
Wikidata represents a remarkable achievement in the world of open data, offering one of the largest and most reliable linked open datasets globally. As the central repository for structured data used across Wikimedia projects—such as Wikipedia, Wikivoyage, Wiktionary, Wiki Commons, and Wikisource—Wikidata’s influence reaches well beyond its Wikimedia roots.
Today, we’re excited to announce a major development in data management and analysis: Wikimedia Deutschland and DataStax are partnering to explore and implement advanced methods for scaling semantic data search. This collaboration is poised to expand the possibilities for working with large-scale, high-quality datasets.
In this post, we’ll dive into the specifics of this partnership, discussing its potential to enhance data processing, storage, and usage. Join us as we look at the future of big data management and its significance for the open knowledge movement.
Build equitable and validated generative AI
Wikimedia’s Wikidata Project is spearheading an initiative to develop an equitable and validated approach to generative AI by leveraging the robust capabilities of Wikidata's knowledge graph.
This initiative, as presented by Jonathan Fraine and Lydia Pintscher at AI Dev Paris, aims to create a vector search API service that integrates with Wikidata’s search API and UI, providing freely accessible, high-quality, crowdsourced, and citable data. The API service enables developers to build projects on top of Wikidata’s knowledge graph, fostering a collaborative environment for the open-source machine learning community. By offering this resource, Wikimedia Deutschland ensures that GenAI models can access validated data, supporting more accurate, fair, and responsible AI solutions for the wider community. You can view Jonathan and Lydia’s presentation slides here.
The project will proceed in phases to investigate various models and techniques aimed at improving the quality of the original dataset. The overall definitions can be seen in the image below.
- Part 1 - Ingestion: The objective is to ingest the “nodes” of the graph (these include QIDs, which are numbers used as identifiers, or Wikidata entities), chunk the entities, and generate embeddings for each node. Because the information is provided in multiple languages, various models need to be evaluated to identify the best solution (e.g., a single model versus multiple specialized models, or determining which models to use). This process will enable vector-based searches on Wikidata entities.
- Part 2 - Integration with Langflow: Langflow is a powerful graphical interface for building and experimenting with LangChain workflows, enabling streamlined integration of AI models, tools, and data pipelines. It simplifies complex process development with a user-friendly, node-based editor, making it accessible for both developers and non-technical users. With its extensive library of components it can connect to Astra Vector DB and the existing Wikidata REST API.
- Part 3 - Building a best-of-breed search: By combining various search strategies—such as text search, vector search, graph traversal, and metadata filtering—an iterative process will be implemented to assess result accuracy. This phase will involve applying different algorithms, such as reranking, compression, and aggregation, to optimize search performance and deliver the best possible results. To illustrate this capability we built a user interface with Next.js.
