

Today’s infrastructure architects need to manage large-scale, enterprise Apache Cassandra® clusters to meet emerging AI data needs. To simplify that layer, we introduced DataStax Mission Control, an all-in-one platform for distributed database operations, observability, and deployment. As Mission Control is built on Kubernetes, it requires a slight shift in mindset. After all, nothing handles distributed data infrastructure better than Kubernetes.
Cassandra on Kubernetes? Yes, please!
Astra DB is renowned as an easy-to-use, cloud-based database. Many of our customers have come to us with requests similar to “We want Astra, but we want to manage it on our infrastructure.”
Unfortunately, for many tech shops that don’t already run on it, hearing the name “Kubernetes” is enough for them to pump the brakes. Yes, that name can conjure up images of vastly complicated network architectures, mind-numbing levels of abstraction, and command line entries that are both cryptic and verbose.
But what many don’t understand is that under the hood, Kubernetes is Astra DB’s “secret sauce.” It’s what makes it work so well, and ultimately what enables developers to focus on building their AI applications instead of their database.
A detailed look
Let’s have a look at what happens when a cluster is created inside of Mission Control. First of all, Kubernetes pods are created for each of the database cluster nodes. The cluster also spins-up a pod for Cassandra Reaper to manage cluster repairs. If the cluster is based on DataStax Enterprise (DSE) or DataStax Hyper-Converged Database (HCD), operators have an option to indicate for a pod to be created for client access via the DataStax Data API. These components can be seen in Figure 1.
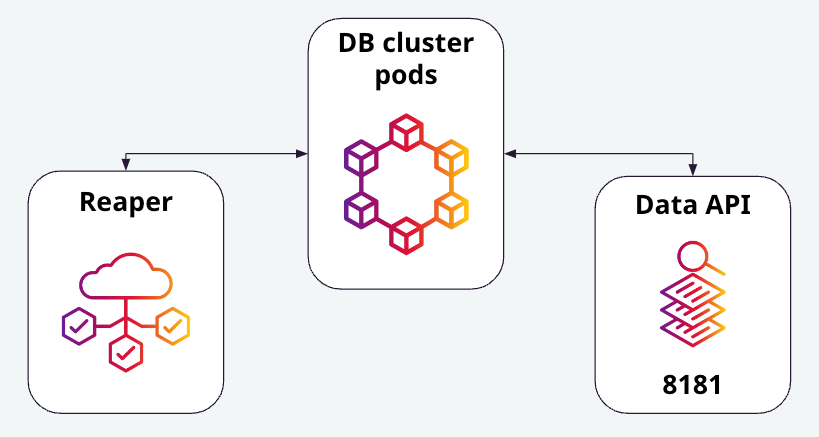
Figure 1 - The Cassandra database cluster pods shown with individual pods for Reaper and the Data API.
Zooming in further, we can see that the pods for each database node have three containers running inside of them. First and foremost, one of them is the database instance itself, and is one of either Cassandra, DSE, or HCD. Next, a container image is running for the system logger, which is a logging “helper” from the K8ssandra project. Finally, a container for Medusa (Cassandra backup system) is also created, to handle any backup requests from the node. These containers can be seen in Figure 2.
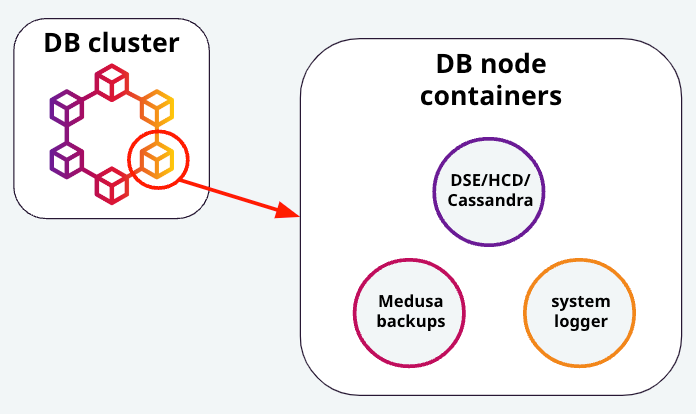
Figure 2 - A visual representation of the containers running inside of each database node pod.
Additionally, pods with containers for Mimir (metrics and observability) and Loki (logs) are also running. They’re created at the time of installation for Mission Control, and are running inside of its namespace.
So what does all of this mean? It means that when you create a new cluster in Mission Control, in addition to a distributed database cluster running either Cassandra, DSE, or HCD on your infrastructure, you get:
- Reaper integrated for automating repairs
- Medusa integrated for automating backups
- Out-of-the-box logging and observability
- Data API for client access for easy integration with generative AI libraries and services
Why is this a big deal? Because all of the extras mentioned above usually require extra deployment steps. All of these extras are seamlessly, automatically installed and configured by leveraging Kubernetes. So not only do you get all of those extras, but the work required to integrate them is already done.
The path to business value
When you deploy your Cassandra footprint with Mission Control, you get a lot of extras. But thanks to its foundation on Kubernetes, those extras are fully-integrated with every new cluster that you create. And that’s on top of the node auto-healing that is intrinsic to Kubernetes, helping to maximize your cluster’s availability.
While Mission Control is certainly a game-changer for managing Cassandra databases, It’s important to remember …
Mission Control and Kubernetes are not the thing. They’re the thing that gets us to the thing.
Nobody seeks out things like Mission Control, Kubernetes, Cassandra, or even GenAI. Enterprise leaders seek out solutions that provide business value. Ultimately, that’s what our Kubernetes-based platform does. It greatly simplifies the distributed, AI data paradigm, providing the path for information technology organizations to drive business value.
Want to modernize your Cassandra workloads with Kubernetes? Check out our enterprise Cassandra resources and request a free consultation.
Have questions about how to support AI workloads with Astra DB, Mission Control, DSE, or HCD? Be sure to check out our DataStax Developers Discord server, to get your answers!
Leaders like Barracuda and Temporal manage Apache Cassandra® with Astra DB. You can too.
Create a ClusterCassandra on Kubernetes? Yes, please!
A detailed look
The path to business value
More Technology
View All
New AI Agents Survey: Trust, Control, and Reliability Remain Concerns

Unlocking Local AI: Using Ollama with Agents

Spread the Love with DataStax this Valentine's Day!
