What is LlamaIndex? Exploring the World of LLM Orchestration Frameworks
LlamaIndex provides a complete set of tools for preparing and querying data for LLMs, including RAG. How does this streamline the data preparation process for AI models?
Sign Up for AstraBill McLane
CTO Cloud

What is LlamaIndex?
LlamaIndex is an orchestration framework that simplifies the integration of private data with public data for building applications using Large Language Models (LLMs). It provides tools for data ingestion, indexing, and querying, making it a versatile solution for generative AI needs.
With the rapid integration of generative AI into the application development process we are seeing an increasing need to be able to integrate our own private data with public data that is being used to train large language models (LLMs). The challenge this presents is that most private data is unstructured, siloed, and not in a format that can be readily accessible by LLMs.
In a recent webinar on Large Language Models for the Enterprise, we explored how LLMs can be used for applications beyond ChatGPT and how private data needs to be used to augment the public data that generally available LLMs are trained on. This is where solutions like LlamaIndex come into play as they provide an orchestration framework for building LLM apps using built-in tools to ingest and query private data.
Come with us and see how LlamaIndex can be used as a framework for data integration, data organization, and data retrieval for all your private data generative AI needs.
Using LlamaIndex as a Framework for Data Integration
As stated earlier, LlamaIndex is an orchestration framework or “data framework” that simplifies building LLM applications. What it provides is the ability to perform data augmentation of private data allowing it to be incorporated into LLMs for knowledge generation and reasoning.
At the heart of all generative AI functionality is data. Enterprise applications need to be able to access more than just the public data that LLMs are trained on and need to incorporate structured, unstructured, and semi-structured data from all their internal and external data sources for building applications.
LlamaIndex provides the integration of this data by bringing in data from multiple unique sources embedding that data as vectors, and storing that newly vectorized data in a vector database, allowing for that data to be used by applications to perform complex operations with low latency response times like vector search.
Benefits of LlamaIndex
- Simplified data ingestion connecting existing data sources like API’s, PDF’s, SQL, NoSQL, documents, etc. for use with LLM applications.
- Natively store and index private data for use across different application use cases, with native integration with downstream vector store/vector databases.
- Built-in query interface, providing the ability to return knowledge-augmented responses from input prompts on your data.
Use Cases for LlamaIndex
- Building natural language chatbots that provide real-time interaction with your product documentation for natural customer engagement.
- Building cognitively aware knowledge agents that can respond to changing decision trees based on a constantly growing knowledge basis.
- Interact with large volumes of structured data using natural language and human interaction.
- Augment public data with private knowledge corpus providing application-specific engagement.
Ready to unleash the full potential of real-time and generative AI? Discover the transformative capabilities of Datastax Astra DB and Apache Cassandra for semantic search. Learn more about how to unlock the power of Semantic Search.
How does LlamaIndex Work?
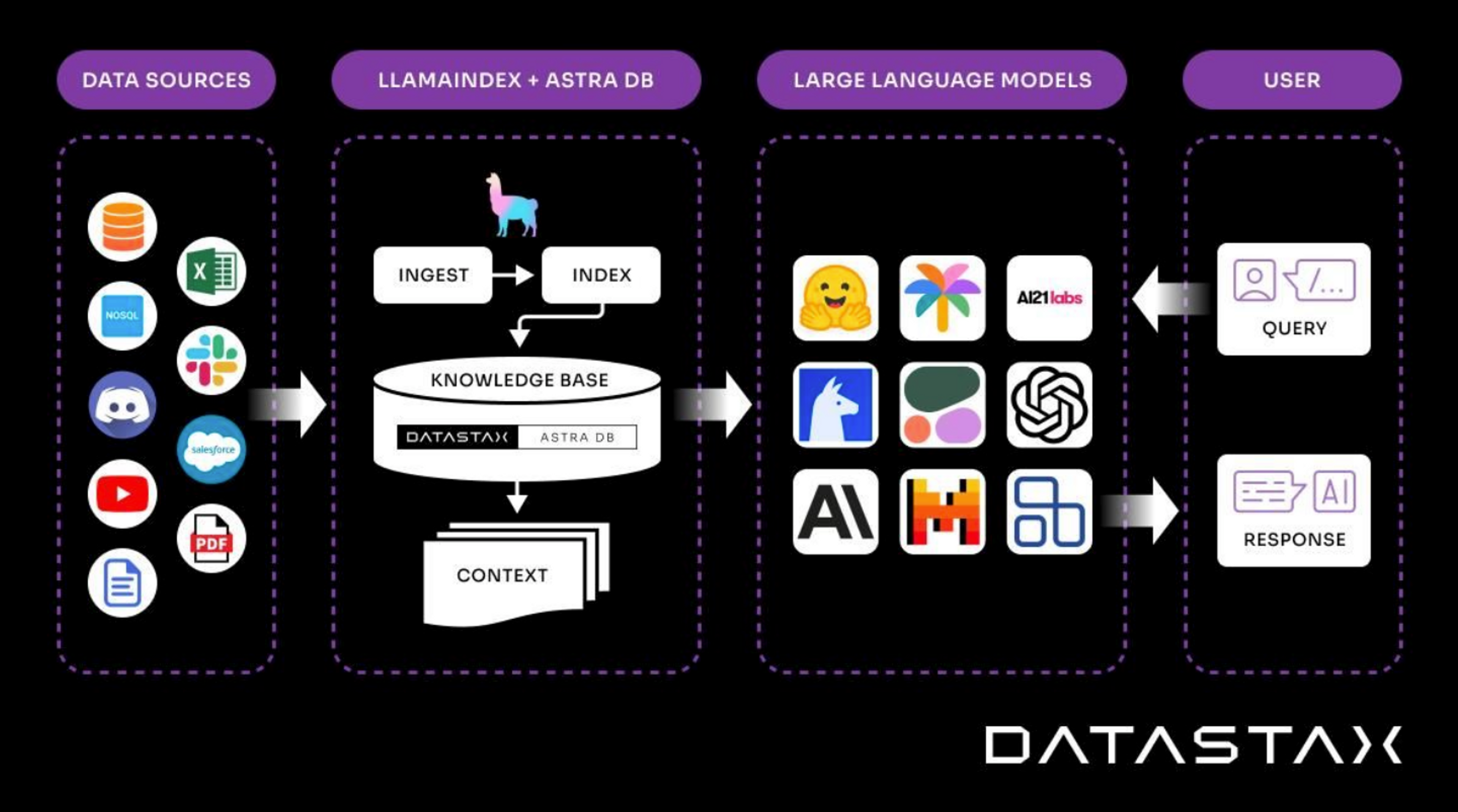
