




Welcome to the final post in a six-part series on Apache Cassandra®. In our previous post, we discussed three key migration approaches to bring your existing SQL applications over to NoSQL. Now, we’ll look at implementing these data models with a Spring PetClinic app.
Let’s recap what we’ve covered so far:
Part 1: Introduction to Apache Cassandra
Part 2: Advanced Data Modeling on Apache Cassandra
Part 3: Benchmark Your Database with NoSQLBench
Part 4: Supercharge your Data Model with Storage-Attached Indexes
Part 5: Three Approaches to Migrate SQL Applications to NoSQL
As a quick reminder, the three approaches we looked at in Part 5 are the following:
1) Offline migration
2) Zero-downtime migration with shadow writes
3) Minimal-downtime migration with dual reads
One thing all three approaches have in common is that you always need to migrate your data models. In this post, we walk you through how you can do this in a series of examples based on a Spring PetClinic application. At the end, you’ll get a chance to try it yourself by following this YouTube tutorial and using the free resources on our DataStaxDevs GitHub.
Spring PetClinic is an open-source sample application to show how you can use the Spring framework technical stack to build simple and powerful stateful applications. Originally made for relational databases, that application is now usable on distributed systems like Cassandra, thanks to DataStax’s Director of Developer Relations, Cédrick Lunven.
But more than just importing or changing drivers from one database to another, migration is about completely transforming a SQL database to a NoSQL one.
In this hands-on workshop, you’ll spin up a fully-realized Cassandra database through DataStax Astra DB, a multi-cloud database-as-a-service built on Cassandra. You can build and deploy cloud-native NoSQL applications in a matter of minutes on Astra DB, without having to worry about tuning and configuring Cassandra.
Astra DB is free-of-charge up to 80GB storage and 20 million monthly operations; no credit card required. Astra DB is also completely serverless, allowing you to run Cassandra clusters only when needed and lowering your costs significantly.
Data structure on SQL vs. NoSQL
If you come from the relational SQL world, you’re familiar with database normalization — the process of structuring a relational database according to a series of “normal forms” to increase data integrity and reduce data redundancy.
Relational databases were created at a time when disk platters were huge for a couple of megabytes of data, making them expensive and slow. Reducing data redundancy was key in creating data models, as disks didn’t have enough space to store repetitive data and adding space was expensive. Figure 1 illustrates a typical data model on SQL.
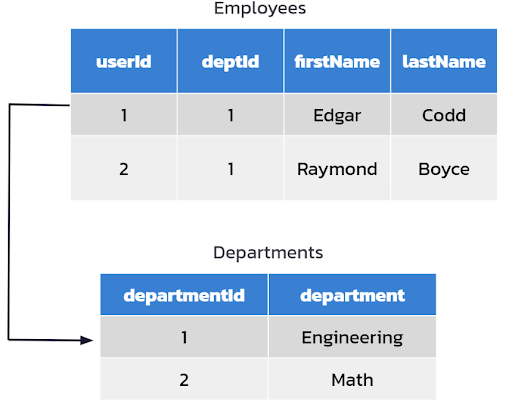
Figure 1. Data modeling on SQL.
For example, if you have a set of employees and you want to find out what department an individual employee is in, you have a single row for each department without any repeats. There’s only a single instance for the Engineering department, or the Math department, and you can easily find the department Edgar is in.
Now let’s move on to denormalization: the relational approach is flipped on NoSQL databases like Cassandra. While the main purpose of a relational database is to reduce data redundancy, NoSQL databases focus on optimizing read performance through denormalization, a strategy to improve the read performance of databases by adding redundant copies of data.
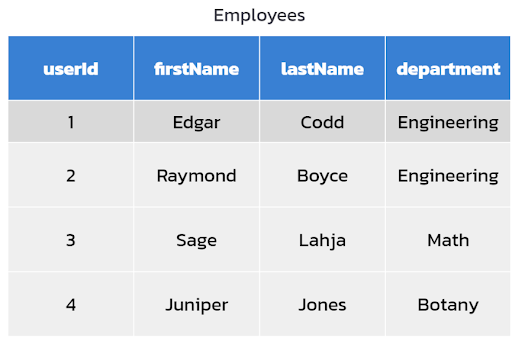
Figure 2. Data modeling on NoSQL.