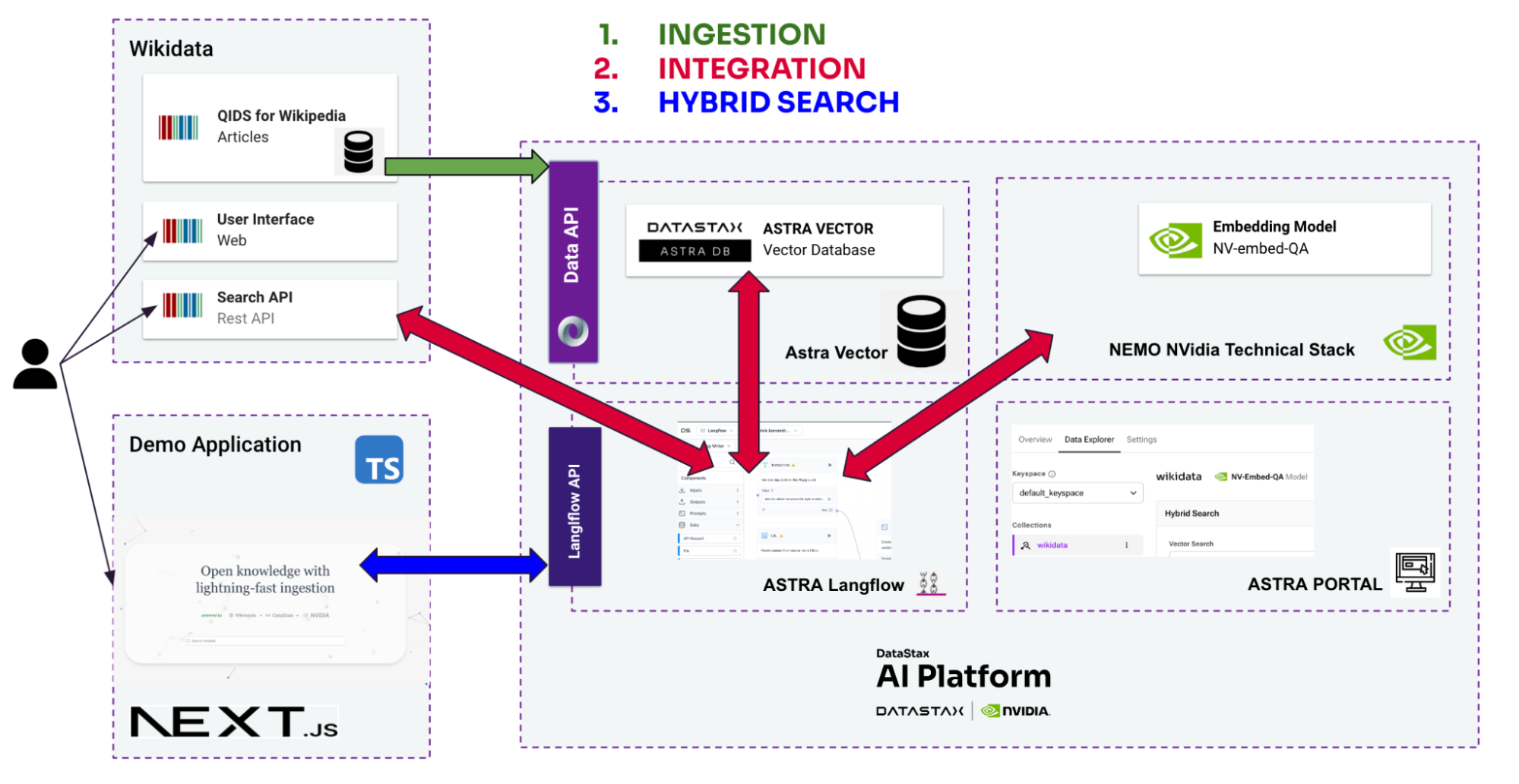
We’ll now detail the different approaches and implementations in each building block.
Part 1: Ingestion
About the dataset
The dataset is notably large; details that illustrate the scale are available on the dataset statistics and usage statistics pages.
In summary, it contains around 110 million items and over 1.3 million lexemes. Of these, 9.2 million out of 112 million entities (8%) are connected to the English Wikipedia, representing approximately 11,000 unique properties. Additionally, there are 3.1 million entities linked to the 9.2 million but not connected to English Wikipedia, bringing the total number of items to process to an impressive 12.3 million.
