Ever wondered how ChatGPT seems to know about recent events? The secret sauce is “retrieval-augmented generation”—more commonly referred to as “RAG.” Around 86% of organizations are already adopting RAG to enhance their AI systems, as building one doesn't have to be complex or expensive.
In this article, we’ll build a RAG system using an open-source tool, Langflow, and show you how to use Astra DB as the vector store.
Understanding retrieval-augmented generation (RAG)
RAG is like giving your LLM a personalized knowledge base. Instead of relying solely on pre-trained knowledge, RAG systems fetch relevant information from your data in real-time. This means more accurate, up-to-date responses and fewer hallucinations.
RAG-enabled pipelines are a cost-effective approach to developing LLM applications that provide current, relevant information. RAG pipelines can also handle diverse use cases by accessing different knowledge bases, from internal documents to external sources. This flexibility makes them suitable for a wide variety of business applications.
Building a RAG-enabled pipeline
A simple RAG system consists of five stages: text embedding model, LLM, information retrieval, ranking, and response generation. All of these steps rely on vector databases, so that's where we’ll start.
To build a RAG-enabled pipeline, we first start by setting up our vector database on Astra DB:

This is where we’ll save the documents that we want our LLM to reference. Astra DB has multiple third-party integrations that allow for vector embedding generation directly from unstructured data. This is super useful as it removes the additional step of figuring out the right embedding models and tuning other parameters. For this example, we’ll set up a vector-enabled collection with NVIDIA's open-source embedding model and a dimension of 1024.

With these in place, we can now use Langflow to create a RAG-enabled pipeline. Sign into Langflow and choose the "Vector Store RAG" template:

Data preparation
The foundation of any RAG system is good data. Before we can start to ask our LLM about our documents, we need to load our documents into the vector database we made earlier.
Zoom into the template and find the "Load Data" flow. Then, upload your file(s) into the "File" block. For demonstration here, we are using the 10-K annual report for AAPL (download here).
These uploaded files will then feed into a "Split Text" block which performs chunking on the documents. Chunking is a strategy to reduce the complexity and diversity of large data, dividing the data into smaller chunks based on token size.
Embedding model
Once the documents have been loaded and chunked, the next step is to load them to the vector database and save their vector representations. Since we are using Astra DB, we can remove the "OpenAI Embeddings" components.
On the "Astra DB" component, choose the database and collection created earlier, then choose "Astra Vectorize" and "NVIDIA." Then, click the "Run" button in the Astra DB component to run all the steps.

Going back to Astra DB and exploring the data, we can see the updated collection:

If you’ve made it this far, great! We’re done with the most tedious steps of setting up a RAG pipeline. In a production environment, these initial steps of loading documents and turning them into vectors is the most challenging part. Thankfully, Astra DB and Langflow make it extremely easy to get started.
User query handling
Back to Langflow, we’ll now make a few edits to the "Retriever" flow. This flow will control the behavior of execution when a user asks a query. Our objective is to create a pipeline that:
- takes a user query
- converts it to embeddings
- retrieves relevant documents by performing cosine similarity
- generates a response using large language models (LLMs) from Groq (grab an API key here)
As before, we can remove the "OpenAI Embedding" component and update the Astra DB component with the defined database and collection names. This time, however, we’ll connect the "Chat Input" edge to the "Search Input" edge. Internally, this tells the execution environment to pass whatever is asked by the user into the retrieval model, find the relevant document chunks, and provide them as the "Search Results" edge.
This edge then connects to the "Parse Data" and "Prompt" components where we can optionally perform prompt engineering. Then, we set up our LLM. If you want to use an open-source LLM, find the "Groq" component under "Models" and put it in between the "Prompt" and "Chat Output" blocks. Paste your "GROQ_API_KEY" and choose the model.
Langflow offers multiple large language models that you can swap out depending on use case.

