Last month you heard of an amazing new restaurant that opened up down the street and everybody has been telling you how amazing the food is. You finally get a reservation to try out the place. From what you’ve heard, the food is amazing here, so you excitedly await as they bring you their signature dish.
But when it arrives, it doesn’t look amazing.
It doesn’t even look appetizing. It looks like slop and, even though it smells amazing and everybody around you is eating it up and raving about it, you just cannot get past how it looks.
One of the old sayings in the restaurant industry is “you eat with your eyes.” This, while somewhat unconscious, is very true. When it comes to food, we use more than our sense of taste. We use all of our senses to enhance the experience of eating. If something doesn’t look good, it is hard for it to taste good. If something doesn’t smell good, it is very hard to get past the smell to enjoy the taste—Durian, I’m looking at you on this one.
In a way, multimodal AI fits into this same category.
AI-based applications have been around for many years now, but recent advances in generative AI and large language models (LLMs) have made artificial intelligence far more accessible: beyond analytics, AI has moved into general purpose application. But this has also changed the expectation of what AI provides—from completing and predicting text to AI applications that leverage information from multiple unique, relevant data sources.
Multimodal AI incorporates visual aspects like images and video, and integrates audio aspects like speech recognition or synthesis.
The multimodal model incorporates multiple “senses” to generative AI that unlocks AI’s real potential.

Futuristic concepts like real-time language translation are now possible with multimodal AI. But even more power comes into play when you
- tie in speech recognition
- synthesize language translation
- capture video of somebody using American Sign Language (ASL)
This effectively gives the deaf the ability to speak.
This is why multimodal AI is so important—it unlocks the potential of leveraging high-compute AI to work across multiple modalities and provide contextual, relevant outputs based on multiple data types.
This is ultimately where the true potential of AI will be realized.
In this guide, we explore multimodal AI
- technologies
- use cases
- challenges.

Technologies Associated with Multimodal AI
When it comes to multimodal AI models, there are 3 primary modules that fit together:
- input module
- fusion module
- output module
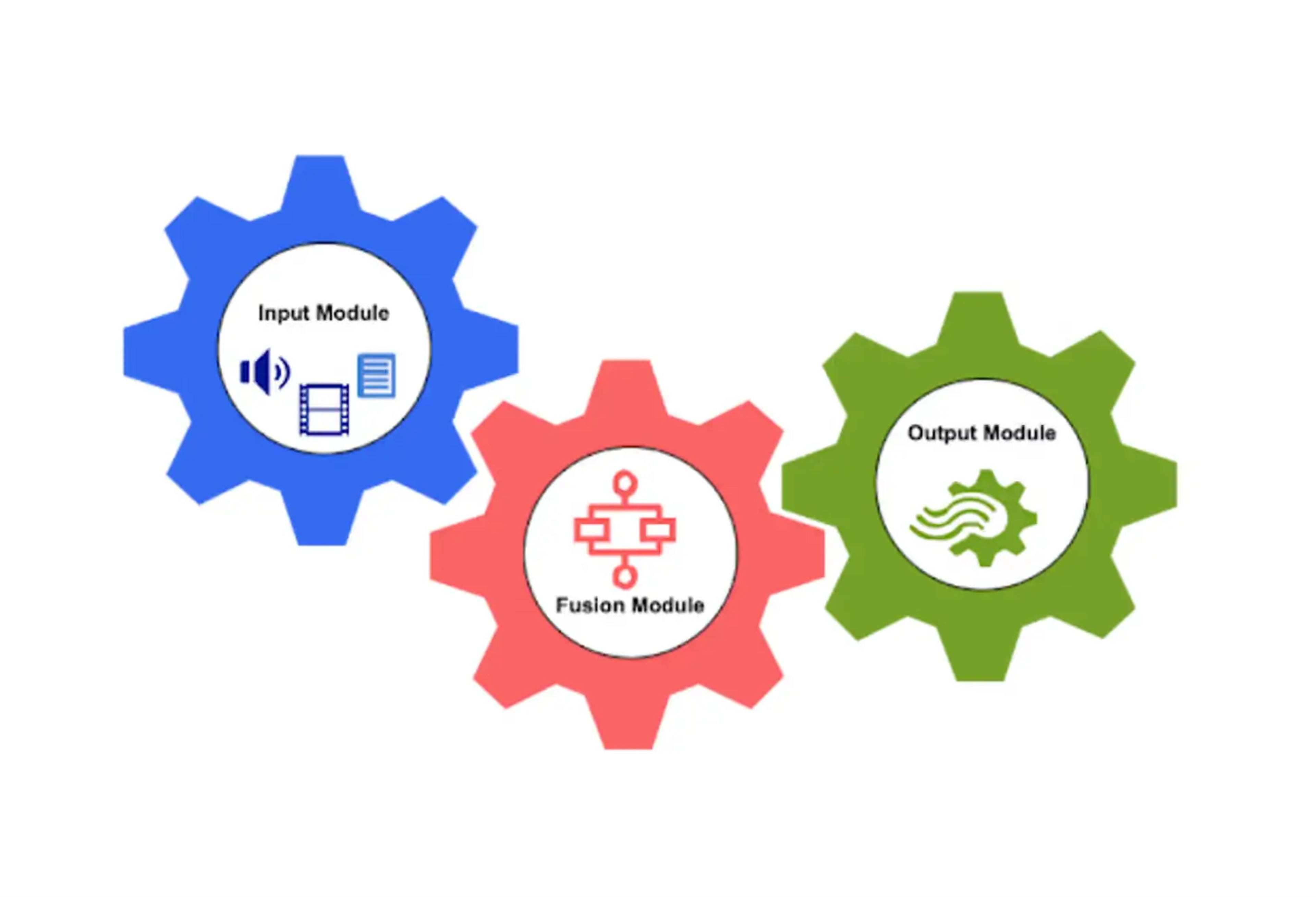
Input module (the nervous system)
Input modules bring in and process different modalities. The input module normalizes different data types and ensures that they are downstream-compatible with the AI model’s ability to process and analyze the data.
Think of the input module as the nervous system: It takes inputs from different stimuli, like text, video/image, audio and sensor data and integrates it into a fusion module to unify the mathematical representation for downstream processing.
Fusion module
Fusion modules bring together the information from each of the input modalities and ultimately create the unified representation.
Fusion modules have multiple techniques depending on the strategies used.
Early fusion (feature-level fusion)
