

DataStax recently announced the latest version of its widely-used enterprise grade distributed database, DataStax Enterprise 6.9 (DSE 6.9). With the battle-tested Apache Cassandra® at its core, DSE 6.9 gives you all of the stability that your organization has come to expect, while also delivering new functionality and features to help usher your enterprise into the future. In this post we will take a look at DSE 6.9 and explore the new features it brings to the enterprise.
What’s new
DSE 6.9 has several new features to help modernize your enterprise workloads. If you’re running on an earlier version of DSE, we think these advancements will convince you to perform an upgrade today!
Improved indexing
Storage attached indexes (SAI) are the latest improvement on Cassandra secondary indexing. SAIs require significantly less storage and offer a performance boost to numeric range queries. The SAI implementation in DSE 6.9 enables indexes on string data to work with different types of analyzers (example: case-insensitive), and also functions as the “backbone” of vector search. Additionally, this feature allows for the use of the “OR” operator (on indexed columns) in a Cassandra Query Language (CQL) query.
Support for Java 11
DSE 6.9 supports Java 11, which itself provides a number of new features (when compared to its predecessors). Running DSE on Java 11 gives your cluster improved profiling, access to new garbage collectors, and even helps to secure your database infrastructure with the latest Transport Layer Security (TLS) 1.3 certificates.
Data API
DSE 6.9 also allows access via the DataStax Data API. The same easy-to-use access interface that previously only DataStax Astra DB users enjoyed is now available with DSE. There is no need for traditional Cassandra data modeling. This document/JSON-based approach greatly simplifies the development process and helps keep your developers focused on building applications.
Vector search
Building AI applications has been all-the-rave over the last year or so, and in no small part due to the rise of retrieval-augmented generation (RAG) for natural language processing. One of the key components in these types of applications is a vector database. The output of most large language model (LLM) operations is a vector formed as a large-dimensional floating point array. Vector databases provide a way to natively work with RAG context data.
DSE 6.9 can work with native vector data types, enabling you to store and index your vector data. There is no need for a separate vector database, as the vector data can even be stored in the same table in DSE. This enables easy access for all of your application’s vector searching needs.
Installation
The installation process for DSE 6.9 does not change, but it does offer an easier option. Running a manual installation of DSE 6.9 will be identical to previous versions, as will introducing it into your current deployment pipeline. But for those of you running on Kubernetes, a new DSE 6.9 cluster can be quickly deployed using DataStax Mission Control (as shown in Figure 1).
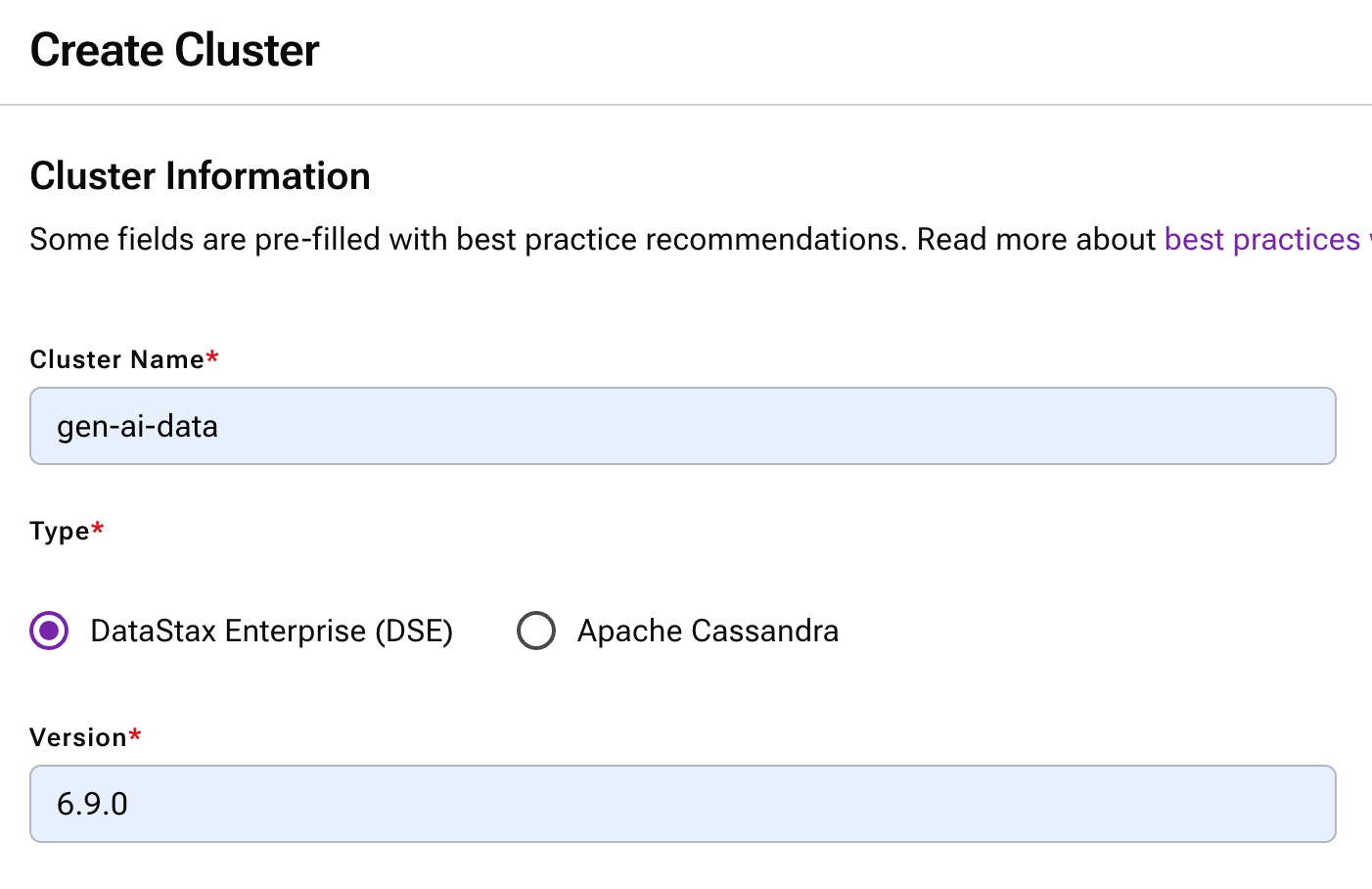 Figure 1 - Creating a new DSE 6.9 cluster using DataStax Mission Control.