RAG pipeline testing
To test out the pipeline, let's ask the model about the top selling products for Apple in 2024 and how it compares to 2023 numbers:
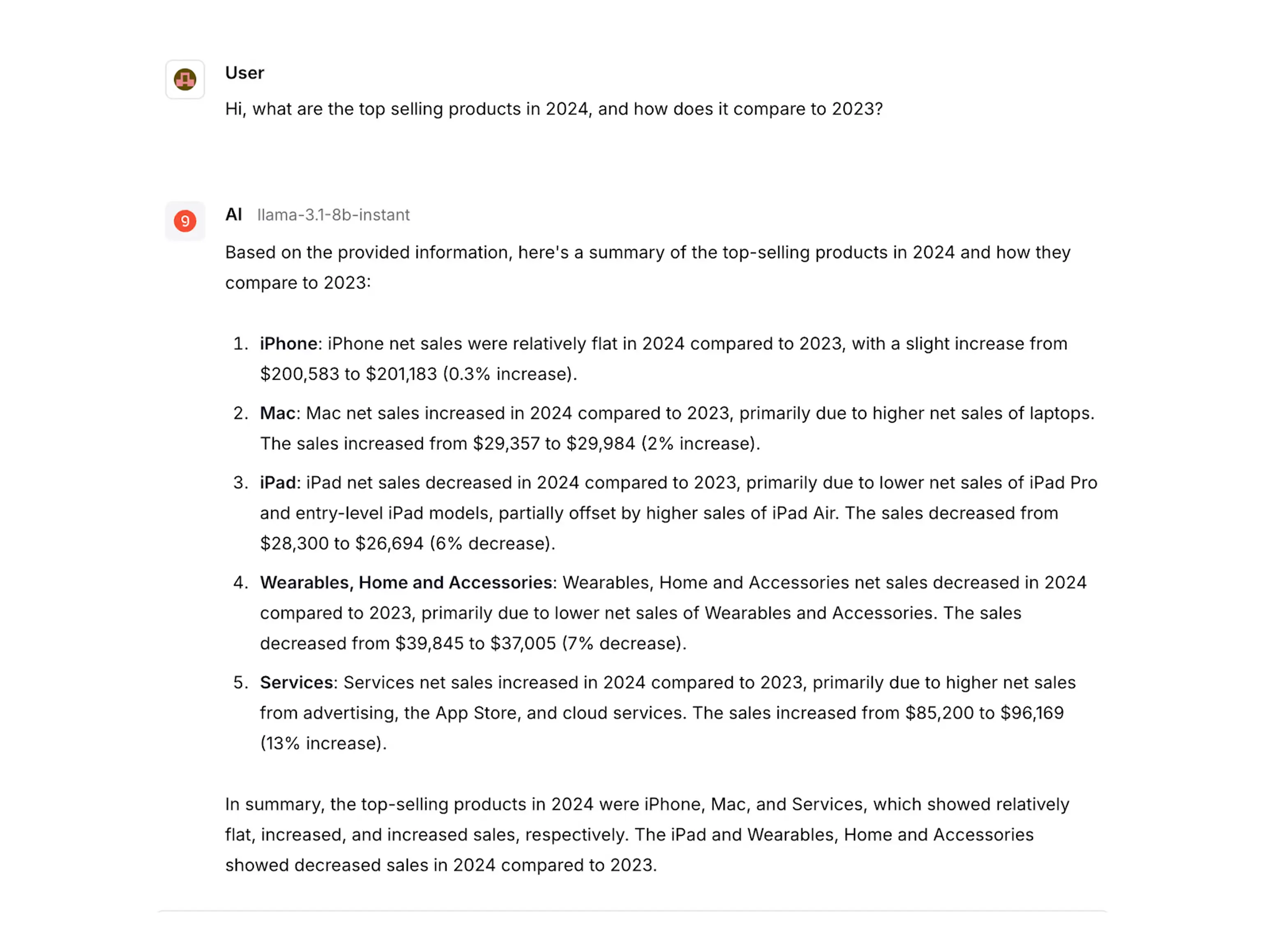
As we can see, the model provides a detailed answer from the 10-K we uploaded earlier. Congratulations, you've just built a RAG-enabled pipeline using open-source models.
Start building apps with RAG-enabled pipelines
Building a RAG system with Astra DB and an open-source tool like Langflow is a powerful, cost-effective way to create intelligent applications. While the initial setup might seem complex, the combination of Langflow's visual interface and Astra DB's managed service significantly simplifies the development process.