- It’s possible to retrieve the entities through HTTP links providing the QIDs (eg 8849513)
- The data is available for download here
Ingestion workflow
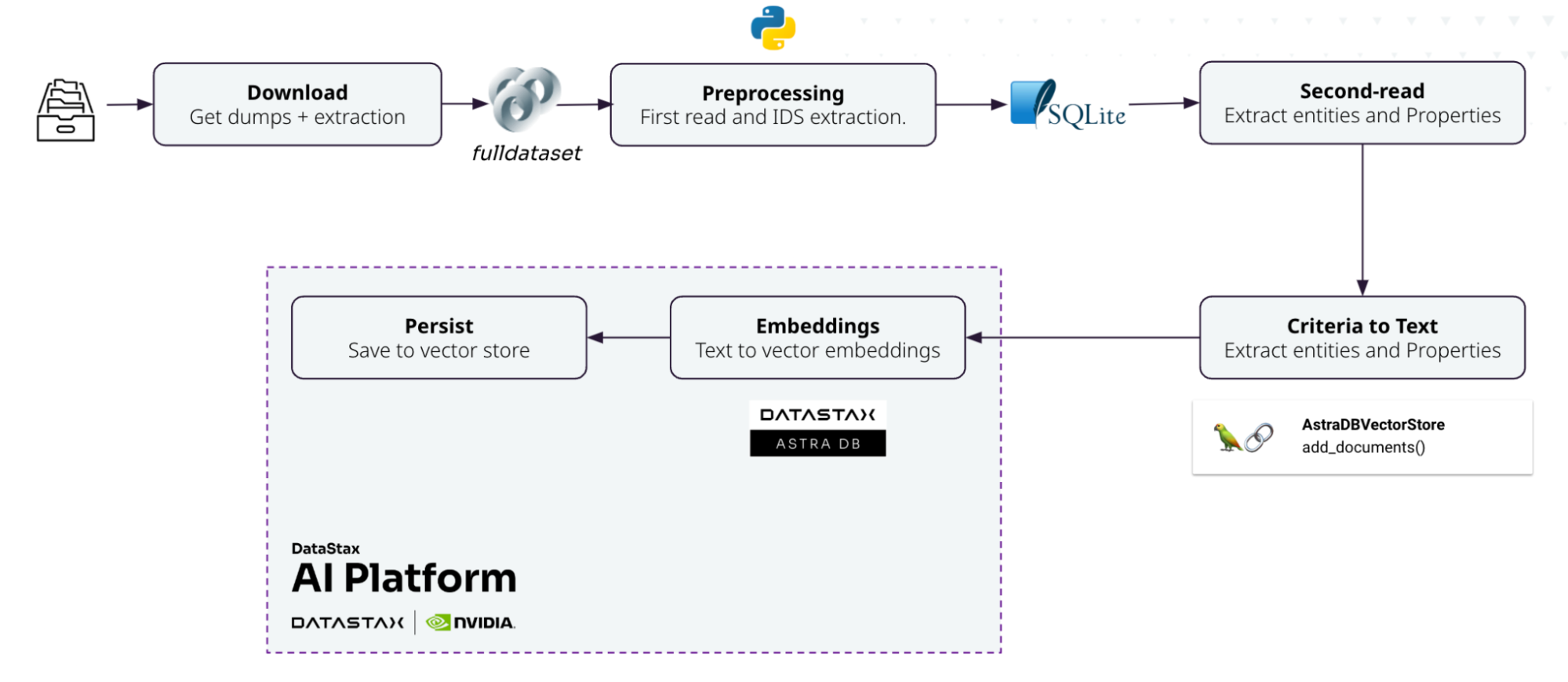
Preprocessing: After downloading and extracting the bulk data from the repository, an initial preprocessing step is performed to isolate the list of nodes and assets one wishes to process. Various free solutions and frameworks are available out of the box for parsing this specific dataset and shaping it for ingestion, such as the simple-wikidata-db tool.
Dataset formatting (second-read, criteria to text): Given the rich set of properties, some need to be filtered out, while others should be prioritized to compute the embeddings that represent the meaning of each entity. In the second pass, relevant properties are retrieved and concatenated to form the text that will serve as input for generating embeddings.
Embeddings: As the text can be quite long and may exceed the maximum token limit accepted by the embedding model, a chunking operation is necessary. The text is split, and each chunk is then inserted into the database with an identifier pattern of QID_{chunkindex}.
