

Vector search effectively delivers semantic similarity for retrieval augmented generation, but it does poorly with short keyword searches or out-of-domain search terms. Supplementing vector retrieval with keyword search like BM25 and combining the results with a reranker is becoming the standard way to get the best of both worlds.
Rerankers are ML models that take a set of search results and reorder them to improve relevance. They examine the query paired with each candidate result in detail, which is computationally expensive but produces more accurate results than simple retrieval methods alone.
This can be done either as a second stage on top of a single search (pull 100 results out of vector search, then ask the reranker to identify the top 10) or, more often, to combine results from different kinds of search; in this case, vector search and keyword search.
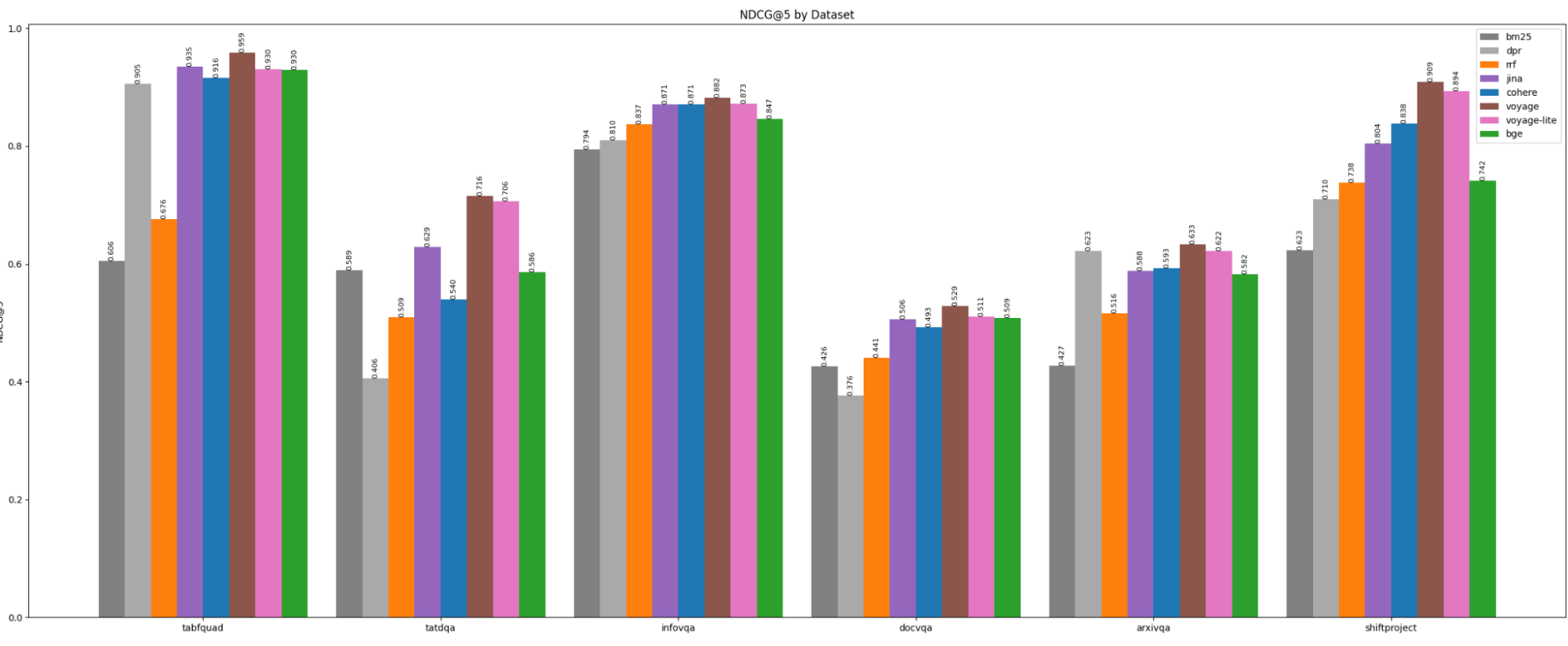
But how good are off-the-shelf rerankers? To find out, I tested six rerankers on the text from the ViDoRe benchmark, using Gemini Flash to extract text from the images. Details on the datasets can be found in section 3.1 of the ColPali paper. Notably, TabFQuAD and Shift Project sources are in French; the rest are in English.
The rerankers tested are:
- Reciprocal Rank Fusion (RRF), a formula for combining results from multiple sources without knowing anything about the queries or documents; it depends purely on relative ordering within each source. RRF is used in Elastic and LlamaIndex, among other projects.
- Cohere Rerank v3 and Jina Reranker v2, probably the most popular hosted models.
- BGE-reranker-v2-m3, the highest-scoring open source model (Apache licensed).
- Voyage rerank-2 and rerank-2-lite, freshly released (in September) by a solid company.
The rerankers were fed the top 20 results from both DPR and BM25, and the reranked NDCG@5 was evaluated.