LlamaIndex, formerly known as GPT Index, is a framework that provides the tools needed to manage the end-to-end lifecycle for building LLM-based applications. The challenge with building LLM-based applications is that they need data, typically from multiple different sources, and unless there is strong adherence to a common data representation the data required is in many different formats, some highly structured, some unstructured, and some in between.
That is where LlamaIndex provides the toolbox to unlock this data with tools for data ingestion and data indexing. Once ingested and indexed, retrieval augmented generation (RAG) applications can use the LlamaIndex query interface for accessing that data and powering LLMs.
Ingestion
LlamaIndex has 100s of data loaders that provide the ability to connect custom data sources to LLMs. It connects pre-built solutions like Airtable, Jira, Salesforce and more to generic plugins for loading data from files, JSON documents, simple CSV, and unstructured data.
A complete list of data loaders can be found on the Llama Hub.
Indexing
Once data is ingested, that data needs to be mathematically represented so that it can be easily queried by an LLM. With LlamaIndex, an index simply provides the ability to represent data mathematically in multiple different dimensions. Indexing data isn’t a new concept however with machine learning, we can expand the granularity of indexing from one or two dimensions (key/value representation for example) to hundreds or thousands of dimensions.
The most common approach to indexing data for machine learning and LLMs is called a vector index and once data has been indexed the mathematical representation of the data is called a vector embedding. There are many types of indexing and embedding models but once data has been embedded the mathematical representation of the data can be used to provide semantic search as things like text with similar meanings will have a similar mathematical representation. For example, king and queen might be highly related if the query is royalty but not highly related if the query is gender.
Querying
This is where some of the real power of LlamaIndex and LLMs comes into play because querying data using LlamaIndex isn’t a complex series of commands to merge/join and find the data, it is represented as natural language via a concept called prompt engineering. The simplest way to view interaction with your data once you have ingested and indexed it is that querying becomes a process of asking questions and getting responses.
What are the Different Indexes in LlamaIndex?
LlamaIndex offers several different indexing models that are designed to provide optimizations around how you want to explore and categorize your data. This is ultimately where a lot of gains can be achieved, if you know the type of operation your application needs to perform on the data leveraging a specific type of index can provide significant benefit to the application using the LLM and instantiating the query.
List index
A list index is an approach that breaks down the data and represents the data in the form of a sequential list. The advantage this has is that while the data can be explored in a multidimensional manner the primary optimization to querying the data is via a sequential pattern. This type of index works well with structured objects that occur over time so things like change logs where you want to query how things have changed over time.
Tree index
When using a tree index, LlamaIndex takes the input data and organizes it into a binary tree structure where data is organized as parent and leaf nodes. A tree index provides the ability to traverse large amounts of data and construct responses where you need to extract specific segments of the texts based on how the search traverses the tree. Tree indexing works best for cases where you have a pattern of information that you want to follow or validate like building a natural language processing chatbot on top of a support/FAQ engine.