Early fusion (feature-level fusion) combines the raw features of each input. This is typically used for combining data like text embeddings and image features.
Late fusion (decision-level fusion)
Late fusion (decision-level fusion) processes each modality separately and then combines the outputs for deeper decision making. Combining satellite imagery and historical text data for better weather forecasting is a good example.
Output modules
Output modules take the unified representation of the fusion module and curates it into the specific output format. The output module can take on many forms depending on the desired output context.
If the desired output context is to make a decision, the output module classifies the fusion module’s output and provides sentiment around a prediction—or diagnoses a given set of conditions.
If the desired output is generative, the output module might create new content based on the fusion module’s output: creating synthesized text to speech or creating text descriptions of images, for example.
Output modules present the outcomes. This could be providing medical diagnostics or robotic automation for autonomous vehicles to providing sentiment analysis using facial recognition.

What is the difference between multimodal and generative AI?
Terminology is a challenge in the world of AI. And there is more than one AI model.
Generative AI models are all the rage, but generative AI and multimodal AI are different things. Generative AI uses data to train models, which then use that data to create new content that is similar to the original data.
Multimodal AI refers to processes that understand multiple types of data simultaneously.
The main difference is that multimodal AI processes and understands multiple types of data inputs.
Multimodal AI requires the ability to process and understand. Generative AI finds similarities between data and generates new data based on those similarities.
Generative AI can be one of many output modules of a multimodal AI process.
For a deeper understanding of multimodal AI and how generative AI is an umbrella term used to describe machine learning to create new content, visit Google’s multimodal AI use cases section.

Multimodal stack technologies
Retrieval-augmented generation (RAG) is the foundation of the multimodal AI technology stack. There are a number of different components that come together to provide Input, Fusion, and Output results. With RAG, these components seamlessly interact with each other to provide the complete AI experience.
Natural language processing
Probably the most important advancement in AI has been natural language processing (NLP). With NLP, multimodal AI interacts with data and humans in a natural way and use these interactions in conjunction with diverse data types like images, video, sensor data, and much much more. NLP creates a human-computer interaction that wasn’t possible in the past.
Computer vision
NLP opens the AI world to language. Computer vision technologies open the AI world to visual data. With computer vision, AI interprets, understands, and processes visual information like images and videos—summarizing, captioning, or interpreting the visual data in real-time. From this, AI creates real-time transcripts or captions for the deaf, or audio interpretation for the blind.
