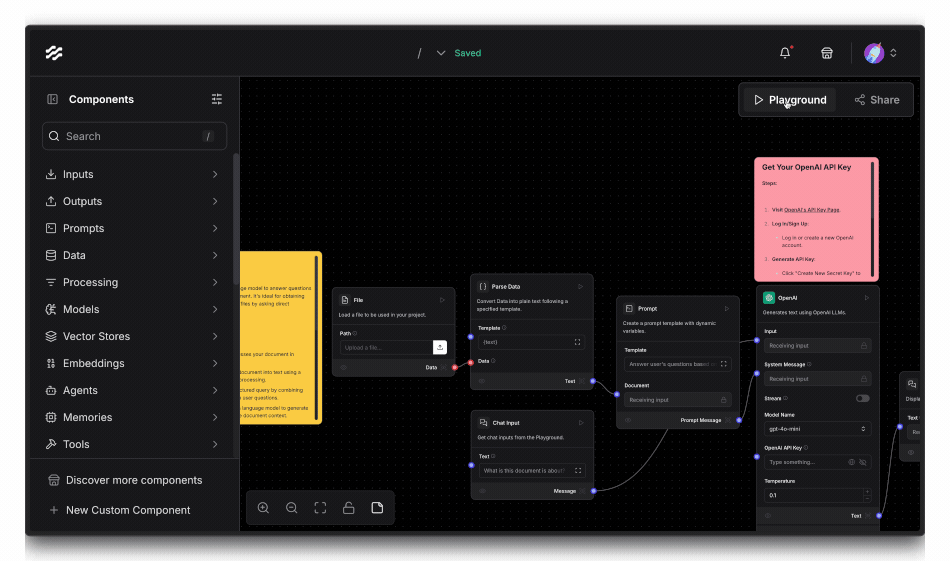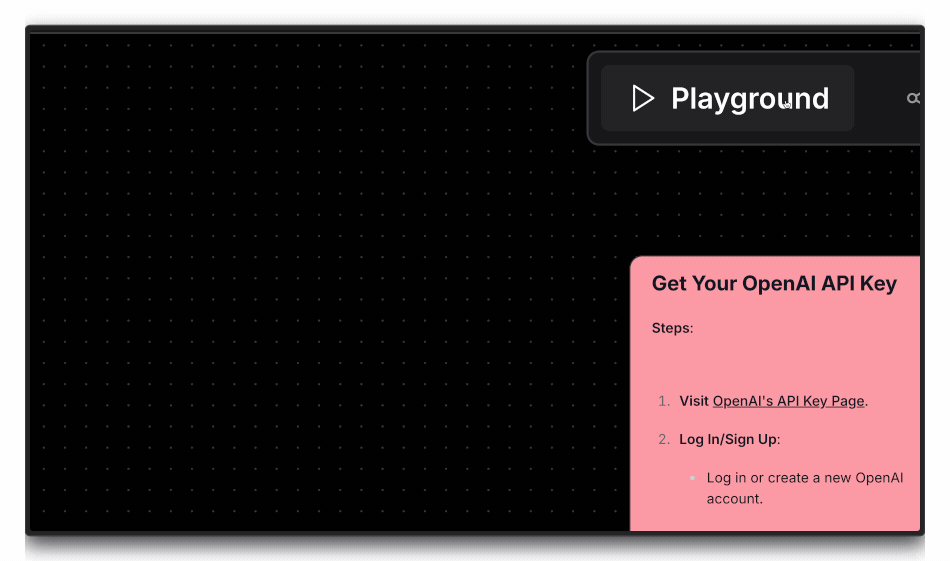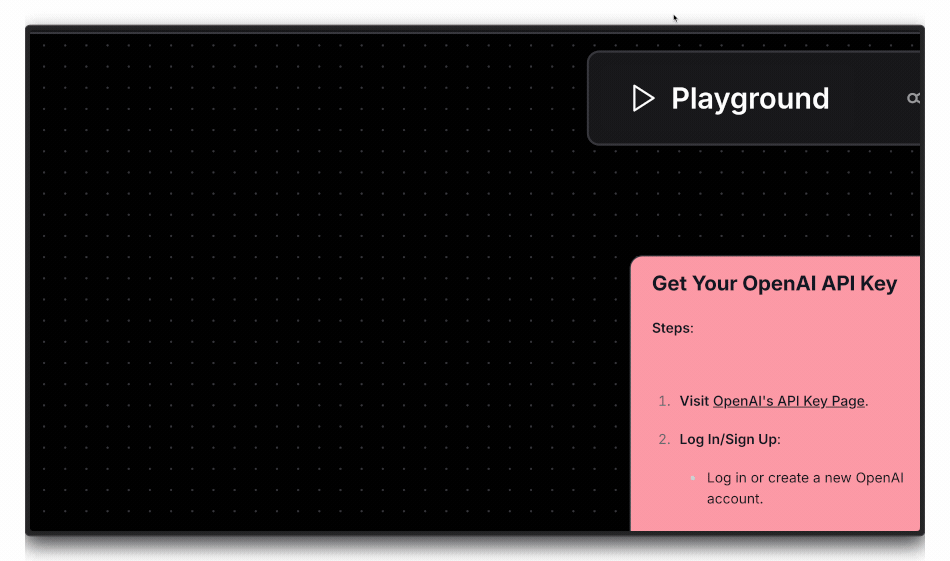
Sign up for Langflow and create a new project. Then, navigate to “All Templates”, and select the Document Q&A template to begin. The platform provides a visual workflow creator where you can assemble your chatbot's components without writing code.
