

We’ve all seen the power that semantic vector search can bring to an application. Its ability to match on meaning and context more than just words helps our applications locate related information that we might have otherwise missed if using more traditional search techniques.
Hornet, a leading LGBTQ+ social network and dating app with over 40 million members worldwide, is on a mission to create a global safe space where queer individuals can connect and be themselves. Hornet has been using Apache Cassandra® to operate at this scale, and has a long partnership with DataStax.
The use case
In 2023, we worked with the Hornet team to bring vector search to their application as a way to enable improved user profile matching. The goal of a matching application is to present users with lists of other users who they may be interested in meeting. For this purpose, vector search provides a great way to match based on natural language expression of interests and what a user is seeking.
But vector search on its own can’t provide a complete set of matches. For example, users might have a strong preference for people of a specific gender (or non-gender), or they might not be interested in traveling long distances to meet up with a potential partner. This requires some additional filtering capabilities.
Architecture
The Hornet architecture consists of a Rails-based application connected to both Postgres and DataStax Astra DB databases. User profiles are vectorized using OpenAI, and are periodically refreshed:
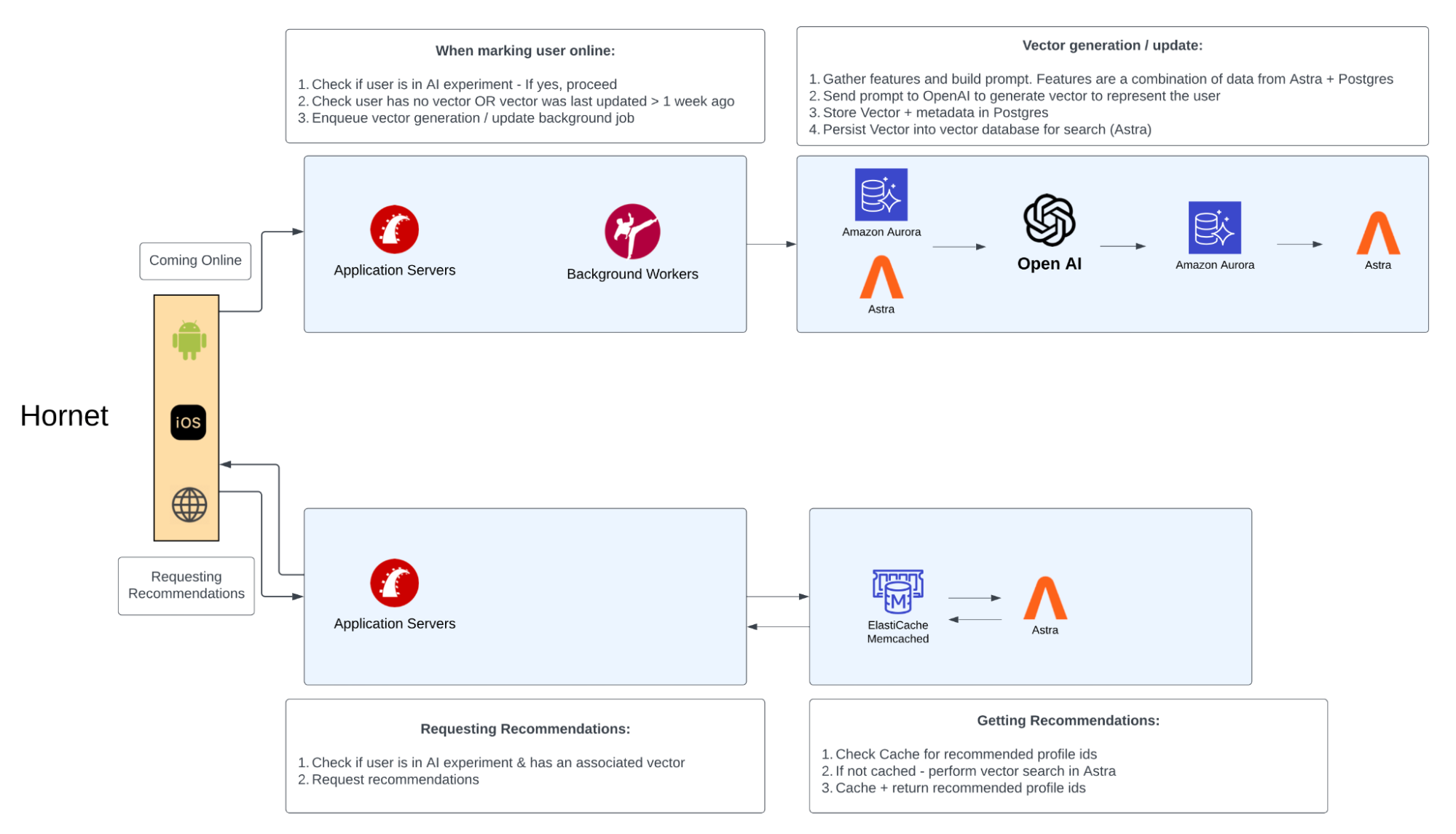
When the application looks to get recommended matches, it uses a combination of Amazon ElastiCache and Astra DB to find matching profiles.
