
If you’re thinking about embarking your first adventure in generative AI, you might be wondering where you start. GenAI has opened up a host of new and exciting use cases for developers. By now you've probably seen your fair share of chat bots, but you can use GenAI to build intelligent agents, content creation experiences with text/audio/video, synthetic data, language translation and so much more.
Underpinning most of those experiences are something called vector embeddings. Vector embeddings are the assembly language of AI and they are how you go from a natural language query like "Who wrote the Hitchhiker's Guide to the Galaxy" to the correct response of "Douglas Adams". Vector embeddings allows developers to operate on unstructured data, whether it's coming from the user in the form of a prompt or coming from documents, PDFs and files that form the knowledge base that you're building your app on.
In this post, we'll explore vector embeddings, what they are, and how they fit into building GenAI apps. Let's get started on our journey into the galaxy of GenAI by examining what is used to generate vector embeddings in the first place: unstructured data.
First stop: Unstructured data
There are generally two types of data: structured and unstructured. Structured data is what most developers work with every day, whether it's a variable in your code or a field in your database. This data is often typed (numbers, strings, dates, etc) and modern databases are very good at efficiently storing and querying this kind of data. Developers have been building apps on top of structured data for decades and the tools and best practices are pretty baked.
Unstructured data, on the other hand, represents everything else: documents, articles, web pages, videos, and audio – you name it. Google, famously, built one of the first large-scale consumer applications that operated on unstructured data (web pages) and had to more or less build completely new technology to power their search engine.
GenAI applications also rely heavily on unstructured data. If you're building a modern search engine that understands natural language queries, you'll need to be able to operate on the documents or knowledge base that your users are trying to get insights from. Building most GenAI apps will involve taking your unstructured data, storing it in a database, often together with structured data, and then retrieving it based on a user's request. On retrieval, you want to be both fast and to return only the most relevant information.
Ensuring accurate, efficient retrieval is a major challenge that arises with unstructured data. It’s essential for GenAI applications, especially those that rely on retrieval-augmented generation (RAG). Reducing query time and maintaining loose data relationships are key factors in retrieval efficiency, but traditional data stores often lack the necessary capabilities or are just too slow to meet these demands. Ultimately, it all comes down to the indexing of the data. So how do databases handle the indexing of unstructured data?
Next stop: Vector embeddings
