What are vector embeddings?
Vector embeddings are numerical representations of data that capture semantic relationships and similarities, making it possible to perform mathematical operations and comparisons on the data for tasks like text analysis and recommendation systems.
With all the talk about generative AI, the concepts behind what powers generative AI can be a little overwhelming. In this article we'll focus on the one functional concept that powers the underlying cognitive ability of AI and provides machine learning models the ability to learn and grow: a vector embedding.
A vector embedding is, at its core, the ability to represent a piece of data as a mathematical equation. Google’s definition of a vector embedding is “a way of representing data as points in n-dimensional space so that similar data points cluster together.”
For people who have strong backgrounds in mathematics, I'm sure these words make perfect sense. For those of us who struggle with visual representations of mathematical concepts, this might sound like gibberish.
Understanding vector embeddings and the mathematical representation of data
So, let’s look at this another way. You have a bowl full of M&Ms that you like to snack on, and your youngest offspring decides to be cheeky and mix in a bowl full of Skittles candies. For those not necessarily familiar with these two things, M&Ms and Skittles are two colorful candy-shelled treats that look very similar. However, one is chocolate and the other is citrus - two flavors that don’t mix well.
To remedy the situation, we need to sort the candies, so we sort them by type and color. All the green M&Ms go together in one pile, all the green Skittles go together in another pile, all the red M&Ms and all the red Skittles, and so on and so on.
When we're done, we have distinct piles of M&Ms and Skittles separated by color. We can arrange them visually such that we can quickly see where a new candy falls.
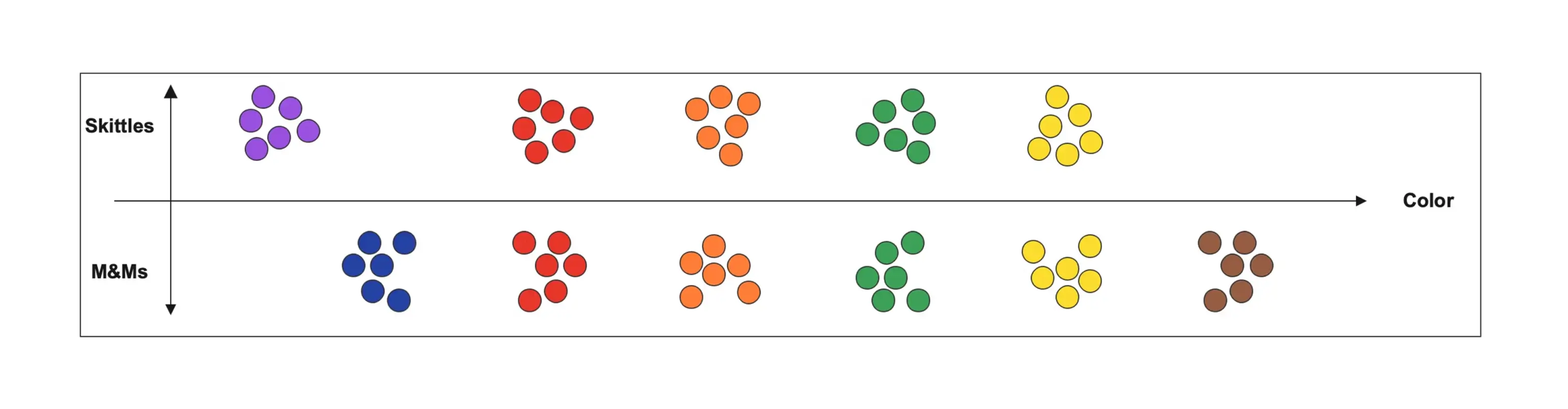
You can see that in sorting our candies, we have already started to lay out patterns and groupings that can make it easier to relate the candies together and to find the piles we need when sorting new candies as we find them.
A vector embedding takes this visual representation and applies a mathematical representation to its position. A simple way to think about this is if we assign each position with a different value.