Figure 1 - Creating a new DSE 6.9 cluster using DataStax Mission Control.
Here you can specify your cluster’s name, and select the option for “DataStax Enterprise (DSE)” with 6.9.0 specified as the version. During this process you will also be able to name your data centers and racks, as well as specify your nodes’ RAM, Java heap sizes, and storage option.
Examples with DSE 6.9
Here are two examples to demonstrate some of the new features of DSE 6.9. We’ll show how to perform a vector search, use the Data API, and how to use a text analyzer plus the “OR” operator.
Vector search CQL example
As mentioned above, vector search enables developers the capability to build RAG applications for generative AI (GenAI) while storing the vector data context in a local vector database. Usually, the output returned from encoding data with LLMs is formatted as a vector. DSE 6.9 comes with a native vector data type, which enables developers to store vectors as arrays of floating point numbers.
However, vector search can also be used to support non-LLM use cases. Let’s say that you have a website for developer job postings. A vector search could be run when a potential applicant wants to see which jobs match their profile.
First, you’ll need to create a table to store the data, with a 3-dimensional float for your vector:
CREATE TABLE jobs (
title text PRIMARY KEY,
salary decimal,
database text,
education text,
language text,
job_vector vector<float, 3>
);You’ll also need an SAI on the job_vector column:
CREATE CUSTOM INDEX jobs_job_vector_vector_idx ON jobs (job_vector) USING 'StorageAttachedIndex';
As you build your dataset, you’ll encode your vectors as a combination of the non-numeric columns of education, database, and language to integers:
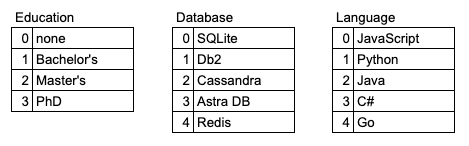
So if you had a job that required a bachelor’s degree with experience in Astra DB and Java, the job_vector column data would look like this: [1, 3, 2].
Similarly, we could perform a vector search, leveraging an approximate nearest neighbor (ANN) algorithm on our jobs table. Below, a CQL query is shown for an applicant with a bachelor’s degree and experience in both Astra DB and Python with a vector of [1, 3, 1]:
> SELECT title, education, database, language, job_vector,
similarity_cosine(job_vector,[1,3,1]) AS similarity FROM jobs
ORDER BY job_vector ANN OF [1,3,1] LIMIT 3;
title | education | database | language | job_vector |similarity
-------------------+------------+-----------+----------+------------+----------
Staff AI Engineer | Bachelor's | Astra DB | Python | [1, 3, 1] | 1
Backend Engineer | Bachelor's | Cassandra | Python | [1, 2, 1] | 0.992366
Lead AI Engineer | Master's | Astra DB | Python | [2, 3, 1] | 0.983494
(3 rows)Note how the similarity_cosine function (above) returns the similarity “score” of your results. In this way, you can see how DSE 6.9 with vector search could be used, even if your enterprise is still at the beginning of its AI journey.