Text analysis
Text analysis works with NLP to understand, process, and generate documents for use in Multimodal AI systems. This is seen in NLP chatbots that use product documentation, emails, or other text based inputs as training data, generating text-based responses or outputs.

Integration systems
Something required for successful multimodal AI systems is the ability to integrate with external data sources. Leveraging a RAG-based architecture prioritizes this integration and makes integration a core part of the technology stack used by multimodal AI systems.
RAG provides the foundation for bringing in multiple data inputs. And RAG distributes the outputs to applications in application-specific structures. This allows legacy-based systems and newly-developed applications to integrate seamlessly into the AI process.
Storage and compute
This is probably the broadest scoped technology in the multimodal AI technology stack. Storage and compute have critical impact on the development, deployment, and operation of the AI system. When it comes to storage, a multimodal AI system needs the ability to provide data storage, data management, and version control for all of the unique datasets used by the AI system. In addition, it needs significant computation power that can be used for training, real-time data processing, and data optimization.
Traditional environments have brought storage and compute together, but in modern multimodal AI systems, segmentation and virtualization of storage and compute operations provide significant benefit.
Newly-developed hyper-converged infrastructure (HCI) and solutions that are optimized for HCI, like DataStax Hyper-Converged Database, bring together all the components needed to deploy and integrate storage and compute resources with data, workflow orchestration, and data pipelines.
Use cases for multimodal AI
When generative AI was introduced, the primary use case was building natural language processing (NLP) chatbots around documents. We see the true transformative nature of AI in the growth of multimodal AI.
Multimodal AI is helpful across multiple industries
What is interesting is that multimodal transformation has different impacts on different industries. It significantly impacts how we engage with the world around us.
Healthcare
Back in 2020 when Covid 19 was at its peak, we saw a rapid growth of telemedicine. People could meet virtually with physicians to provide safe and expedited personal healthcare. Today, with multimodal AI virtual offices, visits include pictures, text, audio, and video that’s analyzed by an AI physician's assistant. Symptoms from all the different inputs are evaluated and a rapid diagnosis is provided for things like burns, lacerations, rashes, allergic reactions, etc.
We’ve also seen the rise of electronic medical records (EMR) that replace paper folders (with alphabetized last name labels). From there, electronic health records (EHR) efficiently share digital patient records (EMRs) across practices. This digital visibility positively impacts patient care—doctors spend more time treating patients and less time tracking down and managing patient information.
Retail
In retail, multimodal AI provides personalized experiences based on images, video, and text. How many of us have ordered clothing from an online retailer only to realize that it doesn’t look as good as it did in the picture? With multimodal AI, consumers can now upload images/videos of themselves and generate 360 degree views of garments on their bodies. This advancement shows how it fits, looks, and flows in a natural way prior to making the purchase.
Entertainment
Like retail, multimodal AI has the potential to revolutionize the entertainment industry. Content consumers provide multiple input types from personalized content suggestions to real-time gaming content based on gamers’ experiences. Gaming may offer incentives when a player is losing, for example.
With multimodal AI, these games leverage video input of player sentiment to create offers before the players get frustrated and quit playing. Or they tailor the gaming experience based on that sentiment, presenting custom, real-time content that players enjoy.
Multimodal AI and language processing
The possibilities for multimodal AI and language processing are limitless.
Incorporating facial expressions, tone of voice, and other stimuli changes the way we interact with technology.
- Customer service assistants listen to customer support calls and provide real-time analysis of customer frustration levels.
- Manufacturing processes incorporate multimodal AI for tolerance and waste management by incorporating text, video, and imagery.
Multimodal AI changes what technology can do in our lives.

Challenges of Multimodal AI
The promise is there, but the challenges around multimodal AI are real.
The reality: multimodal AI has huge potential, but it requires data. Not only does it require data, but that data has to be high quality. High quality data, however, isn’t unique to AI based applications—we have been discussing data quality for years.
The challenge that multimodal AI presents is that the volume of data needed for AI systems to learn and make decisions is exponentially higher compared to traditional applications, especially when multimodal AI data comes from multiple structured and unstructured sources including real-time events and telemetry data.
Volume of data is one thing, but another challenge is limited or missing data sets.
Since multimodal AI depends on data from multiple sources, it’s imperative that each of those sources has enough easily-available data to use across the application.