In the results, raw vector search (with embeddings from the bge-m3 model) is labeled dpr (dense passage retrieval). BGE-m3 was chosen to compute embeddings because that’s what the ColPali authors used as a baseline.
Here’s the data on relevance (NDCG@5):
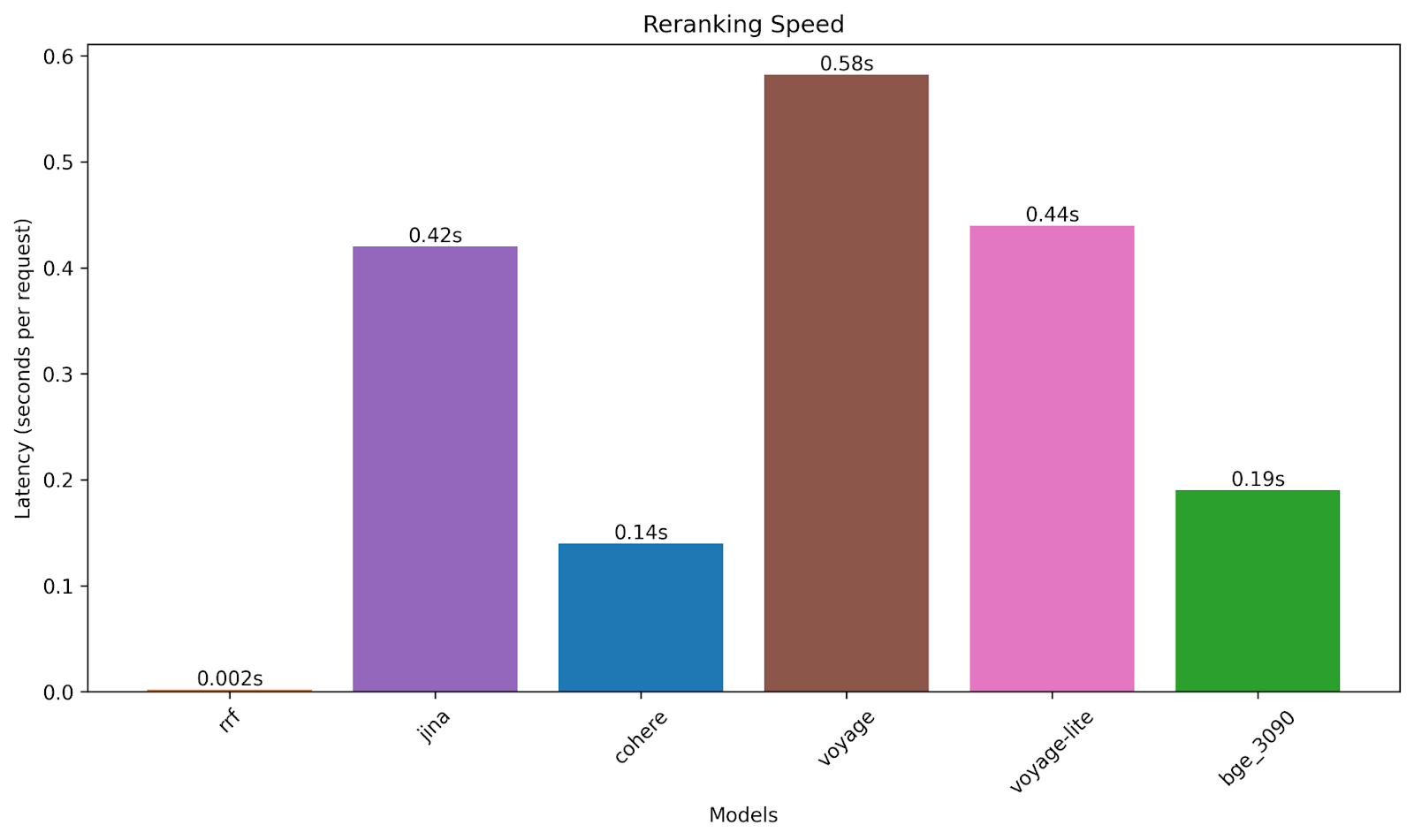
 And here’s how fast they are at reranking searches in the arxiv dataset; latency is proportional to document length. This is graphing latency, so lower is better. The self-hosted bge model was run on an NVIDIA 3090 using the simplest possible code lifted straight from the Hugging Face model card.
And here’s how fast they are at reranking searches in the arxiv dataset; latency is proportional to document length. This is graphing latency, so lower is better. The self-hosted bge model was run on an NVIDIA 3090 using the simplest possible code lifted straight from the Hugging Face model card.