The main challenge with unstructured data is that it can be virtually anything. There is no predetermined set of formats and data types, so it’s impossible to come up with a generic algorithm to index such data.
The primary way to get around this problem is to introduce an intermediate state the data is converted to before being understood and indexed by a database. In this intermediate state, unstructured data is represented as vectors (or arrays) of floating-point numbers. We call these vectors “embeddings.”
One way to think about embeddings is that they’re a representation of your data in a multidimensional space. Pieces of content that are semantically similar to each other will reside close to each other in this space.
As a simple example, let’s say we want to map the following set of words into a 2-dimensional space:
- Sheep
- Cow
- Pig
- Tiger
- Coffee
- Tea
The result could look something like this:
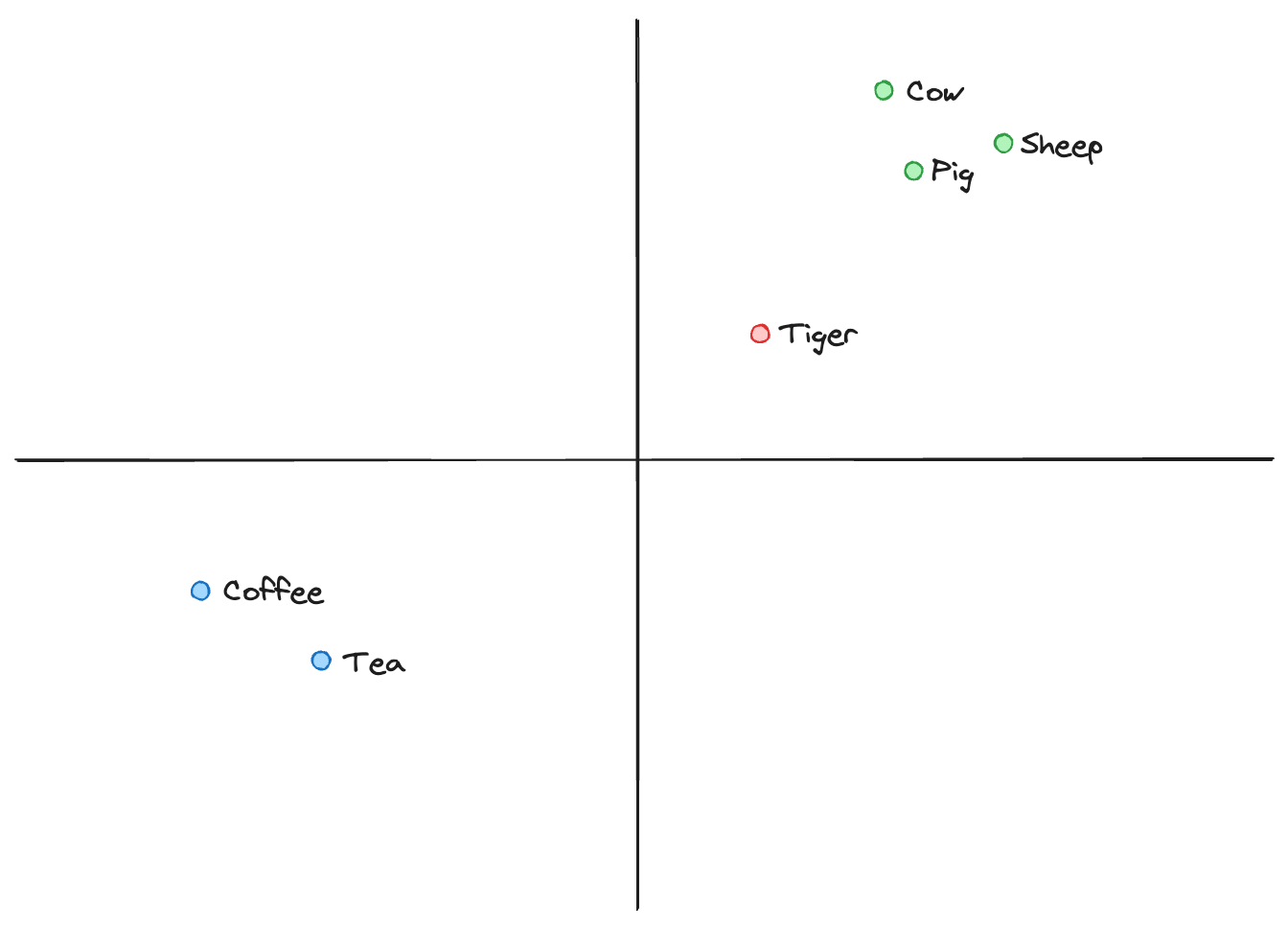
Cow, sheep, and pig are all domestic animals, so there is very little distance between them. Tiger is a wild animal, so it’s located slightly away from the group of domestic animals, but it’s still an animal, so it’s not too far away. Conversely, coffee and tea end up in a completely different area of this 2-dimensional space.
You can now use this representation to find words that are semantically similar to your inputs. For example, to answer the question “What is similar to milk?”, you’ll generate a vector embedding for the word “milk,” compare it to vectors that already exist in the space, and find the closest ones. Milk is a drink, so the result is going to be near “coffee” and “tea.”
Now, in this case we have manually mapped these words onto this graph based on our intuitive understanding of the meaning of these words. In a real app, words are going to be replaced with larger pieces of content, the space will have hundreds or even thousands of dimensions rather than two, and we will need a way to automate the generation of these vector embeddings. How do we do this?
The Babel Fish: Translating to vector embeddings
When you're building GenAI apps, you'll use machine learning models to handle the conversion from unstructured data into vector embeddings. There are dozens (hundreds? thousands?) of machine learning models to choose from and they all generate vectors that form clusters based on how they were trained. There are models optimized for text, optimized for images and even models like CLIP that can handle both text and images!
One of the most popular providers for text embeddings models is OpenAI. Here’s some Python code to generate vector embeddings using OpenAI’s API:
from openai import OpenAI
client = OpenAI()
def get_embedding(text):
client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
text = "So long, and thanks for all the fish."
embedding = get_embedding(text)
print(embedding)This demonstrates how to use OpenAI’s API to convert a piece of text into its vector embedding. In this case we're using OpenAI's text-embedding-3-small model, but is that the right choice for every app?
