

This blog is reposted with permission from Jeff Carpenter's blog here.
Porting a Java microservice to use an Apache Cassandra DB as a Service
In case you haven’t heard, DataStax has announced a free Beta for our Apache Cassandra as a Service offering, known as Apollo. Apollo is the first service to be released on our cloud platform known as Constellation.
I wanted to share a few of my first impressions and tips on using Apollo. I’ll provide a quick disclaimer up front that since this is a Beta, some of the details and links I share will be subject to change.
As part of the Beta you can create clusters in both Constellation (deployed on Amazon Web Services) and Google Cloud Platform. To expand on that last sentence — the AWS offering is part of our Constellation cloud platform, which will eventually expand to other public clouds. In this environment, the billing for production databases (when you create non-development clusters after the Beta period) will be through DataStax. On the Google side, you can provision clusters through the Google Cloud Marketplace which gives you the advantage of billing through your GCP account.
During the Beta period, documentation for running clusters is found on a temporary docs site: AWS docs / GCP docs.
Creating a Database on Apollo
It’s really straightforward to create an account and then start databases. My colleague Adron Hall has a great post on getting started with Apollo, so I won’t repeat the details here. The best thing about the experience was how, well, boring it was. I specified a database name, keyspace name, username and password and started a database. A few minutes later I got an email saying it was up — no big deal
Each cluster includes access via DataStax Studio, which you can quickly use to configure schema, load sample data, and so on.
One quick thing to note is that databases are terminated automatically 72 hours after start during the Beta period, so don’t get too attached, these are just for testing purposes at this point.
Porting the Reservation Service
Once I had a database set up and poked around a bit, I got down to business with development. I decided to port my Reservation Service, a sample microservice I created in conjunction with Cassandra: The Definitive Guide.
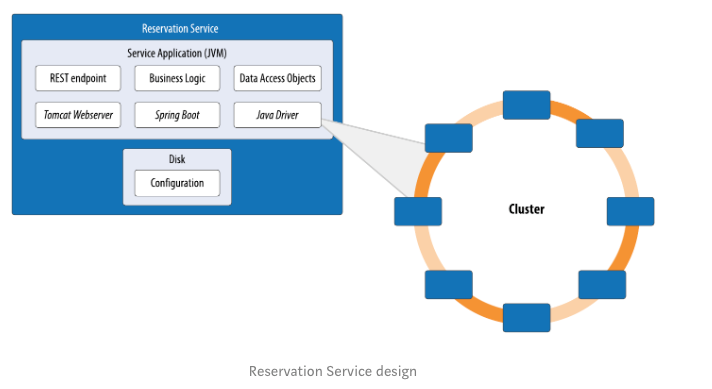
You can see the design of the service in the figure below. It’s a basic Spring Boot service that provides a RESTful API and persists data to Cassandra using the DataStax Java Driver.
My colleague Cedrick Lunven (Twitter, GitHub) and I recently collaborated on some updates to the service including upgrading to the 4.2 version of the Java Driver and adding some automated tests. As part of that work, Cedrick added code to create the reservation schema programmatically.
Here’s how it works:
- The Reservation Service automatically creates the schema each time it starts up.
- The code uses the CQLIF NOT EXISTS semantics so that the statements don’t error if the keyspace and tables already exist.
We also changed the driver initialization logic to take advantage of the file-based configuration feature introduced in the 4.0 release.
Flexible Session Creation
In order to update the Reservation Service to work with Apollo, I followed the instructions on the DataStax Docs site. There’s a very helpful page devoted to exactly the topic I needed — migrating Java applications to work with Apollo.
One of my goals for this update was to see how much of the logic of connecting to a Cassandra cluster I could externalize from the Reservation Service code, so that, if possible, I could point the Reservation Service at any Cassandra cluster just by changing the configuration file with no changes.