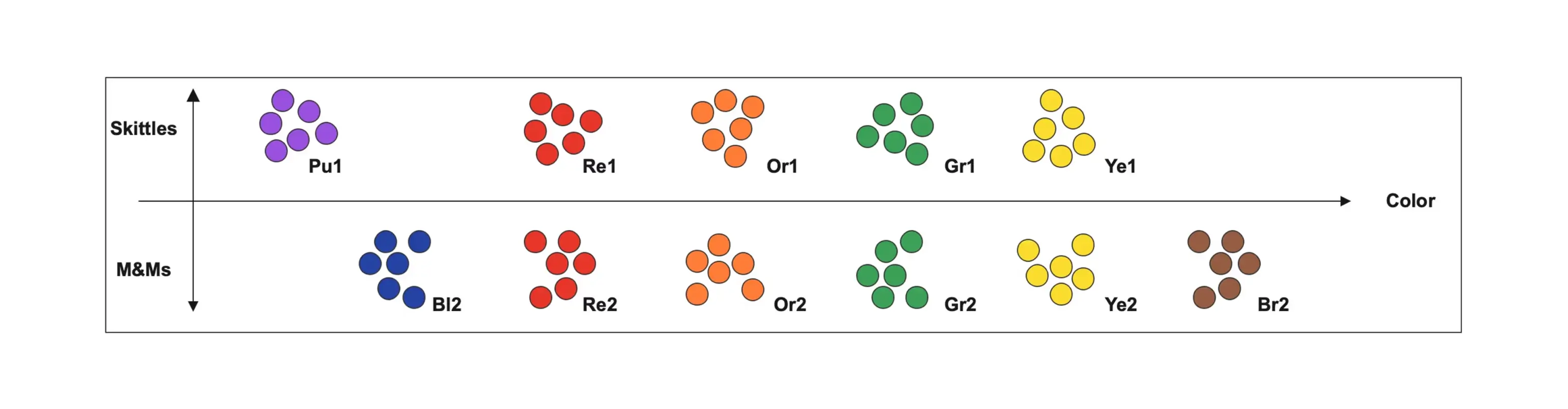
With our candies, we can now assign a value to that candy based on its attributes and put the new candy into the correct position based on that number. This is ultimately what a vector embedding is, albeit with far more complexity.
This mathematical representation at the foundation of cognitive ability gives generative AI and machine learning models like natural language processing, image generation, and chatbots the ability to collate neurological-like inputs and make decisions.
A single embedding is like a neuron. Just as a single neuron doesn’t make a brain, a single embedding doesn’t make an AI system. The more embeddings and the more relationships between those embeddings, the more complex cognitive abilities become. When we group large volumes of embeddings into a single repository that can provide fast scalable access like a brain, we call it a vector database like DataStax Astra powered by Apache Cassandra®.
But to truly understand vector embeddings and their profound value to generative AI, we must understand how they can be used, how they are created, and what types of data they can represent.
Example: Using vector embeddings
One of the challenges with vector embeddings is that they can represent almost any kind of data.
If you look at most data types used in computer science/programming languages, they all represent a finite form of data. Chars were designed to represent characters, ints were designed to represent whole numbers, and floats were designed to represent more finite numerical representations with decimal points. New data types have been created to enhance these base data types, like strings and arrays, but those types still tend to be only able to represent a specific type of data.
On the surface, a vector data type is just an extension of an array that allows multidimensionality and directionality when graphed. The biggest advancement with vectors, however, is that functionally any type of data can be represented as a vector. More importantly, that data can be compared to other pieces of data and similarity can ultimately be mapped within those multidimensional planes.
To really understand what a vector is and how it can be used, let's start with one of the early implementations, Word2Vec invented by Google in 2013.
Word2Vec is a technique for taking words as input, converting them into vectors, and using those vectors to create graphs that visualize clusters of synonyms.
