

Vector databases are a critical component of generative AI applications. Using one, however, means adding another component to your application architecture that you have to design, deploy, fine-tune, scale, and maintain.
AWS has long helped engineering teams simplify the deployment and maintenance of cloud application infrastructure. Can they do the same for vector databases? In this article, we’ll look at how to choose a vector database on AWS - and the inevitable tradeoffs involved with each option.
What is a vector database?
A vector database is a storage system that handles and supports queries across high-dimensional vector data. “High-dimensional” describes any data where the number of features (attributes or properties) exceeds the number of observations (records). (In table terms, the data has more columns than rows.)
High-dimensional data can be hard to handle because there aren’t enough records from which to draw a statistically sound relationship between predictor and response variables. Taking this into account, vector databases convert their data into numerical embeddings and then employ vector search algorithms that compare the distance between data points.
The result is that vector databases can return a larger volume of data with a broader scope than traditional keyword searches. That makes vector databases well-suited to use cases such as building recommendation engines.
For the same reason, vector databases are the primary data source used to retrieve data for use in retrieval-augmented generation (RAG). RAG uses vector search to find potentially relevant context - customer support call transcripts, documentation and manuals, FAQs, knowledge bases, etc. - to include in prompts to generative AI models. This results in more accurate and up-to-date responses from large language models (LLMs).
Hosting a vector database on AWS
The downside of a vector database is that it’s yet another element of your architecture that can become a point of failure. Any data store you deploy needs to be designed for high performance, reliability, and scalability.
As a general cloud services provider, Amazon Web Services (AWS) provides easy access - via console, command line, and API commands - to computing power on demand using a pay-as-you-go model. In addition, it provides numerous features and services that simplify scaling and managing various types of high-availability workloads.
AWS is a solid choice for hosting a vector database, as it has a reputation for delivering high-availability services at a decent cost. In addition, if you run the rest of your infrastructure on AWS, it makes sense to run your vector database there and integrate it with other AWS services (e.g., Identity and Access Management for admin access, CloudWatch for monitoring and alerting, Secrets Manager for storing credentials, etc.).
AWS vector database hosting patterns
There are three general approaches you can take to hosting a vector database on AWS. Each has different pros and cons. Which one you use will depend on your staffing levels, the level of trained support you have on hand (systems engineering/SRE support), and your available budget.
Self-hosted
The good news is that AWS provides the basic building blocks for hosting any data store you choose. You can use EC2 virtual servers to run and scale your database, Elastic Block SStorage (EBS) for storage, and Elastic Load Balancing to distribute traffic across EC2 instances.
The plus sides of the self-hosted approach are:
- You’re not limited in what vector database software you can use
- You have complete control over performance and scaling criteria
- You’ll generally pay less in direct AWS costs compared to managed or serverless (more on that below)
- All capacity and data is isolated to your AWS account, giving you full control over security
The down side is that a self-hosted service requires a lot of time and expertise to run well. You should only go this route if you have dedicated engineering and support staff to deploy, monitor, and troubleshoot issues, and if the data shows that you can only get the performance you need through direct management.
Managed
Managed services are AWS services where the cloud vendor spins up dedicated capacity in your account but manages certain aspects of the service for you.
A good example is Amazon Relational Database Service (RDS). Using RDS, you can spin up instances of databases such as PostgreSQL or MySQL. You control the configuration and scaling, while AWS provides support for automated patching and regular backups.
Managed services are simpler to stand up and maintain than self-hosted services. However, you’ll still need someone who can monitor them and fine-tune them for performance.
Serverless
A serverless service is one where AWS completely runs and manages the underlying infrastructure. All resources, such as compute and storage, are managed by AWS and generally shared across customers.
For example, in contrast to Amazon RDS, Amazon Aurora Serverless is a fully serverless database hosting option built on AWS’s Aurora database engine. Using Aurora Serverless, you don’t stand up database instances - you simply specify the capacity range you desire and the service handles the rest.
The allure of serverless services is that there’s zero infrastructure to manage - AWS manages it entirely on your behalf. Serverless services also scale, automatically and instantly, to hundreds of thousands of transactions a second without any configuration required.
One downside is that serverless services are generally more expensive than their self-hosted and managed counterparts. Basically, you’re paying extra to get extra. However, the amount of money you save in engineering time often offsets the increased opex costs.
Additionally, since serverless utilizes shared capacity, it may not be an option for use cases in highly regulated industries with strict security requirements.
