

Welcome to Part 2 of our Apache Cassandra® series. In part 1 you read about the features of the powerful database Cassandra trusted by thousands of global enterprises. In this post, we’ll show you how to build advanced data models on Cassandra so you can use them in successful applications.
Cassandra is a distributed NoSQL database well known for its big data scale and disaster tolerance capabilities. It offers great features like elastic linear scalability, a high level of performance, and the ability to handle millions of queries while keeping petabytes of data. This is why the vast majority of Fortune 100 companies use it.
But remember: this powerful capacity is a shared responsibility between developers and Cassandra. It’s not enough to just launch a cluster. It’s crucial to develop a proper data model to take advantage of all Cassandra has to offer. Otherwise, these powerful features will fall short.
In this post, we go beyond queries, partitions and tables to design an efficient data model for highly-loaded applications. We’ll discuss the following:
- How Cassandra organizes data
- Data modeling methodologies
- Three data modeling use-cases for IoT, investment portfolio, and order management
- Work through hands-on scenarios to represent the data models on Cassandra
How Cassandra organizes data
In order to deliver successful and efficient applications, you need to know how Cassandra organizes data. This is essential to building a correct data model. The main components of Cassandra’s data structure include:
- Keyspace: A container of tables, similar to a PostgreSQL schema
- Table: A set of columns, primary key, and rows storing data in partitions
- Partition: A group of rows together with the same partition token (a base unit of access in Cassandra)
- Row: A single, structured data item in a table
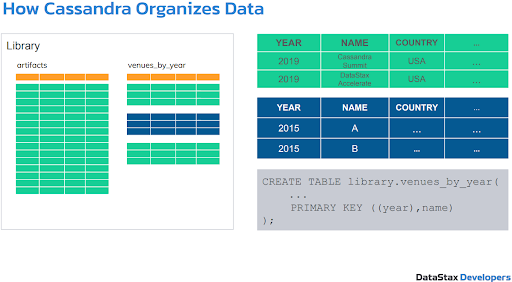
Figure 1. Cassandra stores data in tables.
Let’s look at each of the components in more detail.
Keyspace in Cassandra
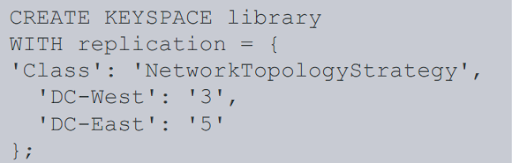
Figure 2. A keyspace.
A keyspace is a data container on Cassandra. It holds tables, materialized views, user-defined types, functions and aggregates. A Cassandra cluster typically has one keyspace per application.
A keyspace determines how data replicates on multiple nodes. The total number of replicas across the cluster is known as the replication factor.
In Figure 2, 3 and 5 are the replication factors for DC-West and DC-East respectively. Data replication is an innate feature of Cassandra to ensure reliability and fault tolerance.
When creating or modifying a keyspace, you need to specify a replication strategy that determines the nodes where replicas are placed. There are two kinds:
- Simple strategy: This strategy should never be used in production. It is useful for a single data center and one rack for development and testing environments only. If you intend to have more than one data center, use the next strategy
- Network topology strategy: This strategy is good for production or staging environments. It’s network topology aware, so it understands your servers, server racks, and data centers. This strategy is preferred for most deployments because it’s much easier to expand to multiple data centers when needed
Tables in Cassandra
Once you’ve created a keyspace, you can create a table. Every keyspace has multiple tables to store data. Each table consists of rows and columns.

Figure 3. A table in Cassandra.
To create a table, you must define a primary key. A primary key is a combination of partition key and clustering columns (if any). In Figure 3 above, the year in this example is the partition key. There’ll be as many partitions as there are distinct partition keys.
A partition key specifies which node will hold a particular table row. Clustering columns ensure data uniqueness and establish sorting order. Note that once you’ve set a primary key for your table, it can’t be changed.
