Your company is sitting on a gold mine: over 80% of enterprise data today is unstructured (and often siloed). But you can use knowledge graphs to turn your data chaos into a competitive advantage.
Here’s how to build a robust, scalable knowledge graph that delivers context-rich application insights and powerful analytics using DataStax tools.
What is a knowledge graph?
A knowledge graph is a sophisticated data structure that represents information as interconnected nodes and edges. It’s a powerful way to query complex relationships, adding rich context to AI applications. When you build a knowledge graph pipeline to extract knowledge from texts or articles, you can
- define the purpose
- highlight its application in organizing and storing data
- support semantic search functions within natural language processing.
Unlike traditional databases, knowledge graphs capture relationships between entities, making them particularly valuable for enhancing RAG (retrieval-augmented generation) systems and reducing LLM hallucinations.
Why build a knowledge graph with DataStax?
DataStax's RAG stack provides a unique approach to knowledge graphs by eliminating the need for a dedicated graph database. Instead, it leverages Astra DB's vector capabilities to store both the graph structure and vector embeddings in a single system. This unified approach simplifies architecture while maintaining powerful query capabilities.
Key benefits
- Simplified architecture: By leveraging Astra DB's capabilities, organizations maintain a single system for both vector and graph operations. This simplifies complexity.
- Scalable performance: The distributed nature of Astra DB ensures consistent performance as your knowledge graph grows.
- Flexible implementation: Support for both entity-centric and content-centric approaches allows organizations to choose the most suitable model for their needs, improving transaction handling for both graph and vector data.
Unlike conventional RAG systems that rely solely on vector similarity, DataStax's knowledge graph implementation can traverse relationships between documents, making it particularly effective for complex technical documentation, customer support systems, and enterprise knowledge bases.
Best practices
When implementing a DataStax knowledge graph, remember to:
- Start with a clearly defined scope and use case
- Implement proper monitoring and maintenance procedures
- Regularly validate and update relationships
- Maintain consistent documentation of changes and optimizations
Let’s step through it.
Planning and preparation
Define the purpose
Before implementing a DataStax knowledge graph, determine whether you need an entity-centric or content-centric approach. Establish a knowledge domain so your collected data aligns with specific use cases.