Vector store index
When using the vector store index type, LlamaIndex stores data notes as vector embeddings. This is probably the most common indexing type as it provides the ability to use the representation of the data in multiple different ways including vector or similarity search. When data is indexed with a vector store index, it can be leveraged locally for smaller datasets and by a single application or for larger datasets and/or to be used across multiple different LLMs/applications it can be stored in a high-performance vector database like Astra DB.
Keyword index
Keyword indexing is more of the traditional approach of mapping a metadata tag, i.e. a keyword to specific nodes that contain those keywords. This mapping builds a web of relationships based on keywords, because a keyword may map to multiple different nodes and a node may be mapped to multiple different keywords. This indexing model works well if you are looking to tag large volumes of data and query it based on specific keywords that can be queried across multiple different datasets. For example legal briefings, medical records, or any other data that needs to be aligned based on specific types of metadata.
What is LangChain?
LangChain is an advanced framework designed to enhance the capabilities of natural language processing. It achieves this by chaining together different AI language models and tools, allowing for more advanced and nuanced language understanding and generation. This makes LangChain a significant tool in the development of complex AI applications where sophisticated language skills are essential.

The framework's modular approach provides flexibility, enabling developers to create customized solutions for a variety of language processing tasks. From generating human-like text to sophisticated data analysis, LangChain's integration of multiple AI components opens up new possibilities in AI development and application, making it a key player in the evolving landscape of artificial intelligence.
LlamaIndex vs LangChain: Key Comparisons
One of the big questions that come up is how do LlamaIndex and LangChain compare, do they provide similar functionality or do they complement each other? The reality is that LlamaIndex and LangChain provide two different sides to the same coin. While they are both designed to provide an interface to LLMs and machine learning in your application, LlamaIndex is designed and built specifically to provide indexing and querying capabilities for intelligent searching of data. On the other side of that coin is the ability to interact with data either via natural language processing, i.e. building a chatbot to interact with your data, or using that data to drive other functions like calling code.
LlamaIndex provides the ability to store the data you have in a variety of different formats and pull that data from a bunch of different sources, ultimately providing the how for your generative AI application.
LangChain provides the ability to do something with that data once it has been stored, generate code, provide generative question answers, and drive decisions, ultimately providing the what for your generative AI application.
What Different Projects Can You Make with LlamaIndex?
With LlamaIndex you have an easy-to-use data/orchestration framework for ingesting, indexing, and querying your data for building generative AI applications. While we provide a simple example above to get started, the real power of LlamaIndex comes from the ability to build data-driven AI applications. You don’t need to retrain models, you can use LlamaIndex, and a highly scalable vector database to create custom query engines, conversational chatbots, or powerful agents that can interact with complex problem-solving by dynamically interpreting the data coming in and making contextual decisions in real-time.
What are the Potential Challenges and Limitations of LlamaIndex?
While LlamaIndex offers powerful capabilities in data indexing and retrieval, it's important to be aware of its potential challenges and limitations. Here are some specific challenges you might encounter:
Data Volume and Indexing Speed
Handling large volumes of data can be challenging. LlamaIndex may face difficulties in quickly indexing extensive datasets, affecting the efficiency of data retrieval.
Integration Complexity
Integrating LlamaIndex with existing systems or various data sources can be complex. Ensuring seamless integration often requires technical expertise and can be time-consuming.
Accuracy and Relevance of Results
Ensuring the accuracy and relevance of search results is a critical challenge. Fine-tuning LlamaIndex to return the most relevant results based on specific queries requires careful configuration and continuous optimization.
Scalability
As the volume of data grows, scaling LlamaIndex to maintain performance without significant resource allocation can be challenging.
Maintenance and Updates
Regular maintenance and updates are crucial for LlamaIndex to function effectively. Keeping up with the latest updates and ensuring compatibility with other system components can be demanding.
Build real-time, Generative AI Apps with Vector Search on Datastax Astra DB
So when it comes time to build a generative AI application that needs the ability to leverage your private data and incorporate that into an application's ability to interact and respond to that data, LlamaIndex is a great place to start for ingestion, indexing, and querying. But don’t repeat the mistakes of the past and silo the data you are using, embedding, and accessing for AI applications. Build out a complete end-to-end solution that includes storing those embeddings and indexes in a highly scalable vector store like Astra DB.

To get started with LlamaIndex and to see how Datastax and LlamaIndex are better together check out our recent blog post on Building Petabyte-Scale GenAI Apps Just Got Easier.
Also, you can find more information on how to set up and deploy Astra DB on one of the world’s highest performing Vector Stores built on Apache Cassandra which was designed for handling massive volumes of data at scale. To get started for free, register here.
Datastax provides the real-time vector data and RAG capabilities that Gen AI apps need, with seamless integration with developers’ stacks of choice (RAG, Langchain, LlamaIndex, OpenAI, GCP, AWS, Azure, etc)