Vector database options on AWS
Given this, you have multiple options for hosting a vector database on AWS.
One of the easiest options for managed hosting is using Amazon RDS for PostgreSQL. The PostgreSQL pgvector extension supports vector storage and search. It supports exact and approximate nearest neighbor search, plus a number of distance measures.
Amazon Aurora, which is AWS’s PostgreSQL-equivalent database engine, also supports pgvector. AWS contends that Aurora performs better than standard PostgreSQL for high throughput and high concurrency workloads.
AWS also supports vector search in several other managed database offerings, such as its Neptune graph database service and its managed OpenSearch service. For document search support, you can use Amazon DocumentDB, a fully managed native JSON document database.
For self-hosted options, you can host Apache Cassandra® 5.0, a scalable, distributed NoSQL database that supports high-velocity data with simple queries powered by Cassandra Query Language (CQL). In addition to its other capabilities, Cassandra 5.0 supports fast and scalable vector search, enabling support for querying unstructured data and performing similarity-based searches.
(Note that AWS also offers KeySpaces, a serverless Cassandra-compatible storage and lookup service. However, KeySpaces doesn’t include Cassandra’s vector search support.)
Astra DB - serverless Cassandra on AWS
If you want the benefits of Cassandra without the overhead of self-hosting, DataStax offers Astra DB, a serverless vector database built on Cassandra.
Using Astra DB, you can quickly bring vector data to your GenAI apps with petabyte scalability and low latency. Astra DB eliminates all the costs, labor, and potential downtime associated with self-hosting.
You can also build your GenAI apps quickly using LangChain and DataStax-hosted Langflow. LangChain integrates seamlessly with Astra DB. Besides streamlining development, LangChain helps create robust, scalable apps out of the box, reducing the time required to move from prototype to production.
Concerned about security? Astra DB integrates with AWS PrivateLink to prevent your data from traveling over public networks.
Conclusion: Choosing a vector database on AWS
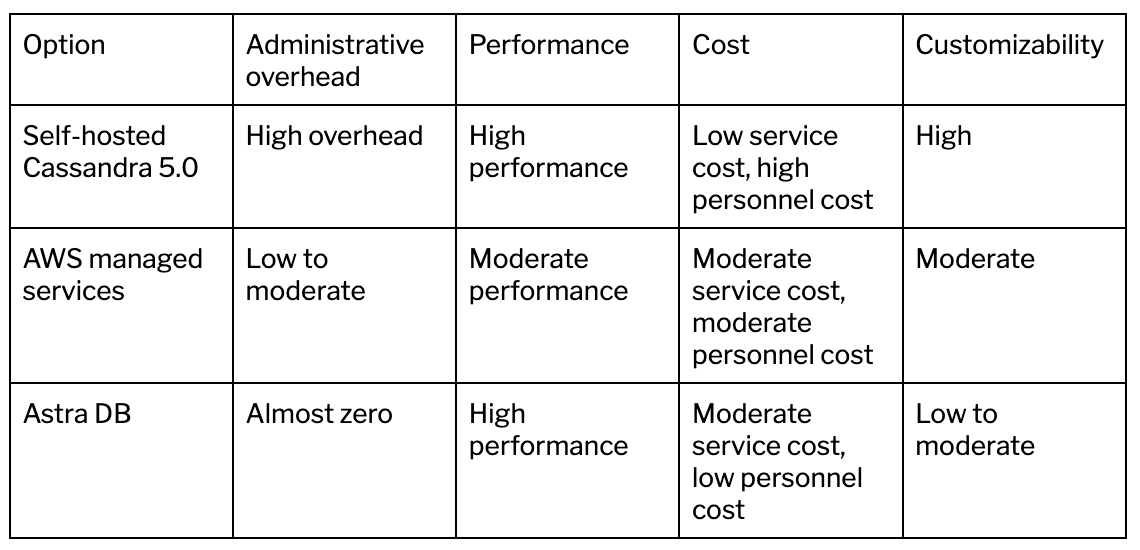
As a fully-featured cloud provider, there are often multiple ways to perform the same task on AWS. That’s especially true when it comes to vector database hosting. You have several options depending on what mix of up-front cost and personnel support you desire:
With DataStax, you can add GenAI support to your apps quickly without stressing over infrastructure. To learn more, sign up for a free trial today.