Vector database feature: Storage Attached Indexes (SAIs)
DataStax Enterprise (DSE) has long had a supplemental indexing type called Storage Attached Indexes (SAIs). Contributed to Cassandra and adopted in Cassandra 5.0, SAI supports numeric, text, and vector data types. The Astra DB documentation provides more details about SAI; Astra DB also supports a “text analyzer” index type that facilitates search term matching.
SAIs enable you to specify WHERE (filtering) clauses on queries without specifying partitioning columns; they’re also a helpful addition to vector search queries. With this, Hornet can do a search for profiles based on a vector search combined with a filter to constrain matches within a geographic distance of the user, and combine with other profile attribute matching criteria.
Vector database feature: GEO_DISTANCE function
One could define separate “latitude” and “longitude” numeric columns with SAIs on each of these, and then create a bounding box to contain the search. But Astra DB provides a GEO_DISTANCE function that can filter records within a radius of a latitude/longitude pair, once the column is defined as a VECTOR<FLOAT,2> and there is an associated SAI that uses the euclidean similarity function.
This convenient construct can enable Hornet to do a more natural radius search, and with a single pair of values in a single clause. (Note that this function is, as of this writing, a preview feature.)
SAIs, even easier: The Data API
Defining explicit columns and indexes suits many developers and architects, but there are others who prefer a simpler experience that doesn’t require explicit data modeling. DataStax’s Data API provides a means to define and query document collections, and filter on fields within these collections. Under the covers, Astra DB creates SAIs, but with a simpler experience that does not require data modeling. The Data API supports JSON document formats, including vector data types that can be used for semantic search in conjunction with filtering.
A Node.js example
This GitHub repository contains a working example of a Node.js application that uses the Cassandra module of Langchain.js to search for restaurants based on semantic similarity with a review, combined with a GEO_DISTANCE filter from a click point on a map:
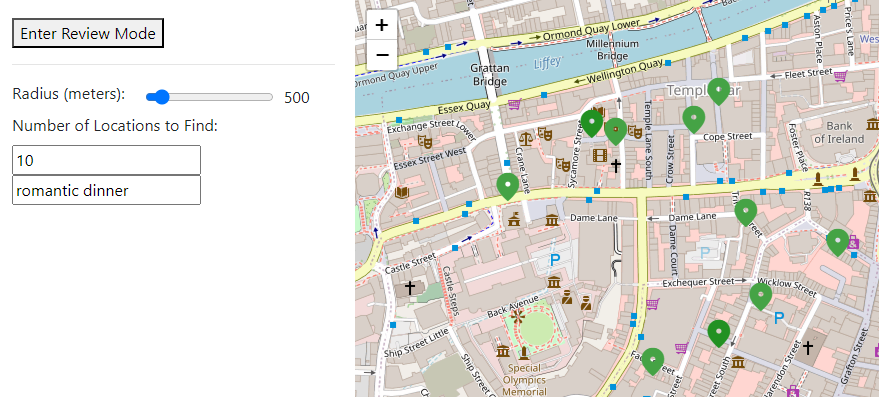
This is achieved in the function findWithinRadiusUsingText:
async function findWithinRadiusUsingText(
text: string, k: number, radius: number, lat: number, lon: number
): Promise<Amenity[]> {
const vectorStore = await astra.getVectorStore();
const filter = {
name: "GEO_DISTANCE(coords,?)",
operator: "<=",
value: [new Float32Array([lat, lon]), radius]
};
const results = await vectorStore.similaritySearchWithScore(text, k, filter);
const documents = results.map(result => result[0]);
const scores = results.map(result => result[1]);
const amenitiesMap = processAmenityResults(documents, scores);
return Array.from(amenitiesMap.values());
}
Langchain.js also provides Astra DB modules if you prefer the Data API; the example application defines a data model.
Usefully, the caller can specify a k (number of records) without oversampling the vector results in the hopes that enough records would survive post-query application-side filtering; the filtering can be done within Astra DB, at query time. This filter could be extended beyond just a single GEO_DISTANCE search. Other desirable attributes could be added to the filter.
Wrapping up
Using Astra DB’s SAI feature, Hornet can not only find matching users based on powerful vector search technology, but also refine those matches based on distance from the user’s address and other more structured attributes of other users such as gender.
This feature can be accessed through frameworks such as Langchain.js, more directly through the Data API, or (as in Hornet’s case), directly through any programming language (like Ruby!) with an available Cassandra driver that supports vector search.