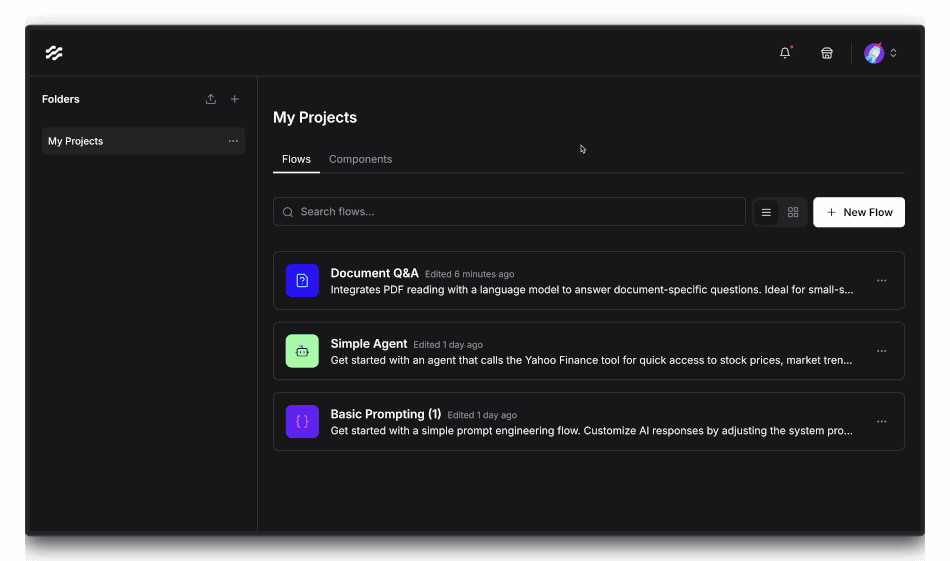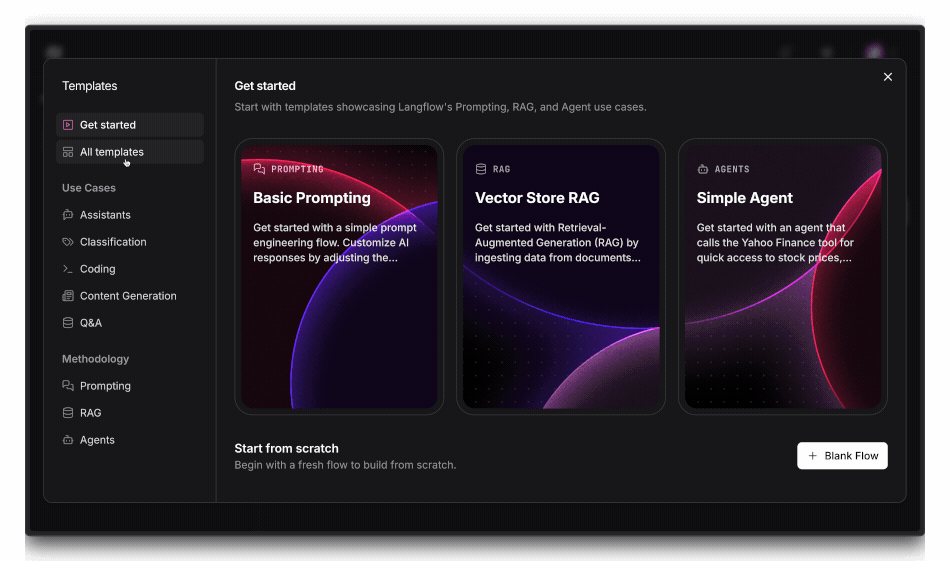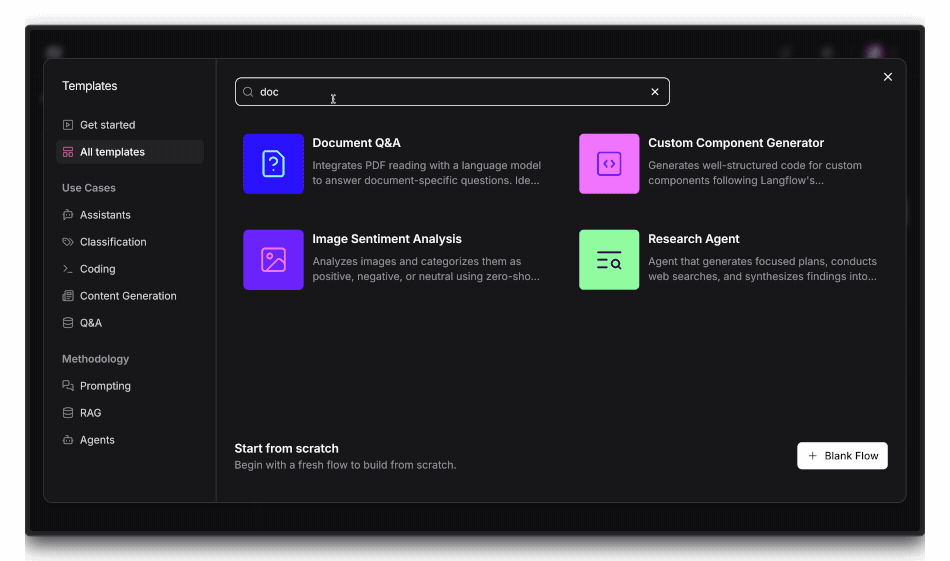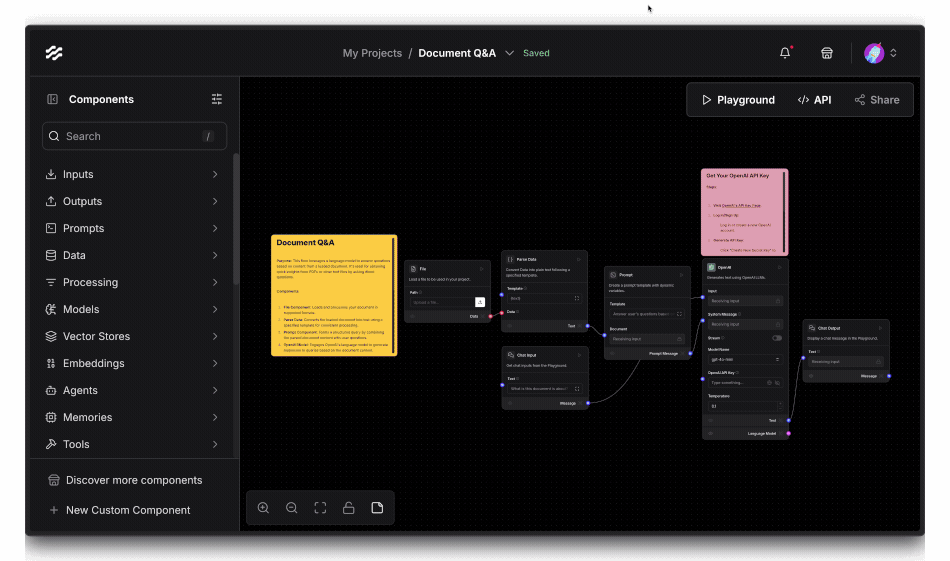
The Document Q&A flow contains the following components:
- File - Handles PDF document upload and processing
- Parse Data - Turns the PDF content into text for the next step
- Prompt - The prompt we send to the language model
- Chat Input - The question for the user
- OpenAI (or any other LLM provider) - The Language Model that generates the answers, and finally
- Chat Output - A component to render the answer
Once you add your appropriate API keys to the flow, you can immediately start chatting with your PDF by clicking the Playground button.
Key features
While this flow works quite well for most PDFs, you could go even further using the Unstructured Langflow component and work with key elements within your PDF including titles, paragraphs, and tables. You can customize text extraction settings for complex documents containing images and varied formatting.
Interaction capabilities
Your chatbot can:
- Answer specific questions about PDF content
- Maintain context through Langflow’s powerful conversation memory support
- Be exposed over an API for any application user interface
- Function as an AI agent using context from your document
- Next steps
Once you’re happy with your flow, you can continue to chat with your PDF in the Langflow playground, or integrate it into an frontend user interface: this exact flow will run deterministically via an HTTP API. To use this feature, click the API button right next to the playground button as highlighted above.
Taking it further
Now that we’re familiar with a basic PDF chat setup with Langflow, we can take things further by storing the contents of PDFs and other documents in our flagship vector database Astra DB, and retrieving only the portions of content that semantically match a user’s query using vector search. Stay tuned for that in an upcoming post.
Happy coding!