Entity-centric knowledge graphs (like Knowledge Graph RAG) capture edge relationships between entities. A knowledge graph is extracted with an LLM from unstructured information, and its entities and their edge relationships are stored in a vector or graph store. This is difficult, time-consuming, and error-prone. A user has to guide the LLM on the kinds of nodes and relationships to be extracted with a schema. If the knowledge schema changes, the graph has to be processed again. The context advantages of entity-centric knowledge graphs are great, but the cost to build and maintain them is much higher than chunking and embedding content to a vector store.
Content-centric knowledge graphs (like Graph Store) compromise the ease and scalability of vector similarity search, and the context and relationships of entity-centric knowledge graphs. The content-centric approach starts with nodes that represent content (a specific document about Seattle), instead of concepts or entities (a node representing Seattle). A node may represent a table, an image, or a document section. Since the node represents the original content, the nodes are exactly what is stored using vector search.
Designing the knowledge graph
Choose a semantic data model
With DataStax, open an Astra DB account.
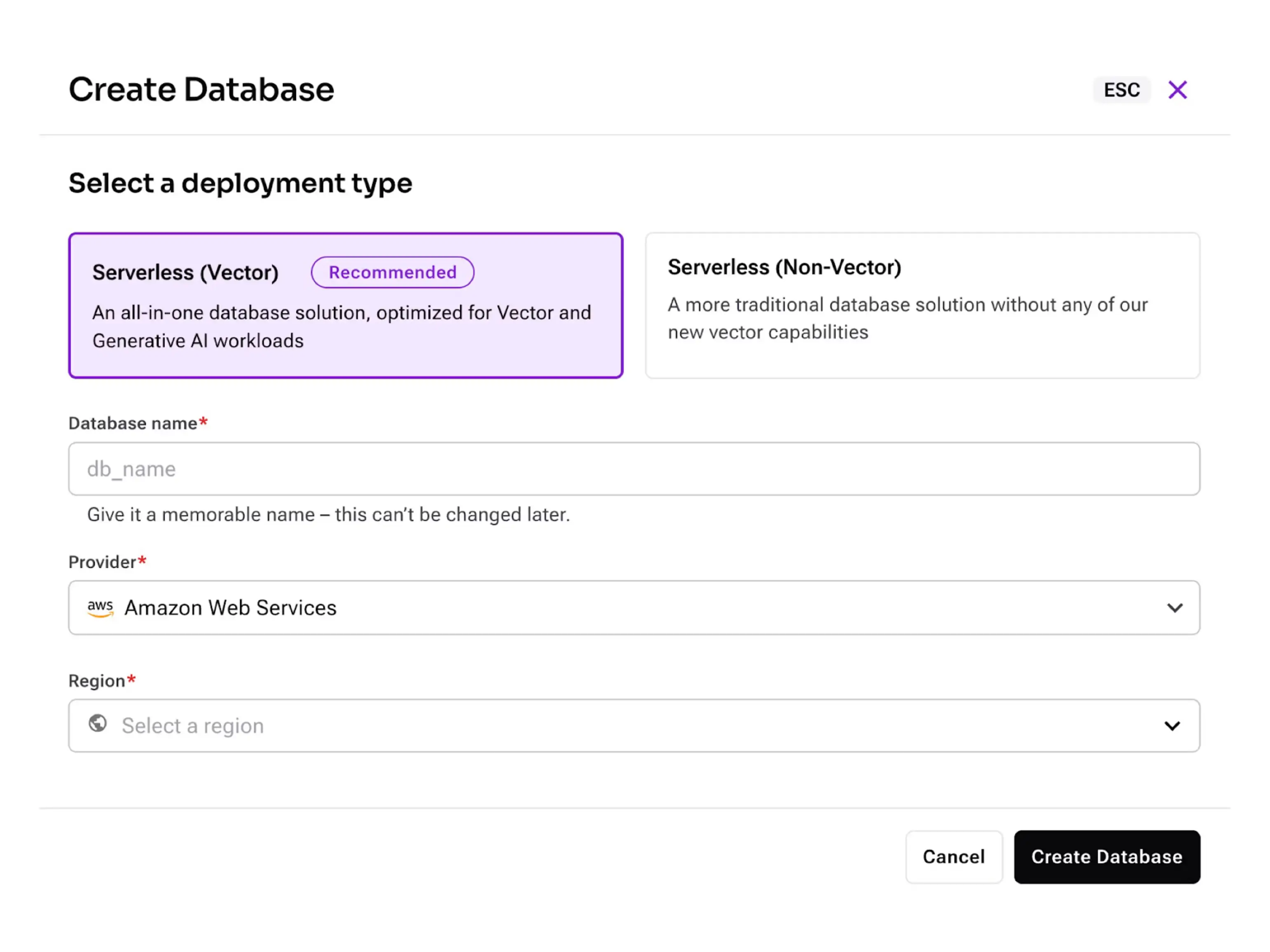
Then, fire up your favorite editor, and create an environment file:
# .env
OPENAI_API_KEY="<your key here>"
ASTRA_DB_DATABASE_ID="<your DB ID here>"
ASTRA_DB_APPLICATION_TOKEN="<your key here>"
ASTRA_DB_API_ENDPOINT="<your endpoint here>"The values for Astra DB are in the "Database Details" section:
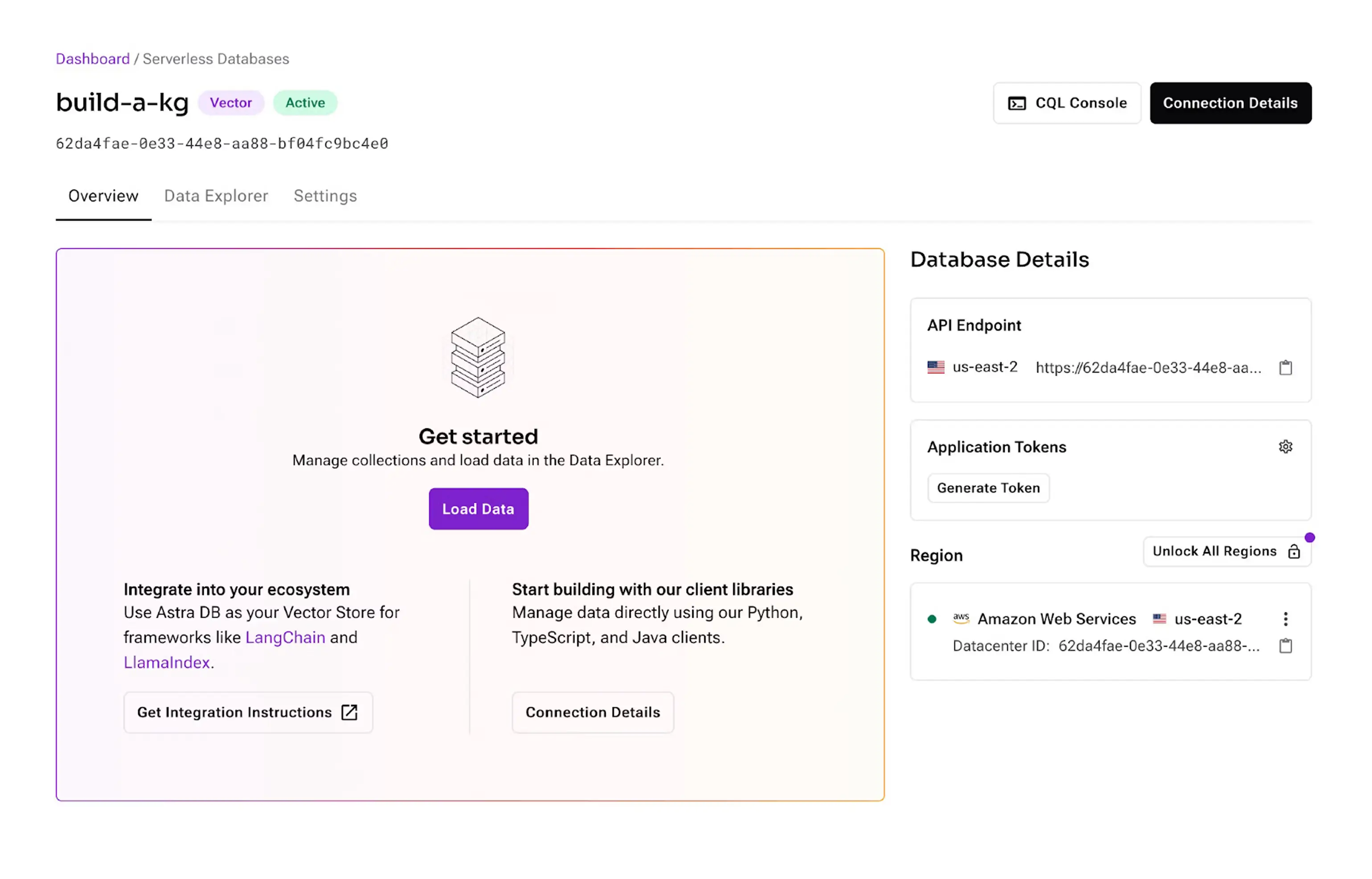
These keys authenticate the database connection, and your embedding model. We are using OpenAI for this tutorial, but use any embedding provider you like.
With that in place, let's install the remaining packages:
pip install -q \
ragstack-ai-langchain[knowledge-store]==1.3.0 \
beautifulsoup4 markdownify python-dotenvDataStax's implementation requires minimal setup with Astra DB or Apache Cassandra. Initialize your knowledge store:
SITE_PREFIX = "astra"
import cassio
from langchain_openai import OpenAIEmbeddings
from ragstack_langchain.graph_store import CassandraGraphStore
cassio.init(auto=True)
embeddings = OpenAIEmbeddings()
graph_store = CassandraGraphStore(
embeddings,
node_table=f"{SITE_PREFIX}_nodes",
)Configure the graph database storage system
With DataStax, you don’t need a separate graph database. The system uses Astra DB's vector capabilities combined with efficient graph traversal mechanisms.
Building and implementing the knowledge graph
Data ingestion and organization
DataStax’s RAG stack has built-in tools to extract knowledge, making it easy to analyze and quality control:
- LLMGraphTransformer for automated entity extraction
- Knowledge Schema system for structured information extraction
- Vector Graph for automated relationship mapping
For a detailed tutorial on ingestion, please see this guide.