Following the previous example, on NoSQL databases, data is stored into a single structure. In Figure 2, the department data is now added into the data structure of the employees table, creating repetitive data (Edgar Codd and Raymond Boyce are both in Engineering).
A big advantage of denormalization is speed at read. Many NoSQL databases, including Cassandra, are optimized to be fast and scalable for reads. But there are also some cons. During denormalization, writes multiply and you have to manually make sure that the data is reliable and accurate over its entire lifecycle.
Data modeling on SQL vs NoSQL
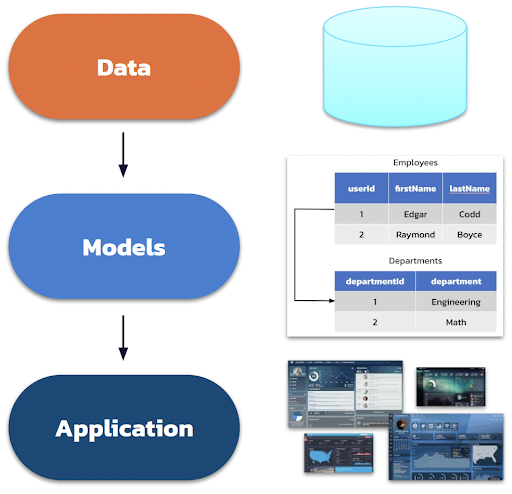
Figure 3. Relational data modeling process.
Data modeling on relational databases follows this process:
- Analyze raw data
- Identify entities, their properties, and relations
- Design tables using normalization and foreign keys
- Use JOIN when doing queries to join normalized data from multiple tables
While relational databases start the data modeling process from the application standpoint, Cassandra focuses on application workflows first.
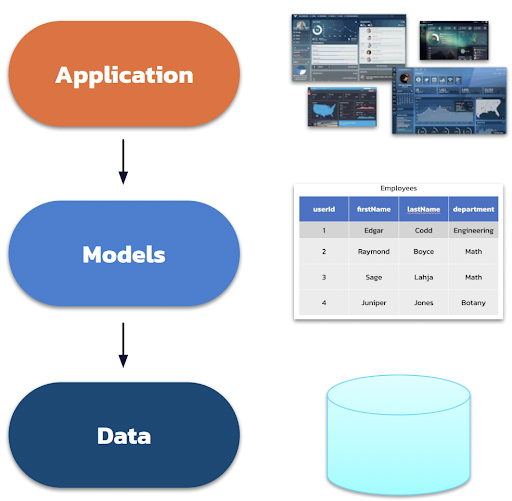
Figure 4. NoSQL data modeling process.
- Analyze user behavior
- Identify workflows and their dependencies and needs
- Define queries to fulfill these workflows
- Knowing the queries and design tables using denormalization
- Insert and update multiple copies of data that may have resulted due to denormalization
How to create a NoSQL data model
When migrating your SQL data model to NoSQL, you’ll need to follow the data modeling workflow in Figure 5 shown below.
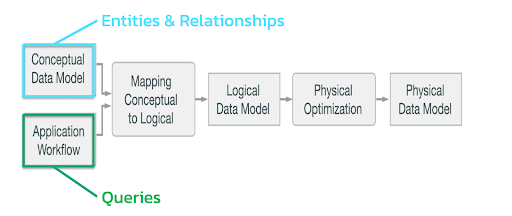
Figure 5. Data modeling workflow on NoSQL.
- Conceptual data model. For the purpose of this post, let’s look at a video application similar to YouTube, where users and videos are connected through comments on videos and sections.

Figure 6. Conceptual diagram of the video application.
- Application workflow. Next, think about how a user might flow through the application in different use-cases. For example, they might want to find all the comments that are related to a target user with a user ID, or a video using video ID.
