

A few weeks ago we decided to move our Spark Cassandra Connector to the open source area (GitHub: datastax/spark-cassandra-connector). The connector is intended to be primarily used in Scala, however customers and the community have expressed a desire to use it in Java as well. To address this need we have created an additional module which provides a Java-API for the connector. In this post, we describe how to utilize this new API to access Apache Cassandra® via Apache Spark™ from Java Applications.
Prerequisites
At the time of writing this post, 1.0.0-rc4 version of the connector was available in the central Maven repository. This version works with Cassandra 2.0 and Spark 0.9.
Note: This blog post was written targeting DSE 4.5 which included Apache Spark™ 0.9. Please refer to the DataStax documentation for your specific version of DSE if different.
The easiest way to run this application is to follow these steps:
- Download and run Cassandra server
- Create a blank Maven project
- Add the following artifacts to the dependencies section:
- Implement the application (see the tutorial below)
- Compile and run the application with parameters:
local[4] 127.0.0.1(the first argument means that the application will be run without the need to use the real Spark cluster - this is the best for learning and testing purposes; the second argument is the address of a Cassandra database node)
Tutorial
Lets create a simple application which reads sales information and computes roll-up summaries for a products hierarchy.
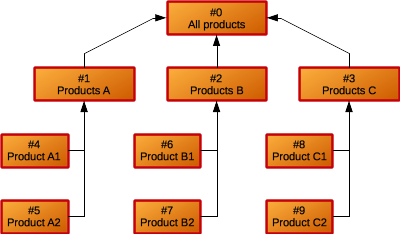
The products hierarchy may looks like the one depicted below:
We will use the following stub of the application:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
In the subsequent sections we will implement those three empty methods which generate the data, compute summaries and display the results.
Generate data
This application creates the schema and generates random data each time it is run. The data generation procedure has been broken into three simple steps, which are presented below.
Create schema
At first we connect to Cassandra using CassandraConnector, drop the keyspace if it exists and then create all the tables from scratch. Although the CassandraConnector is implemented in Scala, we can easily use it in Java with try with resources syntax:
|
1 2 3 4 5 6 7 8 9 |
|
The schema consists of three entities. We assume that the corresponding bean classes for them are already implemented (Product, Sale, Summary). While creating beans to be used with Connector, remember to add appropriate getters, setters and a no-args constructor (more info here).
Generate products hierarchy
Now, we generate the products hierarchy depicted above. Of course, we can do this by sending simple insert statements, however by doing this in a Spark way, we introduce the methods used to save RDDs to Cassandra. So, firstly we create a list of Product instances, then we convert that list to an RDD and eventually save it to Cassandra:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
javaFunctions is a static method defined in CassandraJavaUtil class. We strongly encourage users to import this class statically, to make the code more clear:
|
|
The methods defined in CassandraJavaUtil are the main entry points to the functionalities offered by Connector in Java. They are used to create special wrappers around such objects as: RDD, DStream, SparkContext, StreamingContext and their Java counterparts: JavaRDD, JavaDStream, JavaSparkContext, JavaStreamingContext.
Generate random sales
Finally, we want to generate random sales data. In this case we could use simple insert statements also, but we won't do that. Instead, we will use Spark to filter the products which are leaves in the hierarchy (a very naive approach - just check the number of parents), and then create 1000 random sales for each such product.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
In the last statement, we created a wrapper around JavaRDD. That wrapper provides a number of overloaded saveToCassandra methods. In its simplest form, it writes Java bean-like classes to Cassandra. The attributes of the bean class are mapped to the corresponding columns by their names. However, with the other versions of saveToCassandra, specific mappings are able to be defined.
Compute summaries
In this subsection we are going to compute roll-up summaries for sales of each product.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
First, productsRDD and salesRDD RDDs are created. They contain product id-product and product id-sale pairs respectively. In the next step we want to join these RDDs so converting them into pair RDDs was necessary.
|
1 |
|
At this point, joinedRDD contains tuples in which sale and the corresponding product are together. One method to compute roll-ups (not necessarily the best one) is to multiply each sale for every product in the branch it belongs. In order to do this, we will use flatMap method:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
Once we have the RDD with product id and price for each sale and each hierarchy node that sale belongs to, we can simply reduce by key so that we obtain a sum of all the sales for each hierarchy node. Then, we convert the tuples to Summary objects:
|
1 2 3 4 5 6 7 8 9 10 11 |
|
Finally, we use saveToCassandra method to save summaries to the database, as we did before:
|
1 |
|
Show the results
We want to display the results in the way that we have a product name and summary printed together. In order to do this, we need to join an RDD of summaries and an RDD of products by product keys:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Displaying the results is pretty straightforward now:
|
1 2 3 4 5 |
|
Summary
This tutorial shows the two main features of Spark Cassandra Connector - reading data from Cassandra into RDD and writing RDD to Cassandra. It is intended to be a quick and simple introduction to using Cassandra in Spark applications. More information about Java API can be found in the documentation.
The full source code of the JavaDemo class and a sample pom.xml file can be found here.