Processing and storage
The system supports multiple retrieval modes:
- Vector-only retrieval: This method doesn't traverse edges and is equivalent to vector similarity.
vector_retriever = graph_store.as_retriever(search_kwargs={"depth": 0})
vector_rag_chain = (
{"context": vector_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)- Graph traversal retrieval: This method performs vector similarity search and then traverses 1 level of edges.
graph_retriever = graph_store.as_retriever(search_kwargs={"depth": 1})
graph_rag_chain = (
{"context": graph_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)Refining and expanding the knowledge graph
Optimization strategies
Implement and build DataStax’s knowledge graph easily with built-in optimization features that are essential post-launch to accommodate changes and integrate new solutions. The system automatically handles entity deduplication and maintains efficient traversal paths through the graph structure. Enhance performance further by configuring appropriate similarity thresholds and implementing proper indexing strategies within Astra DB.
Better insight
DataStax's retrieval mechanisms combine vector similarity with graph traversal. Natural language processing (NLP) enhances functionality by supporting semantic search systems and reducing hallucinations (inaccuracies) when interpreting data. This hybrid approach creates contextually relevant results compared to traditional vector-only searches. The system automatically discovers relationships between documents, making it particularly effective for complex enterprise knowledge bases.
Deploying an enterprise knowledge graph
Production deployment
When deploying to production, DataStax’s RAG stack seamlessly integrates with existing enterprise infrastructure. Machine learning advances knowledge graphs, particularly through developments in graph neural networks and representation learning, and has expanded their applications beyond traditional uses.
The system scales horizontally through Astra DB’s distributed architecture, ensuring consistent performance as your knowledge graph grows. Organizations can deploy multiple knowledge graphs for different departments while maintaining centralized management.
DataStax Graph incorporates all enterprise-class functionality in DataStax Enterprise, including advanced security protection; built-in DSE Analytics and DSE Search functionality; visual management and monitoring; and development tools, including DataStax Studio.
Building knowledge graphs with DataStax
DataStax RAG stack and Astra DB push knowledge graph technology forward, combining the power of vector search and graph-based knowledge representation. The platform's unique architecture simplifies the process while delivering enterprise-grade performance.
To learn more about knowledge graphs with DataStax, please see the following:








