

So you want to experiment with Apache Cassandra and Apache Spark to do some Machine Learning, awesome! But there is one downside, you need to create a cluster or ask to borrow someone else's to be able to do your experimentation… but what if I told you there is a way to install everything you need on one node, even on your laptop (if you are using Linux of Mac!). The steps outlined below will install:
- Apache Cassandra
- Apache Spark
- Apache Cassandra - Apache Spark Connector
- PySpark
- Jupyter Notebooks
- Cassandra Python Driver
Note: With any set of install instructions it will not work in all cases. Each environment is different. Hopefully, this works for you (as it did for me!), but if not use this as a guide. Also, feel free to reach out and add comments on what worked for you!

Installing Apache Cassandra

Download bits
http://cassandra.apache.org/download/
Untar and Start
http://cassandra.apache.org/doc/latest/getting_started/installing.html
tar -xzvf apache-cassandra-x.x.x.tar
.//apache-cassandra-x.x.x/bin/cassandra //This will start Cassandra
You might want to add .//apache-cassandra-x.x.x/bin to your PATH but this is not required.
Using all defaults in this case. For more information about non default configurations review the the Apache Cassandra documentation.
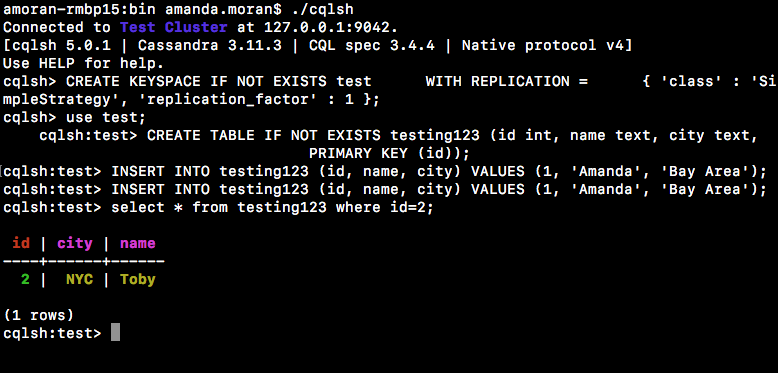
Create a Keyspace and Table with CQLSH
We will use this keyspace and table later to validate the connection between Apache Cassandra and Apache Spark.
.//apache-cassandra-x.x.x/bin/cqlsh
CREATE KEYSPACE IF NOT EXISTS test WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };CREATE TABLE IF NOT EXISTS testing123 (id int, name text, city text, PRIMARY KEY (id));INSERT INTO testing123 (id, name, city) VALUES (1, 'Amanda', 'Bay Area');INSERT INTO testing123 (id, name, city) VALUES (2, 'Toby', 'NYC');
Install Apache Spark in Standalone Mode

Download bits:
https://spark.apache.org/downloads.html
Install:
https://spark.apache.org/docs/latest/spark-standalone.html#installing-spark-standalone-to-a-cluster
tar spark-x.x.x-bin-hadoopx.x.tar
Before starting Spark do the following:
export SPARK_HOME=”//spark-x.x.x-bin-hadoopx.x
cd $SPARK_HOME/confvim spark-defaults.conf//Add line spark.jars.packagesSpark.jars.packages com.datastax.spark:spark-cassandra-connector_2.11:2.3.2
![]()
Start Spark In Standalone Mode
cd spark-x.x.x-bin-haoopx.x/./sbin/start-master.sh
Information about the Apache Spark Connector
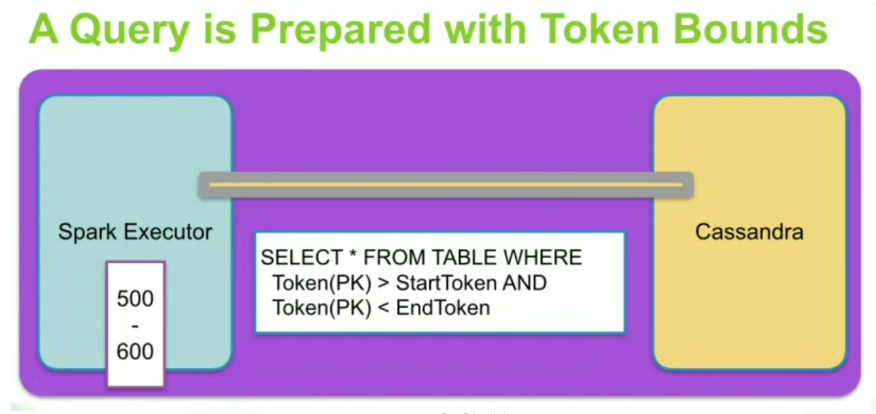
The Apache Cassandra and Apache Spark Connector works to move data back and forth from Apache Cassandra to Apache Spark to utilize the power for Apache Spark on the data. This should be co-located with Apache Cassandra and Apache Spark on both on the same node.The connector will gather data from Apache Cassandra and its known token range and page that into the Spark Executor. The connector utilized the DataStax Java driver under the hood to move data between Apache Cassandra and Apache Spark. More information can be found here: https://databricks.com/session/spark-and-cassandra-2-fast-2-furious
Note: Just working with PySpark in this case, and only DataFrames are available.
