


Gremlin artwork by Ketrina Yim — "safety first."
One of the most popular and interesting topics in the world of NoSQL databases is graph. At DataStax, we have invested in graph computing through the acquisition of Aurelius, the company behind TitanDB, and are especially committed to ensuring the success of the Gremlin graph traversal language. Gremlin is part of the open source Apache TinkerPop graph framework project and is a graph traversal language used by many different graph databases.
I wanted to introduce you to a superb web site that our own Daniel Kuppitz maintains called “SQL2Gremlin” (http://sql2gremlin.com) which I think is great way to start learning how to query graph databases for those of us who come from the traditional relational database world. It is full of excellent sample SQL queries from the popular public domain RDBMS dataset Northwind and demonstrates how to produce the same results by using Gremlin. For me, learning by example has been a great way to get introduced to graph querying and I think that you’ll find it very useful as well.
I’m only going to walk through a couple of examples here as an intro to what you will find at the full site. But if you are new to graph databases and Gremlin, then I highly encourage you to visit the sql2gremlin site for the rest of the complete samples. There is also a nice example of an interactive visualization / filtering, search tool here that helps visualize the Northwind data set as it has been converted into a graph model.
I’ve worked with (and worked for) Microsoft SQL Server for a very long time. Since Daniel’s examples use T-SQL, we’ll stick with SQL Server for this blog post as an intro to Gremlin and we’ll use the Northwind samples for SQL Server 2014. You can download the entire Northwind sample database here. Load that database into your SQL Server if you wish to follow along.
In order to execute the graph queries using Gremlin as well, you can download the Gremlin console and run the queries via in-memory graphs as a way to become familiar with Gremlin and graph traversals. You can also download the Titan 1.0 graph database here, which also provides a Gremlin console that can persist the graph in Cassandra.
I’ll highlight 3 examples from the SQL2Gremlin site that I want to share with you as beginners:
Starting off with a simple example, here is a very common SQL query where you select multiple fields from a single table and filter based on 2 WHERE clause conditions:
SELECT ProductName, UnitsInStock
FROM Products
WHERE Discontinued = 1 AND UnitsInStock > 0
In SQL Server 2014 Management Studio, these were my results:
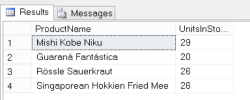
And then in the Gremlin shell, this is the query you would use and subsequent result set:
g.V().has("product", "discontinued", true).has("unitsInStock", neq(0)).valueMap("name", "unitsInStock")
==> [unitsInStock:[29], name:[Mishi Kobe Niku]]
==> [unitsInStock:[20], name:[Guaraná Fantástica]]
==> [unitsInStock:[26], name:[Rössle Sauerkraut]]
==> [unitsInStock:[26], name:[Singaporean Hokkien Fried Mee]]
I’m skipping the instantiation of the Graph and traversals objects. Follow along on Daniel’s site to set those in the Gremlin console. You’ll find that using g to represent the graph traversal a common standard and the basic Gremlin documentation will walk you through the methods available to you for vertex searches.