Example: Case-insensitive “OR” query
Expanding on the jobs table example from above, let’s say that you wanted to be able to query that table by the language column. Remember that Astra DB, Cassandra, and DSE are case sensitive by default. But if you wanted to relax case sensitivity for the language queries, you could do that by adding an SAI with an analyzer and the “lowercase” filter:
CREATE CUSTOM INDEX jobs_language_idx ON stackoverflow.jobs (language)
USING 'StorageAttachedIndex'
WITH OPTIONS = {'index_analyzer': '{"filters": [{"name": "lowercase"}] } '};Now you can use that index to query for jobs requiring skill in Java or Python, and the case of the letters doesn't matter:
> SELECT title, education, database, language FROM jobs
WHERE language: 'jAva' OR language: 'pythoN';
title | education | database | language
--------------------------------+------------+-----------+----------
Staff AI Engineer | Bachelor's | Astra DB | Python
Principal Engineer - Ecommerce | Master's | Cassandra | Java
Backend Engineer | Bachelor's | Cassandra | Python
Lead Software Developer | none | Cassandra | Java
Lead AI Engineer | Master's | Astra DB | Python
(5 rows)This is possible because you used the non-tokenizing analyzer “lowercase” to index (and subsequently compare) the data in the language column in lowercase. Do note that when querying a column with an analyzer-powered SAI (as seen above), it’s necessary to use the ‘:’ operator to specify the text conditions.
Data API example
DSE 6.9 can also be used with the Data API, which allows data to be queried via HTTP post requests. These requests can be sent to your API-enabled DSE 6.9 cluster from your applications or from web request tools like Postman or curl. By default, the Data API handles requests over port 8181.
Remember that the Data API with DSE 6.9 needs to be queried using a Document/JSON approach. This paradigm uses terminology that differs from Cassandra data modeling:
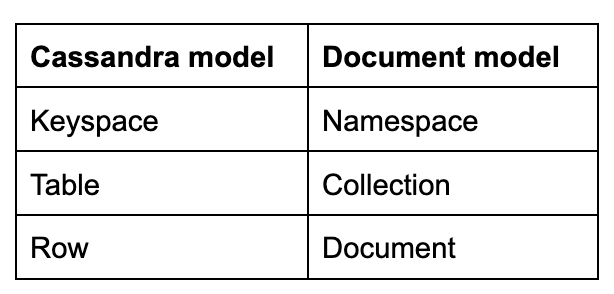 A mapping of common terms between Cassandra and Document modeling methodologies.
A mapping of common terms between Cassandra and Document modeling methodologies.
Creating a collection
For this example, let’s assume that our application acts as a digital library of technical books. To support this, we will create a collection named “library.” We can do this inside of an existing namespace named “default_keyspace,” using the following curl command:
curl -X POST 'http://1.2.3.4:8181/v1/default_keyspace' \
-H 'Token:Cassandra:a2VzLNotRealc2Vy:mVbmNotRealZXJGbG90aWxsY' \
-H 'Content-Type:application/json' \
-H 'Accept:application/json' \
-d '{"createCollection": {"name": "library"}}'Inserting a document
A single book document can be inserted into our “library” collection in a similar way:
curl -X POST 'http://1.2.3.4:8181/v1/default_keyspace/library' \
-H 'Token:Cassandra:a2VzLNotRealc2Vy:mVbmNotRealZXJGbG90aWxsY' \
-H 'Content-Type:application/json' \
-H 'Accept:application/json' \
-d '{"insertOne":
{"document":
{ "title": "Code with Java 21",
"author": "Aaron Ploetz",
"image": "java_book_cover.png",
"publisher": "BPB"}}}'The ID of the inserted document is returned:
{
"status": {
"insertedIds":[
"1d01fc5a-b363-4d3b-81fc-5ab3639d3b6d"
]
}
}Querying a document
A single book document can be easily queried using the ID returned above:
curl -X POST 'http://1.2.3.4:8181/v1/default_keyspace/library' \
-H 'Token:Cassandra:a2zLNotRealUserVy:mVbmNotRealPwdGbG90aWxsY' \
-H 'Content-Type:application/json' \
-H 'Accept:application/json' \
-d '{"findOne":{"filter":{"_id":{ "$eq":"1d01fc5a-b363-4d3b-81fc-5ab3639d3b6d"}}}}'Note: The “Token” header property has three parts, each delimited by a colon ‘:’. A valid token begins with the word “Cassandra” as its first part. It is then followed by the base-64 encoded values of the username and password (of an existing DSE role) for its second and third parts.
Summary
We've discussed the major features of DataStax Enterprise 6.9, showed a little about the installation process, and even ran a simple vector search example. But if you really want to see what the latest and most advanced version of DSE can do, you need to bring DSE 6.9 into your enterprise.
Many enterprises are still very early in their GenAI journey. If you want to stay ahead of your competition and build innovative AI applications on top of your existing DSE clusters, upgrade to DSE 6.9. Running your Cassandra workloads on DSE 6.9 will help improve their performance and bring them into an incredible future. Be sure to check out and download DSE 6.9 today!
For more examples and information, have a look at our DSE 6.9 playlist on YouTube!
Leaders like Barracuda and Temporal manage Apache Cassandra® with Astra DB. You can too.
Create a ClusterWhat's new
Improved indexing
Support for Java 11
Data API
Vector search
Installation
Examples with DSE 6.9
Vector search CQL example
Example: Case-insensitive “OR” query
Data API example
Creating a collection
Inserting a document
Querying a document
Summary
More Technology
View All

Simplifying Ground Truth Generation for LLMs