https://github.com/datastax/spark-cassandra-connector/blob/master/doc/15...
https://spark-packages.org/package/datastax/spark-cassandra-connector
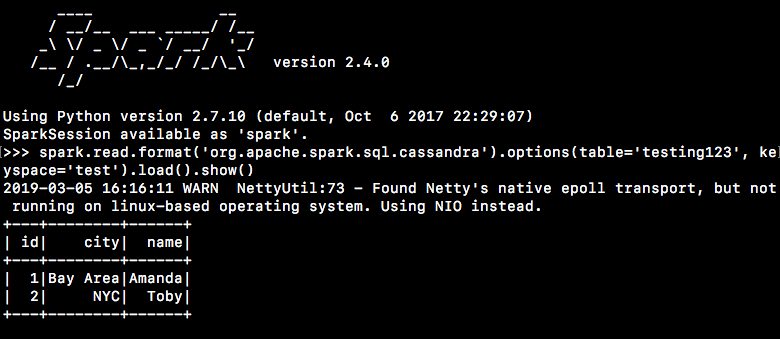
Test the connection out first -- Using that keyspace and table we created above
.$SPARK_HOME/bin/pyspark
#Create a dataframe from a table that we created abovespark.read.format('org.apache.spark.sql.cassandra').options(table='testing123', keyspace='test').load().show()
Install Jupyter Notebooks with pip
Reference: https://jupyter.org/install
python -m pip install --upgrade pip
python -m pip install jupyter
Start Jupyter with PySpark
cd spark-2.3.0-bin-hadoop2.7
export PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS='notebook'SPARK_LOCAL_IP=127.0.0.1 ./bin/pyspark
These commands will launch Jupyter Notebooks on localhost:8888, the downside is if you have existing notebooks you won't be able to navigate to them... but just copy them here ... Not the best solution but it will do to be able to use all these pieces together!
