

Web3 is in a tricky spot today, and not just because of high-profile bad actors casting an overlong shadow on the blockchain ecosystem. There are three significant issues that are hard to overcome without abandoning the very principles that make blockchain appealing in the first place:
- On-chain storage and write operations are prohibitively expensive versus their Web 2.0 counterparts.
- On-chain storage and write operations are incredibly slow (arguably by design), in order to ensure the security that blockchain-based systems promise. With more than 51% of nodes required to agree on the validity of new data written, performance further degrades as nodes are added to the network, and also as write request traffic increases.
- The length (size) of any given blockchain ledger grows significantly with use, breaking the vast majority of database infrastructure available on the market today.
Operational databases, analytic databases and distributed ledgers are all valid and different types of database management systems. What can be confusing about the different peer-to-peer blockchain networks springing into existence is that they aren’t just “databases,” many are also “servers” that are available to host (serve) internet applications (or “dApps”— decentralized apps) written by any capable developer.
Most new technologies go through a phase where their usage is overgeneralized until they find a product or market fit. At the root of these three challenges is that very same “right tool for the wrong job” dynamic. For example, most IT professionals won’t use an operational database as an analytic database or vice versa. Using a distributed ledger as an operational or analytic database, for example, underneath a dApp deployed to a blockchain network, is a particularly bad pairing for reasons explained further below.
Of course, the blockchain community is working on innovative ways to resolve performance issues without compromising security, but it will take time. Ethereum has adopted some recent changes in this regard. Arguably, trust must be placed somewhere. Blockchain shifts that trust away from traditional Web 2.0 models, but does not fundamentally eliminate that requirement — at least not today.
Off-chain, real-time data offers an immediate path forward for Web3’s search for product/market fit. However, this approach locates trust, in the form of operational/analytic data for dApps, in Web 2.0 systems. However, most successful dApps and blockchain-based services on the market have already made this trade-off, using a right-tool-right-job approach that employs each technology for what it’s best at.
Before delving more deeply into how and why Web3 progress can be made today with real-time data, let’s consider Web3’s future prospects for a moment, irrespective of this triad of challenges we’ve just identified.
What Will Continue to Drive Web3 Forward?
At a time like this, it’s important to remember that blockchain ≠ crypto. Crypto is an application of the blockchain concept and base technology building block. The same is true of NFTs and the wider Web3 concept. The core blockchain concept — an untamperable public record of transactions, positions and who-owns-what — is persistently and intriguingly different from the current financial system, where such ledgers reside in private databases, only accessible by the rules of the governing institution and regulating bodies and laws. There are indeed real-world dollars and sense for specific use cases. What are they?
According to McKinsey, $200 billion in loans were disbursed from the largest Web3 lending platforms in 2021. Loans, deposits, remittances, asset swaps, trade finance and insurance have established themselves as valid use cases. Other peer-to-peer, gaming, social and online media are early but show significant activity.
Digital identity services remain a distinct possibility, along with supply chain and logistics management. Speculative use cases inside a hypothetical metaverse are driving real investment dollars, with companies like Facebook pivoting, rebranding to Meta, and going all in.
Private blockchain systems on closed and protected networks (such as Hyperledger Fabric) perhaps aren’t what the creators envisioned, but can serve more generalized use cases for specific industries and institutions now, (at the expense of being a Web3 system that’s open to the public). NFTs (non-fungible tokens) , or, the idea of a unique, indivisible and untamperable token has real potential business value in representing real-world and online-only ephemeral assets digitally.
These are both things a safe public leger makes possible, but doesn’t yet solve. Making the real-world-to-digital-NFT connection legally, and in some cases, physically, is still very much being explored. This quarter’s report from Web3 provider Alchemy cites smart contract deployment is up 143% from the same quarter in 2021.
While there are significant issues to overcome, as any new idea has, there is real gravity in investment dollars, developers and institutional interest attracting energy for moving blockchain forward. As the core technology improves, more Web3 value will be created. As more value is built, new opportunities will arise, which drive interest in resolving regulation, legal, data privacy, and better developer and end-user experiences.
On-Chain Data Considerations for Web3 Developers
Challenges with proof-of-work-based blockchain offerings extend into their very underlying architecture. Operational databases are great for fast, efficient data storage and retrieval. Analytic databases are great for fast, open-ended querying and exploration. Non-relational databases offer varying levels of operational or analytic features at scale, without sacrificing performance and availability.
Blockchain-based systems offer a secure, immutable ledger at the expense of performance. Attempting to use a secure, append-only immutable ledger as an operational, analytic or non-relational database will result in the following issues:
Unacceptable Performance
Web 2.0 tech stacks have set most of the world’s expectations on digital experiences that respond quickly and don’t take two minutes to six hours, whether you are on a tablet, phone or desktop/laptop. Most popular blockchain implementations are based on slow proof-of-work algorithms to safeguard writes to a blockchain data store and slow peer-to-peer consensus to ensure consistent data across the node network for reads.
