

The first two minor releases after Cassandra 2.0.0 contained many bug fixes, but also some new features and enhancements. For the benefit of those who don't read the CHANGES religiously, let's take a look at some of the highlights.
Rapid read protection is enabled by default
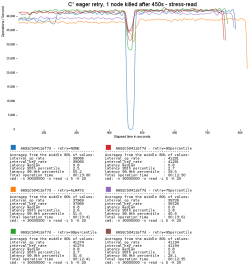
I wrote a separate article about how rapid read protection in 2.0.2 improves availability and latency. I'll just reproduce one graph to pique your curiosity:
Improved blob support
Cassandra technically allows column values to be up to 2GB, but it's tuned to deal with much smaller columns by default. CASSANDRA-5982 adds a number of improvements to 2.0.1 to deal with larger columns. Most are improvements that require no operator intervention; the exception is the commitlog_periodic_queue_size setting, which should be reduced for a blob-heavy workload. (Our tests show that 16*cpucores is a reasonable setting for 1MB blobs, for instance.)
If you need to store blobs larger than 10MB, I recommend splitting them across multiple rows or using a library like Astyanax that supports this transparently.
Limited support for DISTINCT
Cassandra still does not support SELECT DISTINCT in general, but as a special case we now allow it on partition keys, since that can be done with minimal work by the storage engine. E.g., for the playlist example, I could write SELECT DISTINCT id FROM playlists.
Cleanup performance
Recall that cleanup refers to purging data that no longer belongs locally after adding new nodes to the cluster. Until now, this has been a fairly slow operation that does a simple sequential scan over all the local data to locate partitions that have been evicted.
Starting in 2.0.1, we leverage the metadata we have for each data file (including first and last partition) to optimize away checking files that only contain data that is still local. Files that only contain non-local data can be dropped without inspection as well, which only leaves files containing a mix. For those we can use the partition index to only scan the data range that is still local (and rewrite it to a new file).
Now that cleanup is relatively lightweight, In 2.1 we will go further and cleanup automatically after bootstrapping new nodes into the cluster.
Repair instrumentation
Repair builds its merkle tree with a fixed size of 32,768 leaf nodes (thus, 65535 total nodes). If the repair covers more partitions than that, multiple partitions will be hashed into a single leaf node, and the repair will be correspondingly less precise: if we repair 1,000,000 partitions, the smallest unit of repair will be about 30 partitions.
Subrange repair (repairing less than an entire vnode's worth of data at once) allows you to restrict the repair range to retain a desired level of precision; the problem is that Cassandra didn't log enough information about repair operations to tell how much precision you were losing and hence whether subrange repair is worth the trouble.
Starting in 2.0.1, Cassandra logs statistics like this:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
<tt>
Validated 331 partitions for 64106960-4362-11e3-976a-71a93e2d33ad.
Partitions per leaf are:
[0..0]: 32437
[1..1]: 331
</tt>This says there are 32437 leaf nodes with no rows hashed, and 331 with one row each. Our precision (for this very small repair) is fine.
Note that these are logged at DEBUG; enable debug logging on org.apache.cassandra.repair.Validator to see them.
ConsistencyLevel.LOCAL_ONE
Similar to LOCAL_QUORUM, LOCAL_ONE is a consistency level that restricts an operation to the datacenter of the coordinator handling the request.
New in 2.0.2, LOCAL_ONE is now the default for Hadoop reads and is otherwise useful when failing a request is better than going over the WAN to fulfil it.
Compaction history
Compaction logs information about merged data files like this:
Compacted 6 sstables to [
/var/lib/cassandra/data/kstest/demo1/kstest-demo1-jb-1854,
...
/var/lib/cassandra/data/kstest/demo1/kstest-demo1-jb-1867,
].
986,518,120 bytes to 986,518,120 (~100% of original) in 142,917ms = 6.582961MB/s.
3,523,279 total partitions merged to 3,523,279. Partition merge counts were {1:3523279, }
Here, I have a table configured to use leveled compaction, but every partition was unique -- no merging took place. This suggests that size-tiered compaction is a better fit for this table.
What's new in 2.0.2 is not this logging but that we save the results to system.compaction_history:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
<tt>
CREATE TABLE compaction_history (
id uuid PRIMARY KEY,
keyspace_name text,
columnfamily_name text,
compacted_at timestamp,
bytes_in bigint,
bytes_out bigint,
rows_merged map,
)
</tt>This information is available to tools like OpsCenter to help tune compaction.
Improved memory use defaults
2.0.2 changes the default memtable_total_space_in_mb to 1/4 of the heap (from 1/3) and write_request_timeout_in_ms to 2 seconds (from 10).
The primary motivation behind these changes (especially the second) is to make it more difficult to OOM Cassandra with a sudden spike in write activity. Cassandra's load shedding discards requests older than the timeout, but ten seconds worth of writes on a large cluster with many coordinators feeding requests can easily consume many GB of memory. Cutting that back by a factor of five will help a lot while still allowing most requests delayed by network hiccups or GC pauses to complete. (The old 10s value was grandfathered in from before we had separate timeouts for reads, writes, and internal management.)
If you want to be even more aggressive, you could cut the write timeout to 500ms and enable {{cross_node_timeout}}, which starts load shedding based on when the coordinator starts the request rather than when the replica receives it.
Workload-aware compaction
We laid the groundwork for this in 2.0.2 but the payoff isn't until 2.0.3 (coming later in November): Cassandra will track which data files are most frequently read and prioritize compacting those. Optionally, it can omit compacting "cold" files entirely, which dramatically improves performance for workloads with billions of archived or seldom-requested rows.
CQL-aware SSTableWriter
SSTableWriter is the API to create raw Cassandra data files locally for bulk load into your cluster. For 2.0.3, we've added the CQLSSTableWriter implementation that allows inserting rows without needing to understand the details of how those map to the underlying storage engine. Usage looks like this:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
<tt>
String schema = "CREATE TABLE myKs.myTable ("
+ " k int PRIMARY KEY,"
+ " v1 text,"
+ " v2 int"
+ ")";
String insert = "INSERT INTO myKs.myTable (k, v1, v2) VALUES (?, ?, ?)";
CQLSSTableWriter writer = CQLSSTableWriter.builder()
.inDirectory("path/to/directory")
.forTable(schema)
.using(insert).build();
writer.addRow(0, "test1", 24);
writer.addRow(1, "test2", null);
writer.addRow(2, "test3", 42);
writer.close();
</tt>Special thanks
Among the many community members who contributed to these releases, we'd like to give a special shout out to Oleg Anastasyev, Chris Burroughs, Kyle Kingsbury, Sankalp Kohli, and Mikhail Stepura. Thanks for the help!