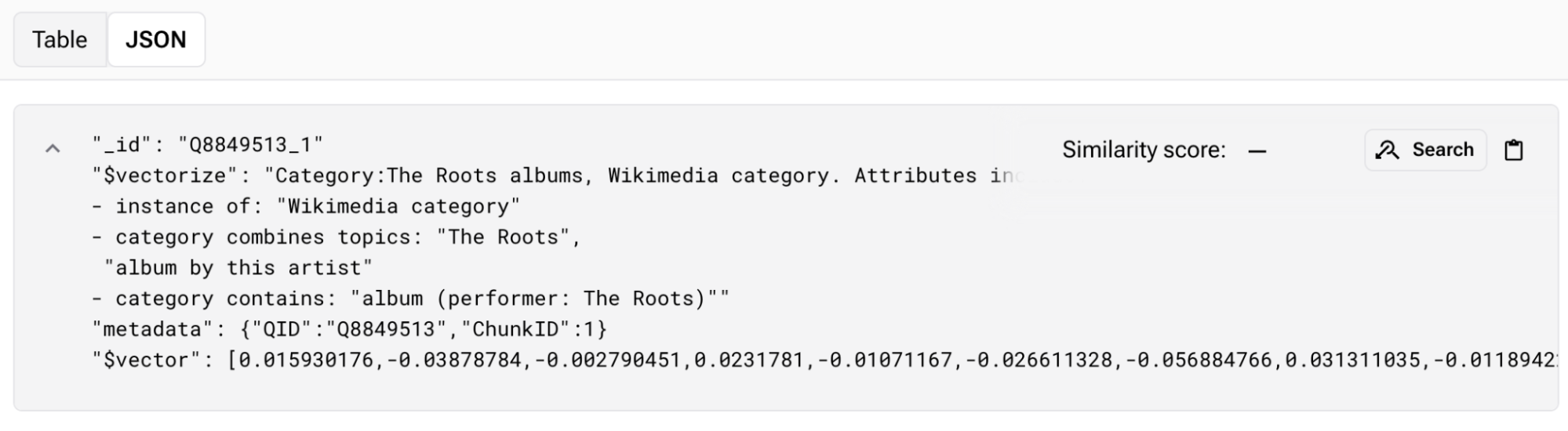
About Astra Vectorize
Computing embeddings can be time-consuming. Whether running a model locally or using a third-party API, latency can be significant. To speed up this process, Astra Vectorize offers an embedding computation function. When data is inserted into an Astra collection, you can configure it to compute embeddings at once, directly within the same environment. This improvement provides a substantial performance boost, reducing ingestion time from over 30 days to just two (most of the time is now spent on searching and extracting data from the dataset).
Part 2: Integration with Langflow
Langflow is integrated into Astra DB, providing an easy way to create pipelines and develop real-world applications. It enables you to build workflows by combining various technologies and offers flexibility in usage. You can use it as a chatbot through the built-in user interface or integrate it into your applications via the exposed REST API.
In the project, we used the following components:
- HTTP client - Packaged as a custom tool (AI agent) to interact with the existing Wikidata API for text-based searches.
- Native Astra DB connector - Integrated with NVIDIA-powered vectorization, as presented previously.
- Re-ranker - Provided by NVIDIA’s stack to enhance the overall quality of the data.
- LLM integration - A native integration (using OpenAI, in this case) to generate advanced responses based on the available knowledge.
The entire workflow is accessible via the REST API.