Install Apache Cassandra Python Driver
pip install cassandra-driver
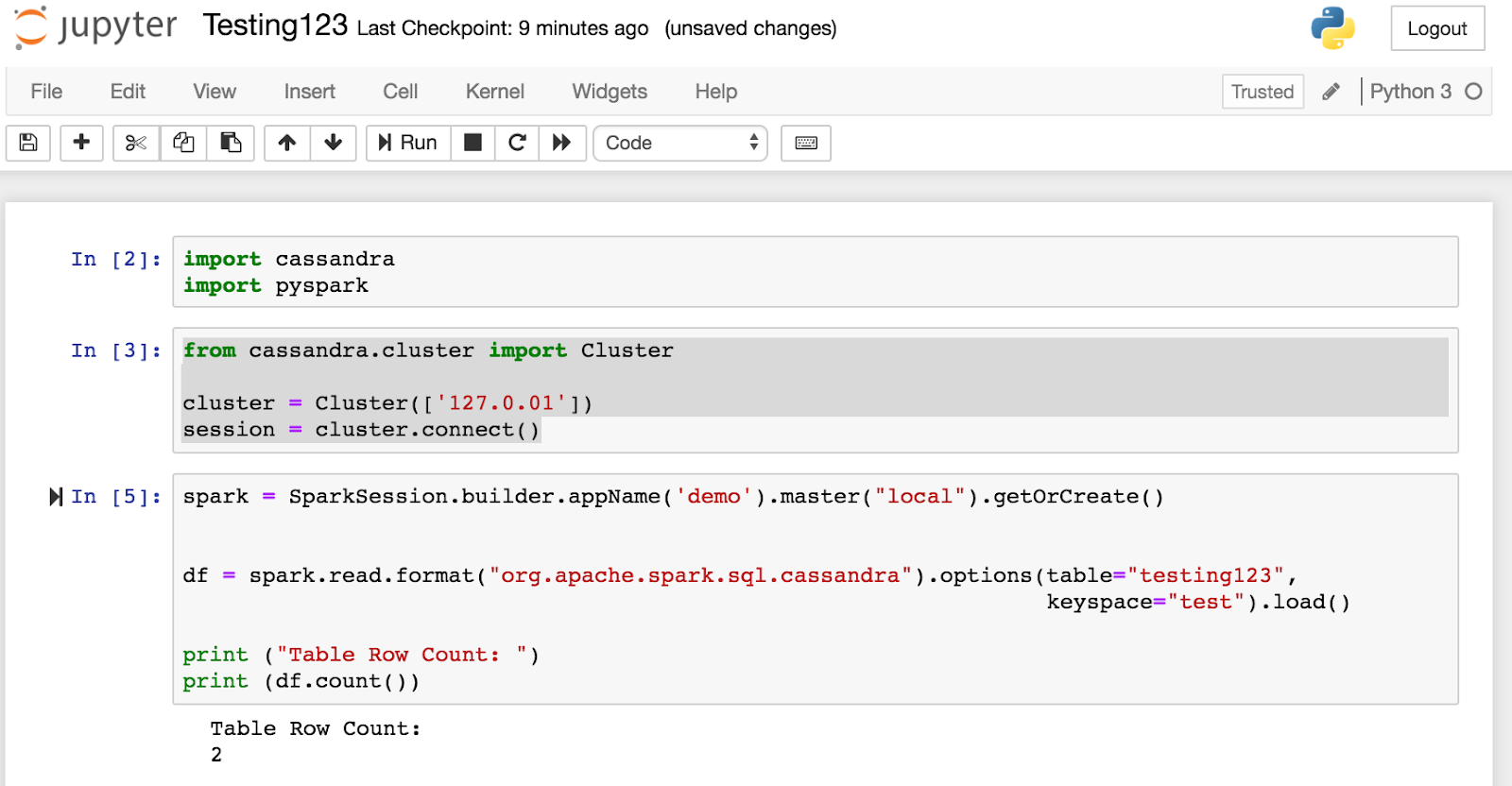
Create a New Notebook
Import Packages
Import cassandra
Import pyspark
Connect to Cluster
from cassandra.cluster import Cluster
cluster = Cluster(['127.0.01'])session = cluster.connect()
Create SparkSession and load the dataframe from the Apache Cassandra table. Verify transfer has occurred by printing the number of rows in the dataframe. We should see “2”
spark = SparkSession.builder.appName('demo').master("local").getOrCreate()df = spark.read.format("org.apache.spark.sql.cassandra").options(table="testing123", keyspace="test").load()print ("Table Row Count: ")print (df.count())
Conclusion
TADA!
There you have it! You now have Apache Cassandra, Apache Spark, Apache Cassandra-Apache Spark connector, Pyspark, Cassandra Python driver and Jupyter all installed on one node (or local instance!) Congratulations! Enjoy exploring your data!
A few notebooks you might enjoy!
https://github.com/amandamoran/wineAndChocolate
https://github.com/amandamoran/pydata
Reference: https://medium.com/explore-artificial-intelligence/downloading-spark-and...