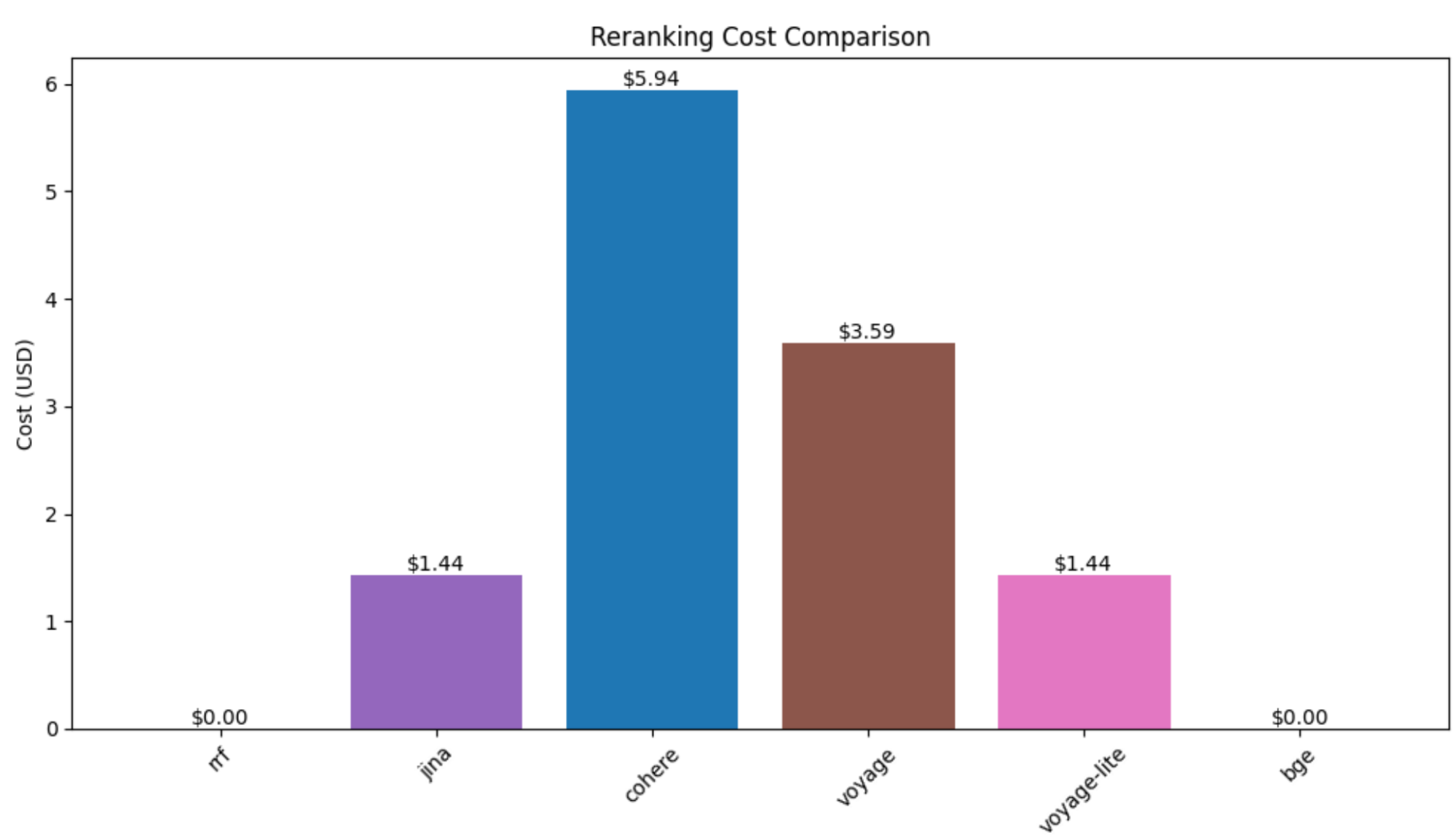
Finally, here’s how much it cost with each model to rerank the almost 3,000 searches from all six datasets. Cohere prices per search (with additional fees for long documents), while the others price per token.
Analysis
- All the models do roughly as well on the French datasets as they do on the English ones.
- Cohere is significantly more expensive and offers slightly (but consistently) worse relevance than the other ML rerankers – but it’s 3x faster than the next-fastest services. Additionally, Cohere’s standard rate limits are the most generous.
- Voyage rerank-2 is the king of reranking relevance in all datasets, for an additional hit to latency. Notably, it’s the only model that does not do worse than DPR alone in the arxiv dataset, which seems to be particularly tricky.
- Voyage rerank-2-lite and jina reranker v2 are very, very similar: they’re the same speed, hosted at the same price, and close to the same relevance (with a slight edge to Voyage). But Voyage’s standard rate limit is double jina’s, and with Voyage you get a “real” Python client instead of having to make raw http requests.
- BGE-reranker-v2-m3 is such a lightweight model (under 600M parameters) that even on an older consumer GPU it's usably fast.
Conclusion
RRF adds little to no value to hybrid search scenarios; on half of the datasets it performed worse than either BM25 or DPR alone. In contrast, all ML-based rerankers tested delivered meaningful improvements over pure vector or keyword search, with Voyage rerank-2 setting the bar for relevance.
Tradeoffs are still present: you get superior accuracy from Voyage rerank-2, faster processing from Cohere, or solid middle-ground performance from Jina or Voyage's lite model. Even the open-source BGE reranker, while trailing commercial options, adds significant value for teams choosing to self-host.