Next, since relationships are first-class citizens in a graph database, you can very easily traverse relationships without needing to build those relationships via query-time joins like you see here in SQL:
SELECT Products.ProductName
FROM Products
INNER JOIN Categories
ON Categories.CategoryID = Products.CategoryID
WHERE Categories.CategoryName = 'Beverages'
In Gremlin, this is translated simply to this traversal where you look for vertices (Categories in this case) that have the property “Beverages” and then follow the “in” connection/relationship which will give you a Product vertex:
g.V().has("name","Beverages").in("inCategory").values("name")
Finally, here is my favorite: an example of a recommendation query in T-SQL vs. Gremlin. The idea is to rank the top 5 products ordered by other customers who already ordered the same product. I took the full T-SQL for the recommender query and here is what the results look like in my SQL Server 2014 Management Studio:
SELECT TOP (5) [t14].[ProductName]
FROM (SELECT COUNT(*) AS [value], [t13].[ProductName]
FROM [customers] AS [t0]
CROSS APPLY (SELECT [t9].[ProductName]
FROM [orders] AS [t1]
CROSS JOIN [order details] AS [t2]
INNER JOIN [products] AS [t3]
ON [t3].[ProductID] = [t2].[ProductID]
CROSS JOIN [order details] AS [t4]
INNER JOIN [orders] AS [t5]
ON [t5].[OrderID] = [t4].[OrderID]
LEFT JOIN [customers] AS [t6]
ON [t6].[CustomerID] = [t5].[CustomerID]
CROSS JOIN ([orders] AS [t7]
CROSS JOIN [order details] AS [t8]
INNER JOIN [products] AS [t9]
ON [t9].[ProductID] = [t8].[ProductID])
WHERE NOT EXISTS(SELECT NULL AS [EMPTY]
FROM [orders] AS [t10]
CROSS JOIN [order details] AS [t11]
INNER JOIN [products] AS [t12]
ON [t12].[ProductID] = [t11].[ProductID]
WHERE [t9].[ProductID] = [t12].[ProductID]
AND [t10].[CustomerID] = [t0].[CustomerID]
AND [t11].[OrderID] = [t10].[OrderID])
AND [t6].[CustomerID] <> [t0].[CustomerID]
AND [t1].[CustomerID] = [t0].[CustomerID]
AND [t2].[OrderID] = [t1].[OrderID]
AND [t4].[ProductID] = [t3].[ProductID]
AND [t7].[CustomerID] = [t6].[CustomerID]
AND [t8].[OrderID] = [t7].[OrderID]) AS [t13]
WHERE [t0].[CustomerID] = N'ALFKI'
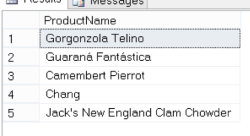
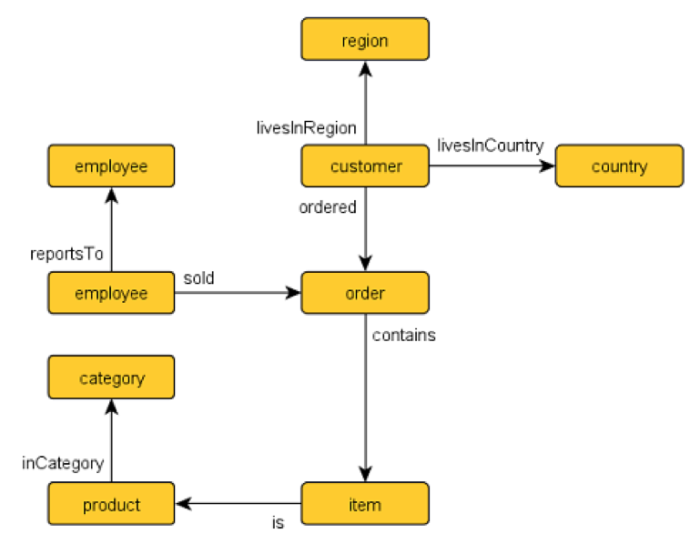
By contrast, you can see the much more natural language of Gremlin where you traverse the relationships that are stored naturally in the graph model. Your starting point is the vertex for the customer with ID of “ALFKI” and you set a marker of “customer” to that node. Use the graph model diagram that I copied from Daniel’s site below. Follow the “out” arrows in the query from “ordered” to “contains” to “is” to end up at “Product”. You can then walk back up the graph using the “in” connects and eliminate the current customer using the customer marker.
gremlin> g.V().has("customerId", "ALFKI").as("customer").
out("ordered").out("contains").out("is").aggregate("products").
in("is").in("contains").in("ordered").where(neq("customer")).
out("ordered").out("contains").out("is").where(without("products")).
groupCount().by("name").
order(local).by(valueDecr).mapKeys().limit(5)
==>Gorgonzola Telino
==>Guaraná Fantástica
==>Camembert Pierrot
==>Chang
==>Jack's New England Clam Chowder
So, that’s it for now. Again, please be sure to see the rest of the samples on Daniel’s site: http://sql2gremlin.com and the rest of the Apache TinkerPop project for graph computing. Also, stay tuned for upcoming announcements here from DataStax regarding the addition of a native Cassandra-based graph database that will be part of an upcoming DataStax Enterprise release.