- Mapping conceptual to logical. Once you have the workflows, move on to creating pseudo queries. In a tabular NoSQL database like Cassandra, you can now generate your queries without already having a data model in place because it’s queried per table design and not through JOIN clauses like on relational databases.
- Logical data model. Take the queries and generate a logical data model where you start to build relationships on NoSQL. For the video application example, you get the data model shown in Figure 7.
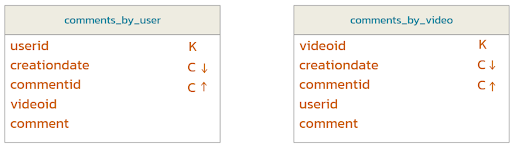
Figure 7. NoSQL logical data model.
In these tables, K stands for partition keys and C for clustering columns. Partition keys are how you partition data in a table, and clustering columns are how you order data within a partition. Primary keys are a combination of the two or just the partition key, and they uniquely identify a row.
- Physical optimization. Before you turn this into a physical data model, you need to optimize it by adding Universally Unique Identifiers (UUID). In NoSQL, we generally use UUIDs instead of INTs for keys. INTs are generally fine on their own, but they’re not a good case for keys. UUIDs guarantee that there won’t be collisions between multiple nodes if they’re trying to add a user and generate an ID at the same time, which is something that commonly occurs in a distributed database.
- Physical data model. Finally, you can generate Data Definition Language (DDL) statements with UUIDs and primary keys. If you’re coming from the SQL world, this should look really familiar because the syntax of Cassandra Query Language (CQL) is very similar to that of SQL.
For more details about Cassandra data modeling and to see data modeling examples from various domains, see our Data Modeling in Cassandra and DataStax Astra DB post.
Migrating your SQL data model to Cassandra
Now, let’s migrate the data model from SQL to Cassandra with an example PetClinic Java Database Connectivity (JDBC) that’s running a MySQL database locally. Watch the YouTube tutorial to follow along in real time, and you can even see a live demo by SpringPetClinic on GitHub.
You’ll first need to add a set of information (e.g. name, address, phone number) for owners and their pets to your Spring PetClinic application. Next, think about the application workflow. For this workshop, we came up with three.
Use-case 1
Here’s the first scenario.
Use-case 1: A user opens the owner “ALL” page.
Query 1: List all owners.
Figure 8 illustrates the owner schema from the SQL implementation with a set of owner properties and an ID that uniquely represents that owner. This is translated over to our Cassandra table on the right. It’s pretty straightforward since there’s only one read.
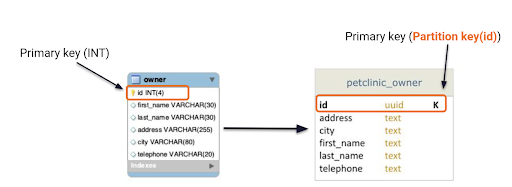
Figure 8. SQL to NoSQL for use-case 1.
Use-case 2
Next, we have the following:
Use-case 2: A user opens the owner-detail page.
Query 2: Find owner and any pets related to target owner using its identifier (owner_id).
Let’s say you want to see both owner and pet information. In SQL, you have two tables because there’s a one-to-many relationship. An owner can have multiple pets, but a pet can only have one owner. In Cassandra, you can combine the two into one table and add a clustering column with the pet ID. For each owner, you can now have multiple rows to store data in a single read, called a multi-row partition.
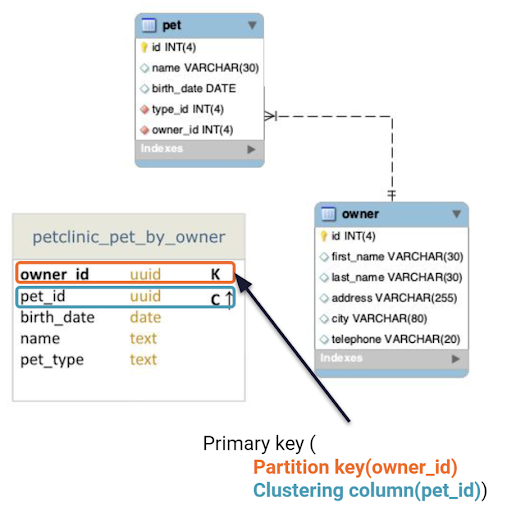
Figure 9. SQL to NoSQL for use-case 2.