A fork in the road: Choosing an embedding model
Haha, no! Every application is different and selecting the right embedding model is crucial for building a successful app that users love.
First and foremost, think about the relevance of the model to your specific use case. Not all models are created equal; some are fine-tuned for particular types of text or applications. If you're working with casual conversation data, a general-purpose model might suffice. However, if you are building an application for a specific domain where jargon and specific terminology are abundant, consider using a domain-specific model. Models specially trained for medical, scientific, legal, and other specific data are better equipped to understand and generate embeddings that accurately reflect the specialized language used in your field.
Consider the overall quality and robustness of the model. Look into the training data used, the size of the model, and its performance metrics. Many LLM providers provide benchmarks and comparisons that can help you make a decision.
Ultimately, the goal is to find a balance between relevance, language support, domain specificity, latency, and cost. By carefully evaluating these aspects, you can select an embedding model that not only meets the technical requirements of your application but also enhances its overall performance and user experience.
But once you have selected an embedding model and you're happy generating vector embeddings at scale, what do you do with them? And how does this fit into building GenAI apps?
Don't panic: Vector databases
Once you‘ve generated embeddings for your unstructured data, the next step is to store and manage these embeddings in a vector database. Vector databases are designed to handle the storage and retrieval of high-dimensional vectors, and they use advanced indexing techniques to ensure efficient operations.
When you add an embedding to the vector database, it indexes the vector to optimize for fast retrieval. This involves organizing the vectors into a structure that allows efficient nearest-neighbor searches. Think of it as arranging points in the multidimensional space we discussed earlier, where similar vectors are clustered together, making quick access possible when you search.
When you query the database with a new embedding, from a user query for instance, the database performs a nearest neighbor search to find the most similar vectors. The results are then mapped back to the original content, providing relevant information to the user.
For example, here is how you would interact with Astra DB to store documents and query them using vector search:
from astrapy import DataAPIClient
from openai import OpenAI
client = OpenAI()
def get_embedding(text):
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
# Connect to a database and create a collection.
client = DataAPIClient("your-astra-db-token")
database = client.get_database("your-astra-db-api-endpoint")
collection = database.create_collection("books")
# Insert several documents. Every document contains a book title and its description stored as a vector.
# We use get_embedding function introduced earlier to generate vectors.
collection.insert_many(
[
{
"title": "The Hitchhiker's Guide to the Galaxy"
"$vector": get_embedding("Arthur Dent is saved by his alien friend Ford
Prefect just before Earth is destroyed and embarks on a space adventure aboard the
spaceship Heart of Gold. Together with eccentric companions, they explore the cosmos,
uncovering the absurdities of life and the enigmatic answer to the ultimate question of
life, the universe, and everything: 42."),
},
{
"title": "It",
"$vector": get_embedding("A group of childhood friends in the town of Derry,
Maine, reunite as adults to confront a shape-shifting, ancient evil that takes the form
of a monstrous clown named Pennywise. As they face their deepest fears, they must defeat
the entity that has terrorized their town for generations."),
},
{
"title": "The Firm",
"$vector": get_embedding("A young lawyer named Mitch McDeere accepts a
lucrative job at a prestigious law firm, only to discover it is a front for the mob. As
Mitch uncovers the firm's illegal activities, he must navigate a dangerous path to expose
the truth and save his life."),
},
],
)
# Find the most relevant book based on an input.
collection.find_one({}, sort={"$vector": get_embedding("humorous sci-fi novel")})Notice that the user's query (humorous sci-fi novel) was converted into a vector embedding using the same function that was used when inserting the documents. By leveraging vector databases, you can ensure that your GenAI applications are capable of handling complex queries and retrieving relevant information quickly and accurately.
An interstellar shortcut: Vectorize
If you review the code above, you'll notice that we're making lots of calls to get_embedding, and whether you're making HTTP API calls to OpenAI or spending compute cycles running local models, you're adding low value lines of code and incurring networking and CPU overhead. Wouldn't it be nice if your vector database already knew what kind of embedding model you were using for your app?