Production Outages Due to Data Volume
Blockchain isn’t just a “big data” concern; it’s gigantic, mind-boggling data that only gets bigger with usage. Few operational or analytic databases are capable at this level and even fewer are truly linearly scalable at that level, significantly narrowing the field of choices.
Conflicting and Inaccurate Data
The wide peer-to-peer, eventually consistent design and proof-of-work nature of blockchain makes it secure, but gives rise to inconsistent data which renders it useless as an operational or analytic database for Web3 apps. Users end up seeing behavior like this in resulting dApps.
Because there are no error messages or failure codes for these issues, it is time-consuming or impossible to write error-handling code to test, account for, or address these errors by writing code in an attempt to compensate. Debugging in production or otherwise at the point of a sword is, of course, a nightmare for everyone involved. Downstream tech support will have no answers for angry users, nor the developers for the tech support staff. Cue the negative app store reviews.
Unacceptable Storage/Usage Costs
On-chain operations are expensive: 1GB of data on the Ethereum blockchain costs thousands of dollars.
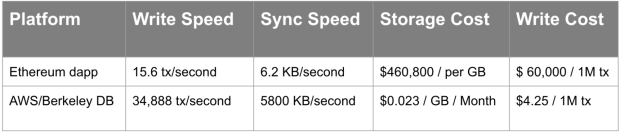
Source: Noah Ruderman on Medium
Other Considerations
Indexing or synchronizing blockchain data off-chain isn’t straightforward as the data is not human-readable. Blockchain data requires decoding, enrichment from third-party data services, reorganization and data modeling before being easily consumable by developers.
Solution: Sync Data Off-Chain in Real Time
The popular blockchain network implementations will take time to address performance from within their designs. Off-chain processing is the main technique that successful IT professionals are using to leverage the strengths of existing database technologies and blockchain together, using each for what it was best designed for. To oversimplify for a moment, dApps should read data from off-chain databases, and write data back to the chain (but only the minimally required details necessary to record the transaction end results).
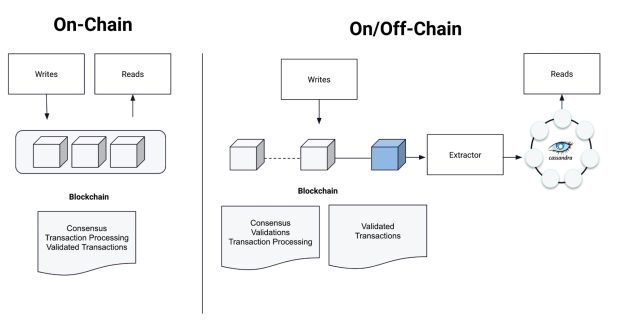
By syncing the state of the blockchain to an operational or analytic database in real-time, you ensure data accuracy/currency for your dApps to operate on quickly. Then, when your dApp and off-chain database have done as much pre-processing as possible, commit the end result back to the chain.
Static and binary assets can use systems like IPFS, but would be wise to consider off-chain object storage (S3, for example) whenever possible for the same reasons. So in practice, off-chain databases with always-in-sync clones of the chain state should be the read/write target for as much of the operational or analytic workload as possible.
But as discussed previously, the sheer volume of data, especially over time, breaks most data infrastructure. Apache Cassandra is one of the most capable systems as an operational database at this level of volume, scale and performance.
With the right data model, applications can experience sub-second speeds you’d expect from an in-memory cache like Redis, yet from a persistent database management system (DBMS). What if a non-relational data service was available to provide both historical and always-up-to-date (real-time) data off-chain?
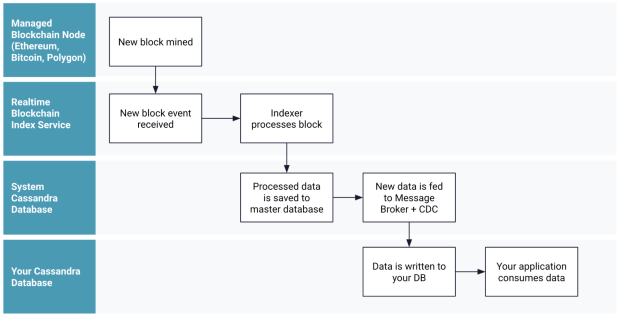
During the indexing process, raw data is decoded automatically. For developers, this transforms the experience of working with blockchain data from raw hexadecimal data that looks like this:

To human-readable data that looks like this:
Then, Web3 developers typically need to re-organize and enrich chain data from third-party data services like Etherscan, whatsabi, NFT metadata and others in order to be useful for even the simplest of queries. If that enriched data is then modeled into queryable database tables, developers would have the full power of a standard DBMS query language to work with (versus having to learn a blockchain analytic API).