Primary key and partitions in Cassandra
All data in Cassandra is organized with partition keys. Without understanding partitions, there’s little chance of building an efficient data model.
There are two kinds of partitions:
- Single-row: there’s only a partitioning key on a single column without clustering keys. Each partition can only store one row because the partition key uniquely identifies that row is a primary key
- Multi-row: has both a partition key and a clustering key. This means you can have many different rows in a partition. Cassandra uses a static column to describe the whole partition, not individual rows
Depending on the number of users, you can have as many partitions as you want. It’s a common misconception that a large number of partitions make your data model inefficient. Even billions of partitions won’t affect Cassandra’s performance. However, there are some limitations on the rows inside a partition. You usually don’t want to have more than a hundred thousand rows in a single partition.
Once you set a partition key for your table, a partitioner transforms the value in the partition key to tokens (also called hashing). It then assigns every node with a range of data called a token range. Then, Cassandra automatically distributes each row of data across the cluster by the token value.
Watch this video to learn more about Cassandra data structure through an example.
Cassandra Query Language
All above is done using Cassandra Query Language (CQL), which is the primary language for communicating with the database. There are two parts to CQL:
- Data definition: includes language to create keyspaces, tables, indexes, custom secondary indexes, and materialized view
- Data manipulation: includes language to run standard operations such as select, insert, update, and delete

Figure 4. Sample CQL Queries on Cassandra.
Figure 4 represents typical sample CQL queries on Cassandra. Everything works here because the queries match the clustering key (C) and partition keys (K).

Figure 5. Invalid CQL queries.
In Figure 5 you can see invalid CQL queries. The first two don’t work because they only specify half of the partition key venue so Cassandra can’t calculate the token. For the query to be valid, you need both venue and year.
The fourth query has both venue and year but still doesn’t work. This is because title is a data column, and not part of the primary key. The fifth query has a similar problem. Country is a static field and you’ll still need to calculate the partition using the partition key and clustering key.
To sum up, there are some important implications to keep in mind when working with data on Cassandra:
- Primary keys define data uniqueness
- Partition keys define data distribution
- Partition keys affect partition sizes
- Clustering keys define row ordering
When working with queries, consider the following:
- Primary keys define how data is retrieved from tables
- Partition keys allow equality predicates
- Clustering keys allow inequality predicates and ordering
- Only one table per query, no joins
These implications ensure that Cassandra can handle petabytes of data and answer your queries within milliseconds, while still being globally available with multiple data centers.
Cassandra data modeling methodology
Data modeling on Cassandra is a process to define and analyze data requirements. It lets you access data patterns needed to support a business process. It’s more than just schema design. It’s about:
- Collecting and analyzing data requirements
- Identifying participating entities and relationships
- Identifying data access patterns
- Organizing and structuring data in a particular way
- Designing and specifying a database schema
- Schema optimization and data indexing techniques
All of these points are essential. They will affect data quality (completeness, consistency, accuracy) as well as data access (queryability, efficiency, scalability). For a more detailed explanation, see our YouTube Tutorial: Data Modeling Methodology.
Moving on, there are four objectives of the Cassandra data modeling methodology:
- Conceptual Data Model: understand the data
- Application Workflow Model: identify access patterns
- Logical Data Model: apply the query-first approach and design tables based on queries
- Physical Data Model: optimize and implement
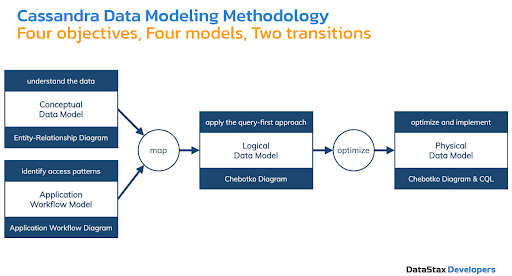
Figure 6. Cassandra data modeling objectives and tools.
