

This is the first part of a two part series on the new stress tool.
Background
The choices you make when data modeling your application can make a big difference in how it performs. How many times have you seen database benchmarks that look impressive in an article but when you try them with your data/schema you are left disappointed and confused? To get a proper understanding how a database scales and to capacity plan your application, requires significant effort in load testing. Most importantly, to understand the tradeoffs you are making in your data model and settings requires multiple iterations before you get it right.
To make testing data models simpler, we have extended the cassandra-stress tool in Cassandra 2.1 to support stress testing arbitrary CQL tables and arbitrary queries on that table. We think it will be a very useful tool for users who want to quickly see how a schema will perform. And it will help us on the Cassandra team diagnose and fix performance problems and other issues from a single tool. Although this tool comes in the Cassandra 2.1 release it also works on Cassandra 2.0 clusters.
In this post I'll explain how to create a CQL based stress profile and how to execute it. Finally I'll cover some of the current limitations.
The new stress YAML profile
The new cassandra-stress now supports a YAML based profile that is used to define your specific schema with any potential compaction strategy, cache settings and types you wish, without having to write a custom tool.
The YAML file is split into a few sections:
- DDL - for defining your schema
- Column Distributions - for defining the shape and size of each column globally and within each partition
- Insert Distributions - for defining how the data is written during the stress test
- DML - for defining how the data is queried during the stress test
To help explain the file let's define one to model a simple app to hold blog posts for multiple websites, the posts are ordered in reverse chronological order.
DDL
The DDL section is straight forward. Just define the keyspace and table information. If the schema is not yet defined the stress tool will create it the first time you run stress on this profile. If you have already created the schema separately then you only need to define the keyspace and table names.

Column Distributions
Next, the 'columnspec' section describes the different distributions to use for each column. These distributions model the size of the data in the column, the number of unique values, and the clustering of them within a given partition. These distributions are used to auto generate data that "looks" like what you would see in reality. The actual data is garbage but it's reproducible and procedural to generate.
The possible distributions are:
- EXP(min..max)
- An exponential distribution over the range [min..max]
- EXTREME(min..max,shape)
- An extreme value (Weibull) distribution over the range [min..max]
- GAUSSIAN(min..max,stdvrng)
- A gaussian/normal distribution, where mean=(min+max)/2, and stdev is (mean-min)/stdvrng
- GAUSSIAN(min..max,mean,stdev)
- A gaussian/normal distribution, with explicitly defined mean and stdev
- UNIFORM(min..max)
- A uniform distribution over the range [min, max]
- FIXED(val)
- A fixed distribution, always returning the same value
NOTE: If you use a ~ prefix, the distribution will be inverted.
For each column you can specify (note the defaults):
- Size distribution - Defines the distribution of sizes for text, blob, set and list types (default of UNIFORM(4..8))
- Population distribution - Defines the distribution of unique values for the column values (default of UNIFORM(1..100B))
- Cluster distribution - Defines the distribution for the number of clustering prefixes within a given partition (default of FIXED(1))
In our example it makes sense to size the fields appropriately to their limits in reality. Most blogs have large bodies and at most a thousand posts per blog.

Insert Distributions
The insert section lets you specify how data is inserted during stress. This get's a little tricky to think about but it's pretty straight forward once you grasp it.
For each insert operation you can specify the following distributions/ratios:
- Partition distribution
- The number of partitions to update per batch (default FIXED(1))
- select distribution ratio
- The ratio of rows each partition should insert as a proportion of the total possible rows for the partition (as defined by the clustering distribution columns). default FIXED(1)/1
- Batch type
- The type of CQL batch to use. Either LOGGED/UNLOGGED (default LOGGED)
In our example it makes sense to only insert a single blog post at once to a single domain.

DML
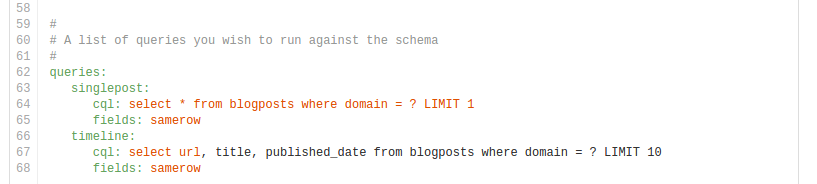
You can specify any CQL query on the table by naming them under the 'queries' section.
The 'fields' field specifies if the bind variables should be picked from the same row or across all rows in the partition
In our example case we may want to see how fetching the most recent post for a domain as well as the previous 10 post meta-information to show in a timeline view.
Putting it all together
So now that we have our profile we can run it with the following commands. The complete YAML and results is located here.
Inserts:
./bin/cassandra-stress user profile=./blogpost.yaml ops\(insert=1\)
Without any other options stress will run our inserts starting with 4 threads and increasing them till it reaches a limit. All inserts are done with the native transport and prepared statements. The full list of cassandra-stress features is listed under the help command.
On my laptop this was ~8,500 inserts/s with 401 threads. This is significantly slower then the default stress, but we don't expect it to be as fast since this is > 1Kb per insert.
Queries:
./bin/cassandra-stress user profile=blogpost.yaml ops\(singlepost=1\)
Reading a single post yields ~7000 queries/sec
./bin/cassandra-stress user profile=./blogpost.yaml ops\(timeline=1\)
Reading a timline yields ~7000 queries/sec, but ~25000 CQL rows/sec since this is multiple rows per domain
Mixed:
./bin/cassandra-stress user profile=./blogpost.yaml ops\(singlepost=2,timeline=1,insert=1\)
We can also run many types of queries and inserts at once. This syntax sends three queries for every one insert.
Other YAML examples
Cassandra 2.1 comes with three sample yaml files in the tools directory with more advanced examples
https://github.com/apache/cassandra/tree/cassandra-2.1/tools
Limitations/improvements
The new stress covers a lot of use cases but there are some things it can't do. We do plan to address these in future releases:
- Doesn't support map types or user defined types
- Indexes must be manually added to your tables
Some of the features we wish to add are:
- Random sentence, instead of random string, generation to more accurately test the effect of compression.
- More control over read and write patterns, like only query the most recent partitions added.
To be continued...
This post covered some of the basic of the new stress tool, in the next post we will cover a more advanced example.