The good news is that I was able to achieve exactly this goal! Here is the application.conf configuration file that I use connect to my Apollo cluster:
datastax-java-driver {
basic {
cloud.secure-connect-bundle = <INSERT PATH TO BUNDLE>
request.consistency = LOCAL_QUORUM
}
advanced.auth-provider {
class = PlainTextAuthProvider
username = <INSERT USERNAME>
password = <INSERT PASSWORD>
}
}
To run the Reservation Service yourself, you’ll need to create an Apollo database and replace the <INSERT ...> elements based on your configuration. The key elements here are:
- The path to the secure connect bundle — the bundle is a zip file containing connection points and encryption keys the application needs to connect to the cluster securely. It also includes the keyspace, which is important for reasons you’ll see below
- The default consistency level — for Apollo, you’ll want to default to run all queries at the
LOCAL_QUORUMconsistency level (it’s required for writes) - The username and password for the database user.
For contrast, file-based configuration for a self-managed cluster typically looks something like this (excerpt from the Java Driver documentation page):
datastax-java-driver {
basic {
contact-points = [ "1.2.3.4:9042", "5.6.7.8:9042" ]
load-balancing-policy.local-datacenter = datacenter1
}
}
This highlights two primary differences of this self-managed configuration vs. the Apollo configuration:
- In the Apollo configuration, the secure connect bundle abstracts the contact points
- Apollo itself determines the load balancing policy, so you don’t need to specify one
The tricky part — programmatic schema management
While the configuration updates were simple, the harder part was updating the code that performed schema management.
At least for the present time, Apollo limits databases to a single keyspace which is defined when the cluster is created. The name of the keyspace is also defined as part of the secure connect bundle so that you don’t have to specify it as a separate configuration parameter.
This led to a situation that I needed to work around in order to update the schema management code. The Reservation Service previously provided schema management via an operation on the ReservationRepository class which was invoked as part of the constructor using a dropSchema boolean argument. If the argument was set, as it was in test configurations, requesting a repository object would result in the reservation keyspace being dropped and rebuilt.
However, given the single keyspace per database restriction in Apollo, dropping and adding keyspaces are disallowed operations. This is implemented via Cassandra’s access control mechanisms — the database user you specify at database creation time is not given permissions to add or drop keyspaces.

My first attempt was to modify the dropSchema logic to drop tables instead of the entire keyspace. However after thinking about things more the solution I decided to implement was to leverage the CQL TRUNCATE operation instead of dropping and rebuilding schema.
My solution included the following:
- Refactoring schema management operations out or the
ReservationRepositoryinto a newReservationSchemaManagerclass - Separating keyspace creation and table creation into separate operations on
ReservationSchemaManagerfor flexibility, and ensuring these operations useIF NOT EXISTsemantics so that no errors are generated if tables already exist - Invoking the schema creation operations in the ReservationRepository constructor to ensure that schema exists. When run against a new Apollo, the keyspace will already exist, but the tables might not.
- Adding an operation to
ReservationSchemaManagerto truncate the tables in thereservationkeyspace. - Updating the test code to truncate tables between each test case instead of dropping and rebuilding the keyspace.
An example you can reference
- You can see the results of my refactoring on the
apollobranch of the Reservation Service here
To summarize, here are my top 3 recommendations for porting an application to run on Apollo:
- Upgrade to the latest DataStax Java driver and maximize your usage of file-based configuration
- Check your application and data model against the guardrails including default consistency level
- Update your schema creation approach, making sure any programmatic schema creation is flexible enough to work around Apollo’s restrictions on manipulating keyspaces.
What’s next?
There’s still more of Apollo to explore. I’m looking forward to trying out the GCP version, as well as accessing Apollo clusters via the new standalone cqlsh download.
During this free Beta period we’d love to get feedback from as many people as possible. You can go to https://apollo.datastax.com to get started.
Please drop me a note to let me know you’ve joined the trial. I’d love to hear what you think!