Each model has certain tools that support it, as illustrated in Figure 6. The transitions between the models are usually the most difficult parts of data modeling. We’ll briefly touch on this below. If you want a deeper dive, we recommend taking one of our Cassandra courses on DataStax Academy.
Data modeling use cases in Cassandra
Let’s look at the data modeling process with a few Cassandra data modeling examples. We’ll focus on IoT sensor data modeling in particular. If you’re interested in other use cases, check out our investment portfolio data modeling and our order management data modeling tutorials.
IoT sensor data modeling
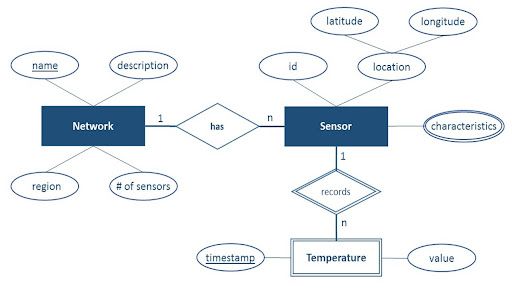
Figure 7. Entity-relationship diagram for IoT sensor data model.
The first example is sensor network or IoT data. It’s similar to the data you would see for a smart home system. This is how you would model it on Cassandra:
- Conceptual data model: this model features sensor networks, sensors, and temperature measurements. Each network has a unique name, description, region, and number of sensors. The sensor network can have many sensors, but each sensor can belong to only one network. Similarly, each sensor can take many temperature measurements, but each temperature measurement is taken by exactly one sensor
- Application workflow: this workflow is designed with the goal of understanding data access patterns for a data-driven application. There are four data access patterns for a database to support:
- Q1: Show all sensor networks
- Q2: Display a heat map for a network
- Q3: Display all sensors in a network
- Q4: Show raw temperature values for a sensor
- Logical data model: This model organizes data into Cassandra-specific data structures based on data access patterns. In this example, there are four tables designed to specifically support data access patterns Q1, Q2, Q3 and Q4, respectively:
- Networks
- Temperatures_by_network
- Sensors_by_network
- Temperatures_by_sensor
- Physical data model: You can create a physical data model directly from a logical data model by analyzing and optimizing for performance. This model defines data types and determines if we need secondary indexes or materialized views. The most common type of analysis is identifying potentially large partitions. Common optimization techniques include
- Splitting and merging partitions
- Data indexing
- Data aggregation
- Concurrent data access optimizations
In this example, the model optimizes data retrieval by creating a new partition key “bucket”. It also limits the growth of the partition size of a table by introducing a new partition key “week.” This technique is known as packeting.
Watch our YouTube video and visual representations of sensor data modeling for in-depth explanations. Then, run the sensor data modeling scenario to instantiate this data model on Cassandra.
The next two examples of data modeling deserve more time. So please watch this video or read all about them here:
Conclusion
Now you have an overview of the data structure on Cassandra and the process to create advanced data models crucial to building successful, global applications.
Don’t forget to check out Part 1 for an introduction to Cassandra. In Part 3 and Part 4 we'll discuss benchmarking your database and Storage-Attached Indexes. Part 5 will explain how you can migrate your SQL applications to NoSQL, then Part 6 will walk you through an exercise to put it all into practice.
For more workshops on Cassandra, check out DataStax’s Academy on GitHub and our DataStax Devs YouTube channel where we regularly host live workshops. If you have any specific questions about Cassandra, join the DataStax Community and get answers from the experts.
Resources
- YouTube Tutorial: Advanced Data Modeling in Apache Cassandra
- DataStax Academy on GitHub
- Cassandra Courses on DataStax Academy
- Data Modeling in Cassandra and DataStax Astra DB
- Data Modeling by Example
- Using the Chebotko Method to Design Sound and Scalable Data Models for Apache Cassandra
- A Big Data Modeling Methodology for Apache Cassandra
- A Beginner’s Guide to Benchmarking with NoSQLBench