Watch this SQL to NoSQL explainer video for an alternative approach to flatten out the data even more by making the owner fields static. This approach is particularly useful for larger applications with high volumes of data.
Use-case 3
Lastly, we have our third scenario:
Use-case 3: A user opens up the owner detail page.
Query 3: Find pets and any visits related to target pet using its identifier (pet_id).
There’s a nested relationship among pets, owners, and visits. Again, you can turn this into a multi-row partition by using a clustering column for visit ID, meaning that you can see any number of visits per pet in a single read.
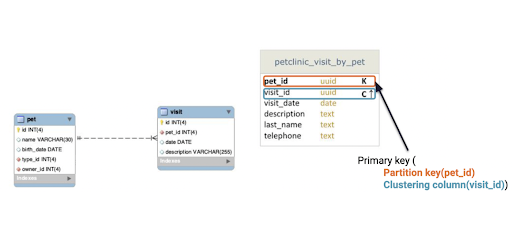
Figure 10. SQL to NoSQL for use-case 3.
Alternatively, you can denormalize all the separate tables into one table or store all four of the SQL tables as a JSON document on a document database, such as Cassandra, Astra DB, and Stargate. Follow this SQL to NoSQL video tutorial for a full explanation.
Final model comparison
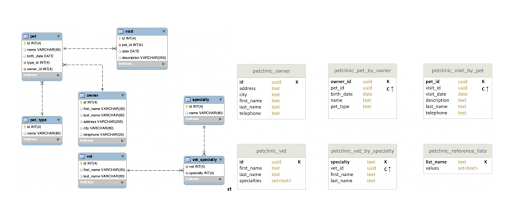
Figure 11. Many-to-many relationships on SQL (left) vs. Cassandra collection (right).
Figure 11 represents the original diagram from SQL and the flattened, denormalized version of it on Cassandra. Cassandra handles the many-to-many relationship between specialties and vets on SQL by using a collection type, which is a way to group and store data together in a table column. For a particular vet, you can now store and retrieve a set of specialties in a single read and vice versa.
Hands-on workshop
Now it’s your turn to execute the whole process from scratch with instructions in this video tutorial and resources on GitHub. Here’s what you’ll do:
- Create a fully-realized Cassandra database on Astra DB for free!
- Create PetClinic NoSQL data model
- Securely connect to your Cassandra database on Astra DB by generating Astra application token
- Transform and load data with DataStax Bulk (DSBulk), a unified tool for loading into and unloading from Cassandra-compatible storage engines
Conclusion
Congratulations! You’ve gone through a high-level and detailed process of migrating your SQL database applications to NoSQL, specifically Cassandra databases.
To keep learning, try out these other Cassandra tutorials on GitHub on moving from relational to distributed databases, and read our post on migration best practices for Apache Cassandra. If you like working with Spring PetClinic applications, check out our tutorial on building a reactive implementation of Spring PetClinic in Cassandra.
We also frequently hold free on-demand webinars and release weekly workshops on our YouTube channel for developers. You can also find a comprehensive collection of Cassandra courses on DataStax Academy, from creating multi-row partition tables to using secondary indexes.
If you have more technical or in-depth questions on Cassandra, feel free to ask the experts on the DataStax Community or chat with us on our Discord channel.
Resources
- Astra DB: Multi-cloud DBaaS built on Apache Cassandra®
- YouTube Tutorial: From SQL to NoSQL
- GitHub: SQL to NoSQL Migration Workshop
- DataStax Academy
- DataStax Community
- DataStax On-demand Webinars
- DataStax Bulk Loader for Apache Cassandra
- The Cassandra Fundamentals Coursework
- Building a Reactive Implementation of Spring PetClinic in Apache Cassandra®
- Moving from RDBMS to NoSQL: Migration Best Practices for Apache Cassandra®
- Data Modeling in Cassandra and DataStax Astra DB