Let’s see an example:
Developer Intent: Search five entries from Block Group 134
Actual query code:
SELECT * FROM eth_blocks WHERE blocks_group=134 LIMIT 5;
System Response:
blocks_group | 134
number | 13399901
hash | 0x88370229a285398b48e58fea8947d6ef101f7b4d177b5c224b8fd22b9247ebde
base_fee_per_gas | 0.000000111470210631
blocks_difficulty | 0
blocks_total_difficulty | 0
burnt_fees | null
difficulty | 0
extra_data | 0x65746865726d696e652d6575726f70652d7765737433
gas_limit | 30000000
gas_target_percentage | null
...click for more
So, what does this look like in practice? To bring it to life, have a look at these two (live) sample applications that use exactly such an off-chain, real-time data service. The application source code should be familiar to Web3 developers; it’s written using the popular Web3.js library.
Built using React and Next JS, the NFT Explorer gives the user a complete view of NFTs supported on the Ethereum Blockchain that have been minted or transferred in real-time. |
Like the NFT Explorer, this Blockchain Data Explorer pulls all of the blockchain data from off-chain data and gives the user a real-time view of the latest blocks that have been mined, along with the latest Ethereum transactions. |
Delivering all this atop a managed cloud service would help conquer the traditional reflex to reach for the relational DBMS-style ease of use and time to market. Building such a service atop Cassandra would also uniquely offer the ability to co-locate this data with your Web3 app in any region, or multiregion, without sharding. Cassandra’s built-in replication has been battle tested at the most extreme levels of internet scale in production for over a decade.
Benefits for Web3 Apps and Developers
By minimizing dApp size, on-chain data storage and blockchain writes with off-chain processing, operational costs will realign to Web 2.0 levels for most use cases. dApp performance for users on their device of choice returns to acceptable/expected levels. dApp developers can then design the appropriate “wait time” dialogs, screens and warnings to set user expectations upon needing to commit a write operation to a blockchain-based system.
The biggest, nastiest issue of data consistency is resolved, as the majority of the dApp’s operational data is being stored in a fast, reliable off-chain database. This will save not only hours of highly frustrating (and possibly fruitless) debugging, but avoiding production errors that are potentially impossible to resolve.
Because off-chain systems like non-relational databases can handle big data volumes, your dApps will meet expectations of uptime and response time as the blockchain grows, with no expensive system redesign or ground-up rewrite months after going into production. Working with Cassandra — arguably the most reliable, scalable and fast non-relational database out there — is also one of the most well-paid jobs out there, according to the latest Stack Overflow dev survey.
Benefits for the Business
Broken, slow or inaccurate applications result in unrecoverable losses in users, revenue and investor confidence. But let’s engage in the dialog we all want to be having — what exciting things might be synchronizing blockchain state in real-time to off-chain, non-relational infrastructure enable?
- Analytic dApps: Integrating dApps with off-chain analytic databases open up the entire “Web 2.0” landscape of options and use cases.
- Fraud detection/prevention features: Build dApps that can eject bad actors or flag/block misuse, protecting your user community and your business.
- Authority for digital asset exchange: NFTs exchange requires accurate/up-to-date market data to facilitate the best trade/sale/exchange. Prevent buyer’s remorse when users see what they just bought for a lower price a few minutes later, the resource-intensive refund process and negative user reviews.
- Location-based features: Knowing where something is right now is the basis of a lot of today’s mobile applications. Bring this to your dApps!
- IoT applications: Machine-generated data, from either software or hardware, comes at write speeds and volumes that only non-relational databases can handle without compromise.
- Data sovereignty: Locate the synchronized copy of the blockchain state with a dApp — no matter where in the world it’s deployed — for compliance, regulatory or legal reasons.
Blockchain transaction resolution time is dictated by the protocol and can’t be sped up without gas/transaction fees or using accelerator services. By deflecting as much pre-processing as possible off-chain, you’ll minimize the transaction end result in both size and frequency. This will lower chain write costs and improve dApp speed for any use case.
Try It Yourself as a Service
This focus on real-time data is something that goes beyond blockchain. It’s an area where the industry has been innovating for more than a decade. But technologies like blockchain help to show just how important it is for real-time data to become a part of your data architecture and your business model.
While we wait for quantum cryptography as a service, atomic clock ubiquity and fresh innovation in distributed consensus algorithms, real-time data is available today at Web 2.0 cost structures. And real-time data will remain a core, essential element of any blockchain implementation in the future.
Curious about how you can start, now? Get in touch with us at blockchain@datastax.com to learn how the combination of blockchain and real-time data can come together for your project.