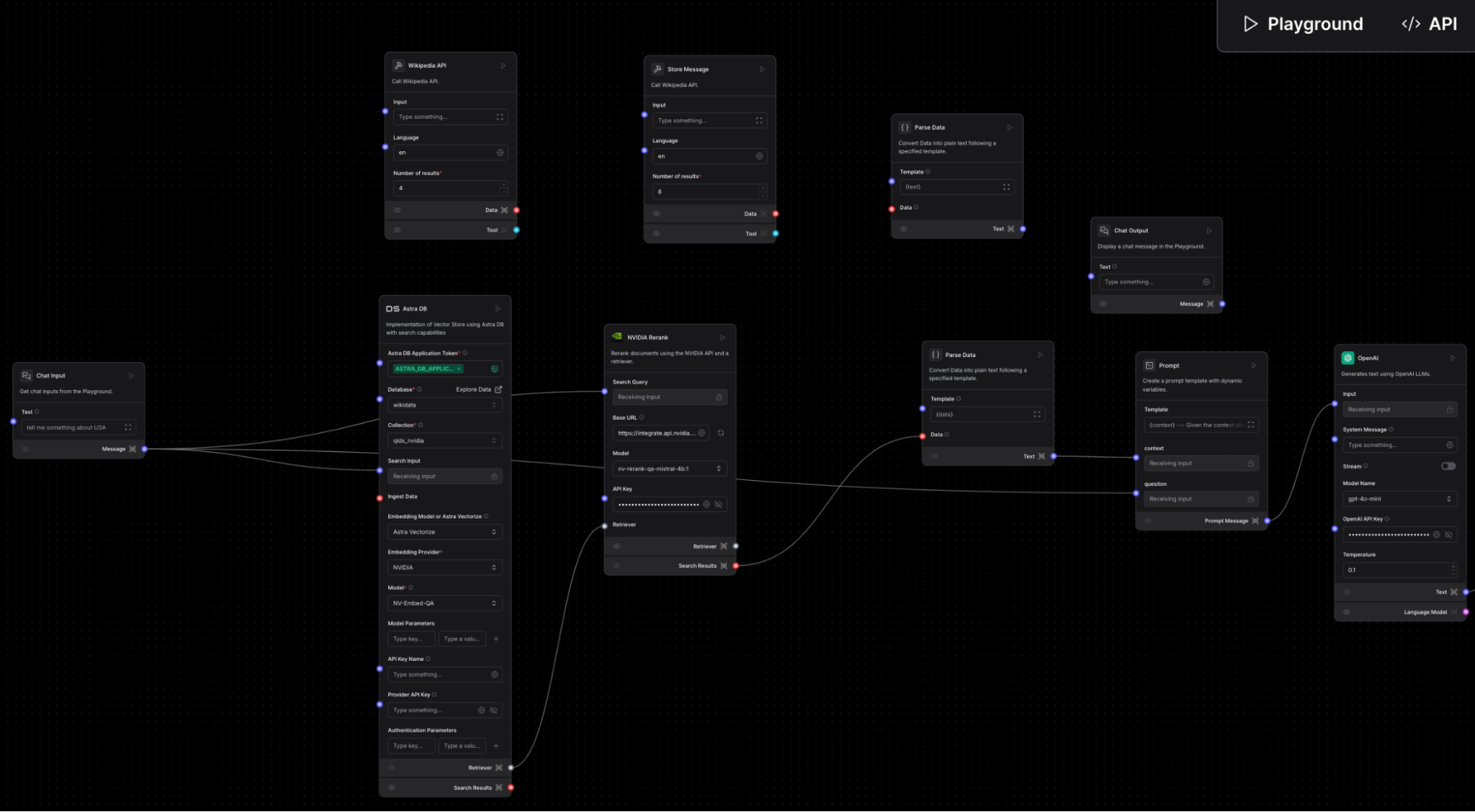
A visualization of the langflow implementation
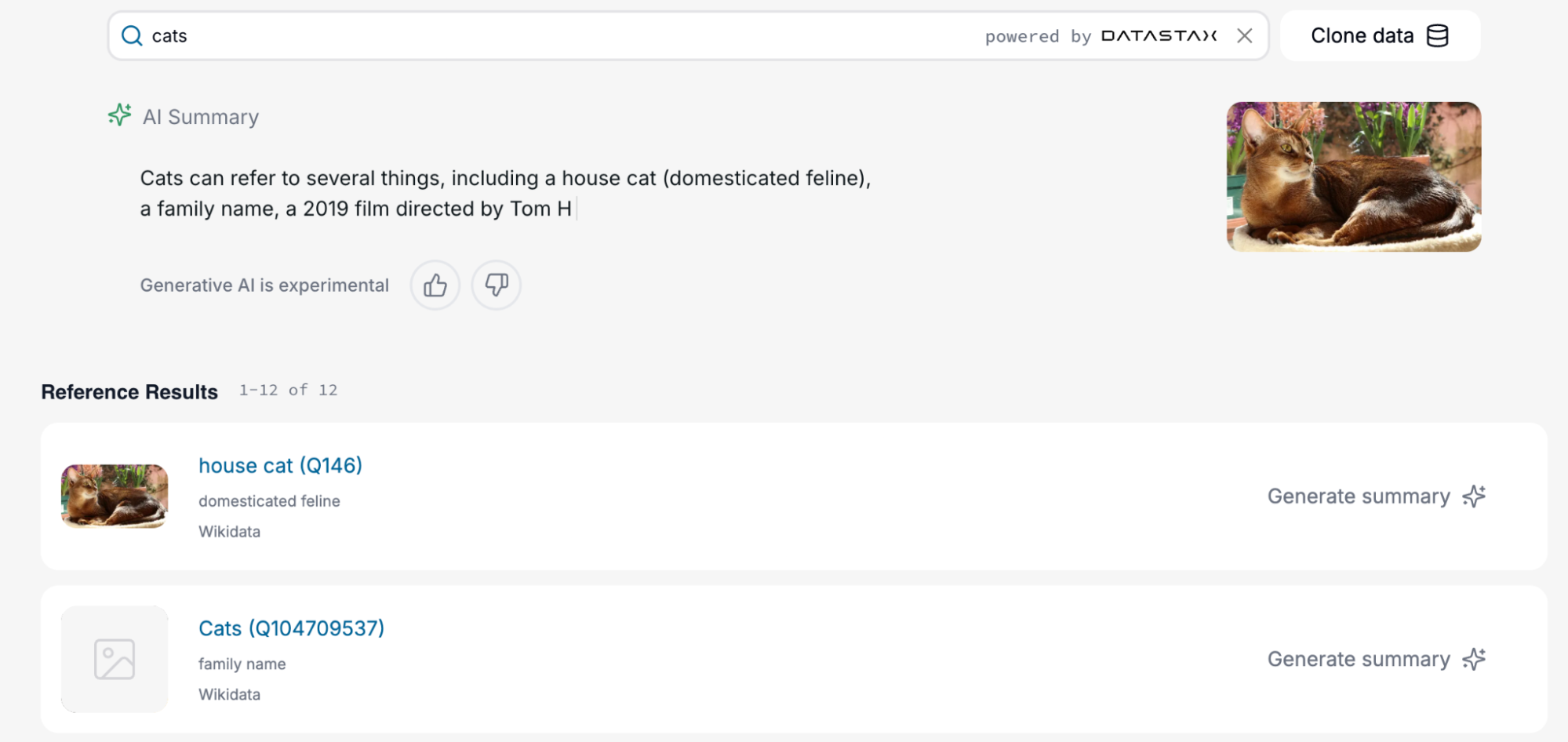
The results returned are both text and image format:
Conclusion
This RAG pipeline demonstrates how Astra DB and Langflow tools, in collaboration with NVIDIA, can be leveraged to build or enhance applications with advanced search capabilities. This marks just the beginning of this partnership.
Our future plans include ingesting data in multiple languages and testing various embedding models. Additionally, we aim to enhance search functionality by integrating a graph RAG component. The source data, currently a knowledge graph, will be adapted for use in the RAG framework.
If you’re in Las Vegas, we’ll be discussing this partnership today at a breakout session at AWS re:Invent. Join us!




