

We have talked about new and advanced features available in repair a few times, but in this post I am going to cover an overview of repair, and how to think about what happens when using it.
Token Ranges
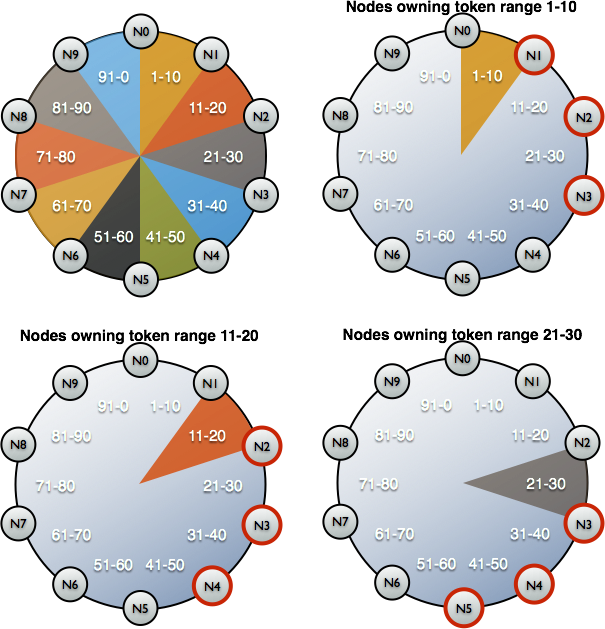
When thinking about repair in Apache Cassandra you need to think in terms of token ranges not tokens. Lets start with the simple case of having one data center with 10 nodes and 100 tokens. Where node N0 is assigned token 0, N1 is assigned token 10, and so on [1].
With a replication factor of 3, N3 will own data for tokens 1–30. And if we look at where that data will be replicated, you get range 1–10 shared by N1, N2, N3; 11–20 shared by N2, N3, N4; 21–30 shared by N3, N4, N5.
nodetool repair
When nodetool repair is run against a node it initiates a repair for some range of tokens. The range being repaired depends on what options are specified. The default options, just calling “nodetool repair”, initiate a repair of every token range owned by the node. The node you issued the call to becomes the coordinator for the repair operation, and it coordinates repairing those token ranges between all of the nodes that own them.
So for our example cluster, if you call “nodetool repair” on N3 the first thing that will hapen is to split the 1–30 range into the subranges based on groups of nodes which share that data. For each of those sub ranges, the 3 nodes will all compare the data in those ranges, and fix up any differences between themselves. So for sub range 1–10, N1 and N2 compare, N1 and N3 compare, N2 and N3 compare. After the repair finishes, those 3 nodes will be completely in sync for that token range. And a similar process happens for ranges 11–20 (N2, N3, N4) and 21–30 (N3, N4, N5). So just running “nodetool repair” on N3 there will be 5 nodes repairing data with each other, and at the end tokens 1–30 will be in sync across their respective owners. Now if we next run a “nodetool repair” on N4, we will repair the range 11–40 in a similar fashion.
nodetool repair -pr
But wait, we just repaired range 11–30, if we repair that again we will be wasting resources. This is where the “-pr” option comes in to help. When you use “nodetool repair -pr” each node picks a subset of its token range to schedule for repair, such that if “-pr” is run on EVERY node in the cluster, every token range will only be repaired once. What that means is, when ever you use -pr, you need to be repairing the entire ring (every node in every data center). If you use “-pr” on just one node, or just the nodes in one data center, you will only repair a subset of the data on those nodes. This is very important, so I’m going to say it again, if you are using “nodetool repair -pr” you must run it on EVERY node in EVERY data center, no skipping allowed.
Back to the example ring. Since we don’t want to repair a given piece of data multiple times, we are going to use the “-pr” option. When you issue “nodetool repair -pr” against node N3 only the range 21–30 will be repair. Similarly “nodetool repair -pr” on N4 will repair 31–40. As you can see we no longer have any overlapping data being repaired, but this also means, if you only ran “nodetool repair -pr” on N3, tokens 1–20 would not have been repaired. This is very important to know if you are running repair to fix a problem, and not as part of general maintenance. When running repair to fix a problem, like a node being down for longer than the hint windows, you need to repair the entire token range of that node. So you can’t just run “nodetool repair -pr” on it. You need to initiate a full “nodetool repair” on it, or do a full cluster repair with “nodetool repair -pr”.
Multiple Data Centers
If you have multiple data centers, by default when running repair all nodes in all data centers will sync with each other on the range being repaired. So for an RF of {DC1:3, DC2:3} for a given token range there will be 6 nodes all comparing data with each other and streaming any differences back and forth. If you have 4 data centers {DC1:3, DC2:3, DC3:3, DC4:3} you will have 12 nodes all comparing with each other and streaming data to each other at the same time for each token range [2]. This makes using “-pr” even more important, as if you don’t use it you repair a given token range 3+3+3+3+=12 times for the 4 DC case if you ran without using “-pr” on every node in the cluster.
nodetool repair -inc
A new feature available in Cassandra 2.1 is incremental repair. You can see the linked blog post for an in depth description of it, but in brief, incremental repair only performs the synchronization steps described above on data that has not been repaired previously. This helps to greatly reduce the amount of time it takes to repair new data.
-
These examples will be showing what happens with just one token per node, but the concepts are true for setups using virtual nodes (multiple tokens per node) as well, in that case each node just has more token ranges.
-
Cassandra 1.2 introduced a new option to repair to help manage the problems caused by the nodes all repairing with each other at the same time, it is call a snapshot repair, or sequential repair. As of Cassandra 2.1, sequential repair is the default, and the old parallel repair an option. Sequential repair has all of the nodes involved take a snapshot, the snapshot lives until the repair finishes, and then is removed. By taking a snapshot, repair can procede in a serial fashion, such that only two nodes are ever comparing with each other at a time. This makes the overall repair process slower, but decreases the burden placed on the nodes, and means you have less impact on reads/writes to the system.
More Technology
View All
How to Create a Local LangChain Vector Database

Apache Cassandra 2024 Wrapped: A Year of Innovation and Growth

How We Built UnReel: An AI-Generated, Multiplayer Movie Quiz