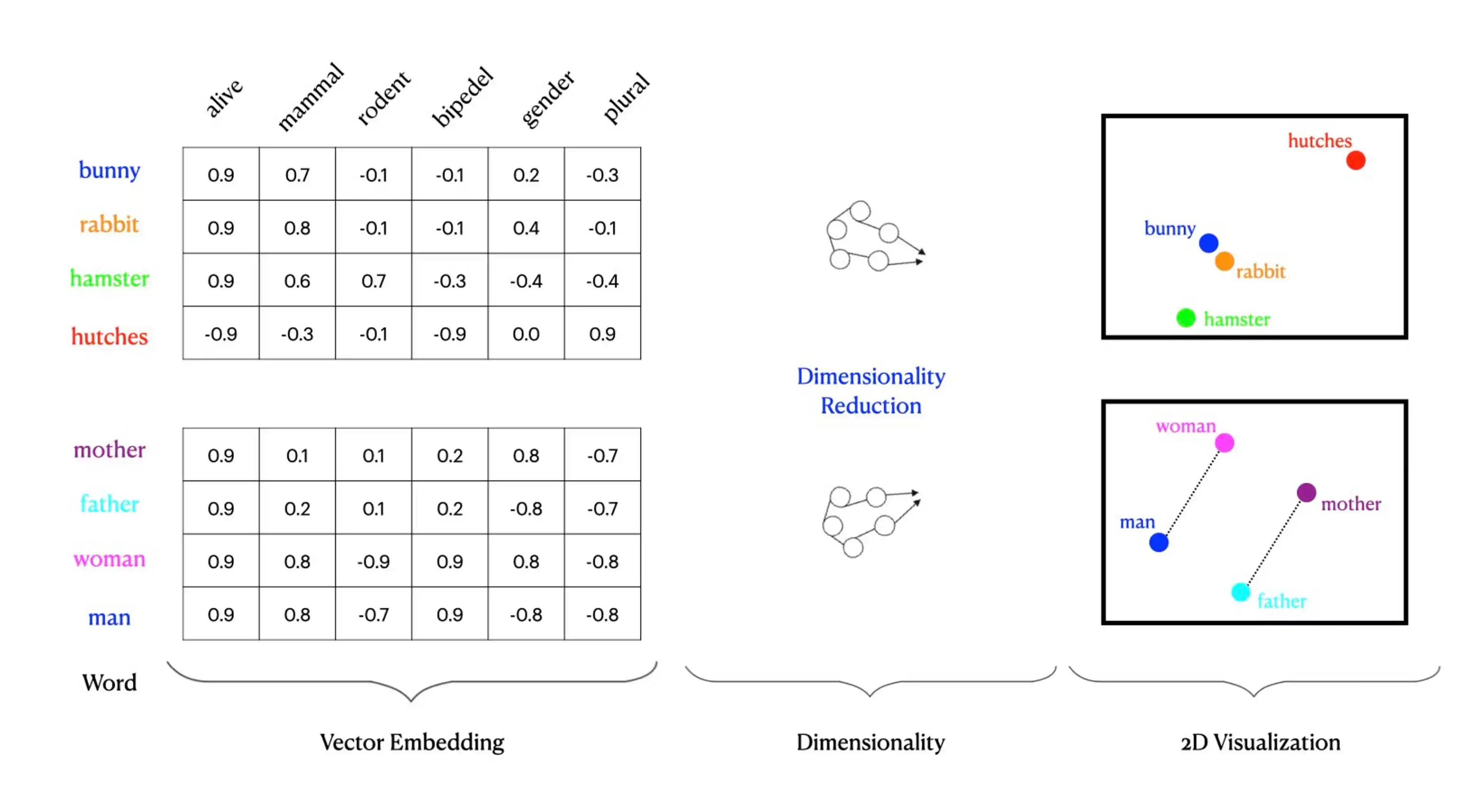
The way Word2Vec functionally works is that each creates an n-dimensional coordinate mapping or a vector. In our above example, we have a 5-dimensional coordinate mapping; true vector mappings can have hundreds or thousands of dimensions, far too many for our minds to visualize or comprehend. This high dimensional data allows machine learning models to correlate and plot the data points for things like semantic search or vector search.
In our above diagram, you can see how certain words naturally get grouped based on similarity. Bunny and rabbit are more closely related to each other compared to hamster. All three words, bunny, rabbit, and hamster, are more closely grouped based on vector properties to each other compared to hutches. This directionality within the n-dimensional space allows neural networks to process functionality like nearest neighbor search.
What are the applications of vector embeddings?
So, how does this get applied? One of the easiest ways to visualize this is in recommendation engines.