Let’s take our retail example above, consumers upload images to provide a 360 degree view of garments that fit their specific body types. But what if I have limited or missing data for a specific segment of my consumers? Say, for example, I add an entire men’s line of fashion but I don’t have enough images of different body types. This presents inaccurate or wrong responses, resulting in a bad customer experience.
In addition to having enough data, data lineage becomes vitally important for AI systems.
Knowing where the data comes from and that it is factual, proven, and of high enough quality, is extremely important to build confidence in the response multimodal AI provides. If data comes from unknown, or unproven sources, things like bias or misinformation can creep into multimodal AI systems.
Lastly, though AI systems have made significant advancements around Natural Language Processing (NLP), the reality is that AI still has difficulty with things like colloquialisms and sarcasm. What this means is that when AI systems are being trained, some level of understanding of the audience needs to be taken into account.
Smart context of who, what, when, where, and how becomes vitally important.
How to use multimodal AI for your business
Addressing challenges might seem overwhelming, but leveraging multimodal AI in business is very achievable with process forethought and by following simple guidelines.
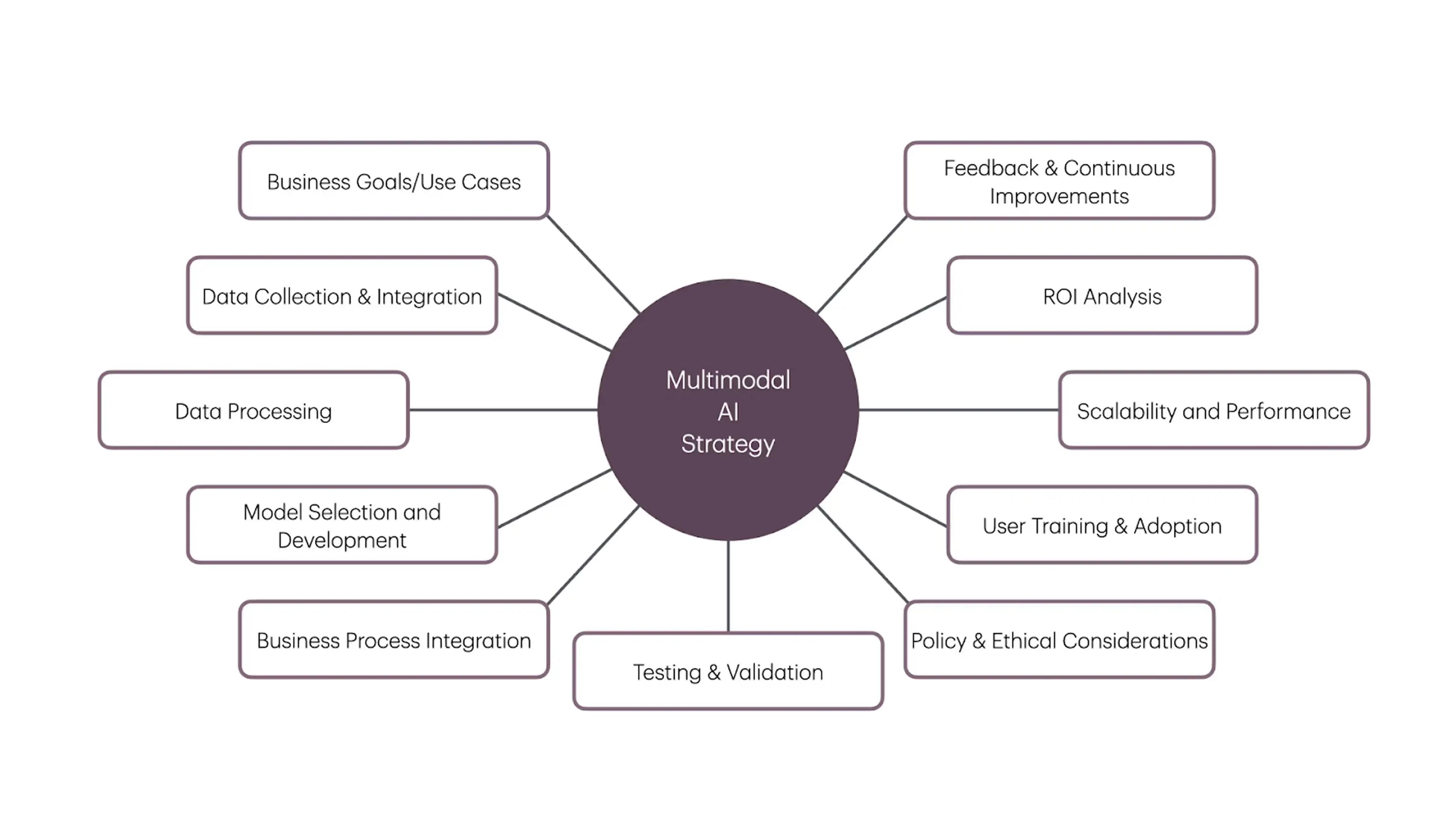
- Identify business goals and use cases: This is the first step in the process. Clearly define why your business should leverage multimodal AI and have a clearly-defined use case that is tangible.
