

Anti-entropy repair in Cassandra can sometimes be a pain point for those doing deletes in their cluster, since it must be run before gc_grace expires to ensure deleted data is not resurrected. Reliable hints can go a long way to alleviating this, but if you lose a node at any point, you'll still need to repair (though it's worth mentioning that if you only delete via TTL, and only inserted with a TTL to begin with, you can skip repair if your cluster has synchronized time, which it should for a variety of reasons.)
Repair can be a sore point for a couple of reasons that I'll outline, and then show you how to avoid them. First, let's recall how repair works. There are two phases to repair, the first of which is building a Merkle tree of the data. The second is having the replicas actually compare the differences between their trees and then streaming them to each other as needed.
This first phase can be intensive on disk io, however. You can mitigate this to some degree with compaction throttling (since this phase is what we call a validation compaction.) Sometimes that isn't enough though, and some people try to mitigate this further by using the -pr (--partitioner-range) option to nodetool repair, which repairs only the primary range for that node. Unfortunately, the other replicas for that range will still have to perform the Merkle tree calculation, causing a validation compaction. This can be a problem, since all the replicas will be doing it at the same time, possibly making them all slow to respond for that portion of your data. Fortunately, there is way around this by using the -snapshot option. What this will do is take a snapshot of your data (and recall that snapshots are just hardlinks to existing sstables, exploiting the fact that sstables are immutable, thus making snapshots extremely cheap) and sequentially repair from the snapshot. This means that for any given replica set, only one replica at a time will be performing the validation compaction, allowing the dynamic snitch to maintain performance for your application via the other replicas.
There's a possible catch in the second phase of repair, too: overstreaming. This is when you maybe have only one damaged partition, but many more end up being sent. This happens because the Merkle trees Cassandra builds don't have infinite resolution, and enabling a high enough resolution for all scenarios would end up being prohibitive in terms of heap usage, since the tree is held in memory. So Cassandra makes a tradeoff between the size and space, and currently uses a fixed depth of 32K for the tree. What this means is that if your node contains a million partitions and one of them is damaged, about 30 partitions are going to be streamed, since that is how many fall into each of the 'leaves' of the tree. Of course if you have many more partitions per node, the problem gets worse, and can end up using a lot of disk space that will eventually have to be compacted away, needlessly.
There is a solution for this problem too, beginning with Cassandra 1.1.11, called subrange repair. As the name suggests, this allows repairing only a portion of the data that belongs to a node. Since the tree precision is fixed, this effectively increases the precision overall. Using the describe_splits call, you can ask for a split containing 32K partitions (and if you're running DSE it makes this even easier,) and then repair it with 100% precision if you so choose, iterating throughout the entire range incrementally (or even in parallel.) This would completely eliminate the overstreaming behavior and have no wasted overhead in terms of disk usage. To do this, you pass the tokens you received for the split to the -st (--start-token) and -et (--end-token) options to nodetool repair, respectively. Finally, you can pass the -local (--in-local-dc) option to nodetool to only repair within the local datacenter, reducing cross-datacenter transfer.
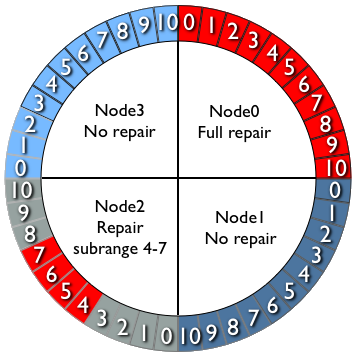
Above is a diagram illustrating the difference between a full and subrange repair. Node0 shows a full repair of the data in its range, while Node2 shows repairing only a subset of its data. When all the subsets have been repaired it will be equivalent to the full repair.
I hope this article has both increased your knowledge about repair and its available options. In future repair operations during management of your Cassandra cluster, it can hopefully improve your experience and solve any issues you may encounter. We hear quite frequently from operations folks and admins that they struggle with knowing exactly when and how often to run repair on their clusters. This being the case, at DataStax, we're looking into how to make repair a transparent operation that runs automatically when needed via OpsCenter with minimal impact on performance.
More Technology
View All
Simplifying Ground Truth Generation for LLMs

How to Build Graph RAG with Unstructured and Astra DB

