

Managing the trade-off between consistency and availability is nothing new in distributed databases. It’s such a well-known issue that there is a theorem to describe it.
While modern databases don’t tend to fall neatly into categories, the “CAP” theorem (also known as Brewer’s theorem) is still a useful place to start. The CAP theorem states that a database can’t simultaneously guarantee consistency, availability, and partition tolerance. Partition tolerance refers to the idea that a database can continue to run even if network connections between groups of nodes are down or congested.
Since network failures are a fact of life, we pretty much need partition tolerance, so, from a practical standpoint, distributed databases tend to be either “CP” (meaning they prioritize consistency over availability) or “AP” (meaning they prioritize availability over consistency).
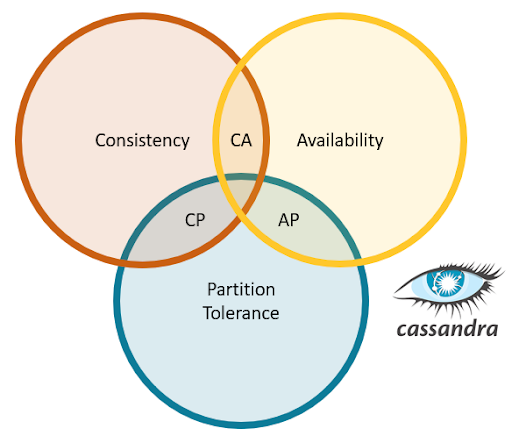
Apache Cassandra® is usually described as an “AP” system, meaning it errs on the side of ensuring data availability even if this means sacrificing consistency. This is a bit of an over-simplification because Cassandra seeks to satisfy all three requirements simultaneously and can be configured to behave much like a “CP” database.
Replicas ensure data availability
When Cassandra writes data it typically writes multiple copies (usually three) to different cluster nodes. This ensures that data isn’t lost if a node goes down or becomes unavailable. A replication factor specified when a database is created controls how many copies of data are written.
When data is written, it takes time for updates to propagate across networks to remote hosts. Sometimes hosts will be temporarily down or unreachable. Cassandra is described as “eventually consistent” because it doesn’t guarantee that all replicas will always have the same data. This means there is no guarantee that the data you read is up to date. For example, if a data value is updated, and another user queries a replica to read the same data a few milliseconds later, the reader may end up with an older version of the data.
Tunable consistency in Cassandra
To address this problem, Cassandra maintains tunable consistency. When performing a read or write operation a database client can specify a consistency level. The consistency level refers to the number of replicas that need to respond for a read or write operation to be considered complete.
For reading non-critical data (the number of “likes” on a social media post, for example), it’s probably not essential to have the very latest data. You can set the consistency level to ONE and Cassandra will simply retrieve a value from the closest replica. If I’m concerned about accuracy, however, I can specify a higher consistency level, like TWO, THREE, or QUORUM. If a QUORUM (essentially a majority) of replicas reply, and if the data was written with similarly strong consistency, users can be confident that they have the latest data. If there are inconsistencies between replicas when data is read, Cassandra will internally manage a process to ensure that replicas are synchronized and contain the most recent data.
The same process applies to write operations. Specifying a higher consistency level forces multiple replicas to be written before a write operation can complete. For example, if “ALL” or “THREE” are specified when updating a table with three replicas, data will need to be updated to all replicas before a write can complete.
There is a trade-off between consistency and availability here, as well. If one of the replicas is down or unreachable, the write operation will fail since Cassandra cannot meet the required consistency level. In this case, Cassandra sacrifices availability to guarantee consistency.
Trade-offs between performance and consistency
So far we haven’t talked about performance, but there is also a strong relationship between consistency and performance. While using a high consistency level helps ensure data accuracy, it significantly impacts latency. For example, in the case of a read operation, rather than retrieving data that is possibly cached on the closest replica, Cassandra needs to check with multiple replicas, some of which may be in remote data centers.
Additional consistency levels address other considerations impacting performance and consistency, such as whether a quorum reached in a single data center is sufficient or a quorum needs to be reached across multiple data centers.
Cassandra can be tailored to application requirements
The good news for developers and database administrators is that these behaviors are highly configurable. Consistency can be set individually for each read and write operation, allowing developers to precisely control how they wish to manage trade-offs between consistency, availability, and performance.