For example, say you're streaming your favorite show. If I take the qualities and aspects of that show and vectorize them, and then I take the qualities and aspects of all other shows and vectorize them, I can now use those qualities to find other shows that are closely related to the show I am watching based on directionality.
With machine learning and AI, the more shows I watch and like, the more information the system gains from what areas of the n-dimensional graph interest me. It makes recommendations for my tastes based on these qualities.
Another applied example is search. For example, Google’s reverse image search.
Doing a reverse image search with vectors is extremely fast and easy because when the image is given as input, the reverse search engine can turn it into a vector. Then, using vector search, it can find the specific place in the n-dimensional graph where the image should be and provide the user with any additional metadata it has around that image.
The application of data vectorization is truly limitless at this point. Once data is turned into vectors, you can perform tasks such as fraud or anomaly detection. Data processing, transformation, and mapping can be part of a machine-learning model. Chatbots can be fed production documentation and provide a natural language interface to interact with users trying to figure out how to use a specific feature.
Vector embeddings are the core component of enabling machine learning and AI. But once data is turned into vectors, we need to store all the vectors in a highly scalable, highly performant repository called a vector database. Once data has been transformed and stored as vectors, that data can power multiple different vector search use cases.
Creating vector embeddings
So what goes into a vector embedding, and how is it created?
Creating a vector embedding starts with a discrete data point that gets transformed into a vector representation in a high dimensional space. It's easiest to visualize in a low 3d space for our purposes.
Let’s say we have three discrete data points: the word cat, the word duck, and the word mudskipper. We will evaluate those words on whether they walk, swim, or fly.
Let’s take the word cat. A cat primarily walks so let's assign a value of 3 for walking. A cat can swim, but most cats don’t like to swim, so let’s assign a value of 1 for that. Lastly, I don’t know of any cats that can fly on their own, so let's assign a value of 0 for that.
So the data points for cat are:
Cat: (Swims- 1, Flys- 0, Walks - 3)
If we do the same for the word duck and mudskipper (a type of fish that can walk on land) we get:
Duck: (Swims, Flys - 2, Walks - 2)
Mudskipper: (Swims - 3, Flys - 0, Walks – 1)
From this mapping we can then plot each word into a 3 dimensional chart and the line that is created is the vector embedding. Cat [1,0,3], Duck [2,2,2], Mudskipper [3,0,1].
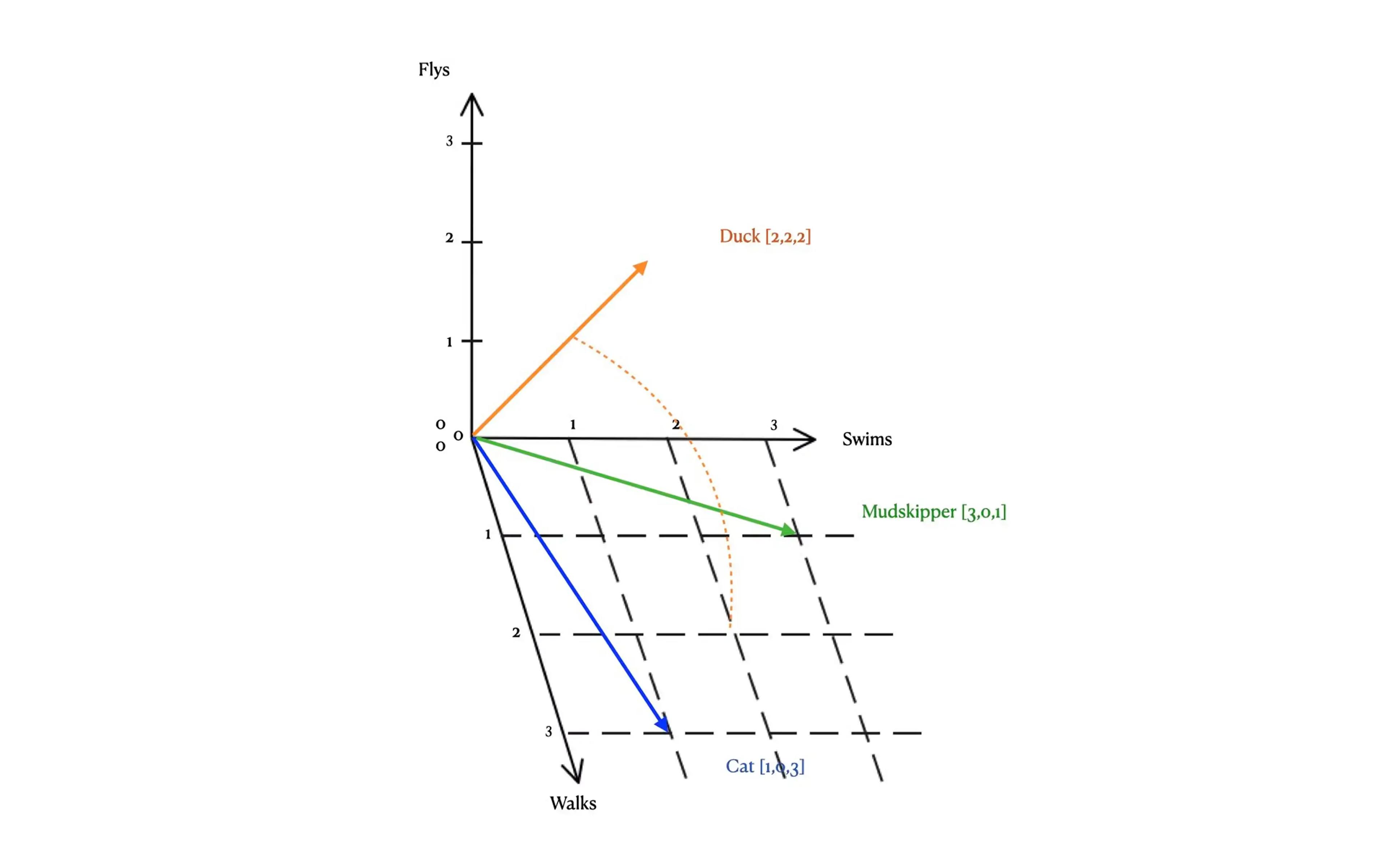
Once all our discrete objects (words) have been transformed into our vectors, we can see how closely they relate based on semantic similarity. For example, we can see that all three words get plotted onto the z-axis because all three animals can walk.
The true power of machine learning comes when you look at the vector representations across planes of the graph. For example, if we compare the animals' walking and swimming patterns, we can see that a cat is more closely related to a duck than a mudskipper.
In our example, we only have a 3-dimensional space, but with a true vector embedding, the vector spans an N-dimensional space. Machine learning and neural networks use this multidimensional representation to make decisions and enable hierarchical nearest-neighbor search patterns.
When creating vector embeddings, we can take two approaches:
- Feature engineering, which takes domain knowledge and expertise to quantify the set of “features” that will be used to define the different vertices of the vector, or
- Using a deep neural network to train models to translate objects into vectors.
Training models tend to be the most common approach. Feature engineering, while providing a detailed understanding of the domain, takes too much time and expense to scale. By contrast, training models can generate densely populated, high-dimensional (1000s of dimensions) vectors.
Pre-trained models
Pre-trained models are models that have been created to solve a general problem that can be used as is or as a starting point to solve complex, finite problems. There are many examples of pre-trained models available for different types of data. BERT, Word2Vec, and ELMo are some of the many models available for text data. These models have been trained in huge datasets and transform words, sentences, and entire paragraphs and documents into vector embeddings.
However, pre-trained models aren't limited to text data. Image and audio data have some pre-trained models that are generally available as well. For example, models like Inception, which used a convolutional neural networks (CNNs) model, and Dall-E 2 which used a diffusion model.
What types of things can be embedded?
As we mentioned, vector embeddings can represent any type of data as a vector embedding. There are many current examples where text and image embeddings are being heavily used to create solutions like natural language processing (NLP) chatbots using tools like GPT-4 or generative image processors like Dall-E 2. Here are just a few examples of different vector embeddings in more detail.
Text embeddings
Text embeddings are probably the easiest to understand, and we have been using them as the foundation for most of our examples. Text embeddings start as a data corpus of text-based objects, so large language models like Word2Vec use large datasets from things like Wikipedia. But text embeddings can be used for pretty much any type of text-based dataset that you want to quickly and easily search for nearest neighbor or semantically similar results.