- Data collection and integration: Next, the right approach to data collection and integration is key. One primary question that needs to be asked is “Can and should the data we use be shared across multiple AI applications?” Leveraging an architecture like retrieval-augmented generation (RAG) may be worth the initial investment.
- Data processing: Once you have an approach and you’ve defined inputs, look at how you’ll process data—ultimately defining the fusion model/approach you will use.
- Model selection and development: The other question is whether a general purpose large language model (LLM) is needed? Would a small language model that has been fine-tuned to a specific domain be more appropriate? Most applications should not develop a model from scratch, but leveraging a small language model for domain-specific knowledge can provide value.
- Scalability and performance monitoring: Leveraging multimodal AI within the business takes into account scalability and performance. With massive amounts of data being used to train and prompt multimodal AI systems, monitoring system scalability and performance is required to meet users’ demands, manage costs, and provide predictable response times.
- Integration into business processes: Once the technology decisions have been made, the next layer looks at how responses will integrate into the business process. This is where starting with a RAG approach provides significant benefit, because business processes can be natively-integrated into the workflow.
- Testing and validation: One of the interesting challenges of multimodal AI is the impact inaccurate results have on perception. A human answering random questions with 80% accuracy would be considered pretty good. But a machine with 80% accuracy is considered intolerable. Because of this, testing and Human-in-the-Middle validation is key.
- Privacy and ethical considerations: Another concern that has to be weighed is data sensitivity and the ethical considerations of using specific data. Is the data fed into the AI workflow managed, curated, and protected appropriately to protect the users and consumers of that data? This is where organizations need strong data governance when using data for training AI systems.
- User training and adoption: AI systems in place, proper user training is key to successful adoption. The potential of multimodal AI to change the way an individual works and communicates is massive, but that potential comes with a significant change in how users perform their day to day operations. Being able to showcase productivity improvements by training users how to leverage these new technologies is key to wide-scale adoption.
- Feedback and continuous improvement: Recursive feedback from users and the AI systems is fundamental to providing continuous improvement and more accurate responses. Things like human sentiment, Human-in-the-Middle validation, and response feedback loops, give good AI interactions a vehicle to become great—by integrating real-time feedback on responses and interactions.
- ROI analysis: Lastly to provide real value to the business, there has to be a return on the investment made in multimodal AI. Whether you are in retail, healthcare, logistics, or manufacturing, understanding the business value—and providing metrics on what the business gains by implementing multimodal AI—is fundamental for adoption and growth. AI isn’t right for every problem. Understanding where AI provides value to the business creates space for projects that use AI to be fine-tuned to the use cases that matter.
Pair multimodal AI with DataStax
Using multimodal AI can fundamentally change the way businesses interact, respond, and engage with their consumers.
The potential for massive benefit is great, but executing a multimodal strategy is key.
At DataStax, we provide the foundation to simplify building multimodal generative AI applications. The Enterprise Data Platform incorporates the tools and integrations you need to deploy Enterprise RAG with multimodal models.
Starting with the right tools—built and designed to work together seamlessly— means you execute on your multimodal AI strategy efficiently and effectively. Astra DB provides the highest-performing NoSQL database that supports vectors, graph, documents, and column data all in one. Couple Astra DB with Astra Streaming, to process and integrate real-time event data seamlessly into AI solutions.
DataStax has the data platform that is built and designed to fulfill the promises of multimodal AI. And, if building AI applications is your goal, DataStax has a generative AI framework that simplifies development and accelerates applications into production with Langflow. From cloud-native, as-a-service, and legacy on-premise, to edge computing with Hyper-Converged Infrastructure, DataStax has your Enterprise AI Data Platform covered.