Astra Vectorize has entered the chat.
As an application developer, what you mainly need from your database is the ability to insert and update your data, both structured and unstructured, and then retrieve it based on some inputs. Vectors and embeddings are an implementation detail of how the data is indexed and stored; manually building and maintaining these intermediate data structures isn’t where your focus should be.
Think of traditional databases. If you have a bunch of floating point numbers representing the prices of your products, you simply create a Float or a Double field in one of your collections or tables. Strings representing descriptions of those products? It’s a Text field. Sure, you may need some indexing configuration along with your data, but it’s generally not required and comes with sensible defaults.
The goal of Astra Vectorize is to provide a similar workflow for unstructured data, enabling you to perform CRUD operations directly with this data rather than with vectors generated elsewhere. In addition, Vectorize comes with out-of-the-box access to the NV-Embed-QA model by NVIDIA, which works well for many use cases. This model is hosted by Astra DB itself, so you don’t have to create any additional accounts or configure any external services. As a result, here is how easy it is to get started:
from astrapy import DataAPIClient
# Connect to a database and create a collection.
client = DataAPIClient("your-astra-db-token")
database = client.get_database("your-astra-db-api-endpoint")
collection = database.create_collection(
"movies",
service=CollectionVectorServiceOptions(
provider="nvidia",
model_name="NV-Embed-QA",
),
)
# Insert several documents. Every document contains a book title and its description store as a vector.
collection.insert_many(
[
{
"title": "The Hitchhiker's Guide to the Galaxy"
"$vectorize": "Arthur Dent is saved by his alien friend Ford Prefect just
before Earth is destroyed and embarks on a space adventure aboard the spaceship Heart of
Gold. Together with eccentric companions, they explore the cosmos, uncovering the
absurdities of life and the enigmatic answer to the ultimate question of life, the
universe, and everything: 42.",
},
{
"title": "It",
"$vectorize": "A group of childhood friends in the town of Derry, Maine,
reunite as adults to confront a shape-shifting, ancient evil that takes the form of a
monstrous clown named Pennywise. As they face their deepest fears, they must defeat the
entity that has terrorized their town for generations.",
},
{
"title": "The Firm",
"$vectorize": "A young lawyer named Mitch McDeere accepts a lucrative job at
a prestigious law firm, only to discover it is a front for the mob. As Mitch uncovers the
firm's illegal activities, he must navigate a dangerous path to expose the truth and save
his life.",
},
],
)
# Find the most relevant movie based on an input.
collection.find_one({}, sort={"$vectorize": "humorous sci-fi novel"})This example is very similar to the previous one, but with two major differences:
- When creating the collection, we instructed Astra DB to use NVIDIA’s embedding model to generate vectors. That’s all you need to do to enable Astra Vectorize.
- When inserting and querying the data, we worked with text data, without a need to manually convert it into vectors. Astra DB takes care of embedding generation for you, making sure the same model is consistently used for all the requests.
Should you ever want to switch to another model, Vectorize natively integrates with most of the major embedding providers out there–no need to change the code, just update the configuration and you are good to go!
Recapping our journey
Ok, we just went on a whirlwind tour of getting started building GenAI apps. Let's review what we learned:
- GenAI opens up some amazing new use cases for developers, from chatbots to content creation to language translation. And we're just scratching the surface.
- These experiences are made possible by unlocking unstructured data: PDFs, web pages, media files, natural language queries and more.
- Machine learning models are used to translate this unstructured data into vector embeddings, which embed the semantic meaning of the data into n-dimensional coordinates where similar content gets clustered together.
- Vector databases are designed to store and index these vector embeddings and make it possible to run queries that, given an input vector embedding, will rapidly and efficiently find the nearest other vectors, or in other words, the other similar content.
- Astra DB has a feature called Vectorize that enables developers to remove the need to deal with vector embeddings from their code and offload that responsibility to the database.
As you continue your journey building apps with GenAI, stay tuned for our next post on evaluating LLM providers and their embedding models. We'll dig into several of the most popular models and discuss what they are optimized for and how to think about their cost/relevance/speed trade offs. Until this, happy hacking and we can't wait to see what you build using Astra DB!