For example, say you want to create an NLP chatbot to answer questions about your product; you can use text embeddings of the product documentation and product FAQs to allow the chatbot to respond to queries based on questions posed. Or what about feeding all of the cookbooks you have collected over the years as the data corpus and using that data to provide recipes based on all the ingredients you have in your pantry? Text embeddings bring the ability to take unstructured data like words, paragraphs, and documents and represent them in a structured form.
Image embeddings
Image embeddings, like text embeddings, can represent multiple aspects of images. From full images down to individual pixels, image embeddings can classify an image's set of features and present those features mathematically for analysis by machine learning models or for use by image generators like Dall-E 2.
One of the most common usages of image embeddings is used for classification and reverse image search. For example, suppose I have a picture of a snake taken in my backyard, and I would like to know what type of snake it is and if it is venomous. With a large data corpus of all the different types of snakes, I can feed the image of my snake into the vector database of all the vector embeddings of snakes and find the closest neighbor to my image. From that semantic search, I can pull all the “attributes” of the nearest neighbor image to my snake and determine what kind of snake it is and if I should be concerned.
Another example of how vector embeddings can be used is automated image editing, like Google Magic Photo Editor, which allows images to be edited by generative AI, making edits to specific parts of an image, like removing people from the background or adding better composition.
Product embeddings
Another example of how vector embeddings can be used is in recommendation engines. Product embeddings can be anything from movies and songs to shampoos. With product embeddings, e-commerce sites can observe shoppers' behaviors through search results, click stream, and purchase patterns and make recommendations based on semantic similarity for new or niche products.
Say, for example, that I visit my favorite online retailer. I'm perusing the site and adding things to my cart for the new puppy I just got. I add puppy food (I’m running low), a new leash, a dog bowl, and a water dish.
I then search for tennis balls because I want my new puppy to have some toys to play with.
Now, am I really interested in tennis balls... or dog toys?
If I was at my local pet store and somebody was helping me, they would clearly see that I'm not really interested in tennis balls. I'm interested in dog toys. What product embeddings bring is the ability to glean this information from my purchase experience, use vector embeddings generated for each of those products, focused on dogs, and predict what I'm looking for - which is dog toys, not tennis balls.
Document embeddings
Document embeddings extend the concept of text embeddings to larger bodies of text, such as entire documents or collections of documents. These embeddings capture the overall semantic meaning of a document, enabling tasks like document classification, clustering, and information retrieval.
For instance, in a corporate setting, document embeddings can help categorize and retrieve relevant documents from a large internal repository based on their semantic content. They can also be used in legal tech to analyze and compare legal documents.
Audio embeddings
Audio embeddings translate audio data into a vector format. This process involves extracting features from audio signals - like pitch, tone, and rhythm - and representing them in a way that machine learning models can process.
Applications of audio embeddings include voice recognition, music recommendation based on sound features, and even emotion detection from spoken words. Audio embeddings are crucial in developing systems like smart assistants that can understand voice commands or apps that recommend music based on a user's listening history.
Sentence embeddings
Sentence embeddings represent individual sentences as vectors, capturing the meaning and context of the sentence. They are instrumental in tasks such as sentiment analysis, where understanding the nuanced sentiment of a sentence is crucial.
Sentence embeddings can also play a role in chatbots, enabling them to more accurately comprehend and respond to user inputs. Moreover, they're vital in machine translation services, ensuring the translated sentences retain the original meaning and context.
How to get started with vector embeddings
The concepts of vector embeddings can be pretty overwhelming. Thankfully, many tools are available that allow for the creation of vector embeddings, such as Word2Vec, CNNs, and many others.
The real challenge lies in what you do with that data, how it is stored, accessed, and updated.
While this may sound complex, vector search on Astra DB provides a fully integrated solution featuring all the pieces you need for contextual data built for AI. From the digital nervous system, Astra Streaming, built on data pipelines that provide inline vector embeddings, to real-time large-volume storage, retrieval, access, and processing via Astra DB, the most scalable vector database on the market today.









