

As we've worked towards 1.0 over the past year, Cassandra's performance has improved spectacularly. Compared to the current release this time in 2010, we've increased our write performance a respectable 40%. But the real area we wanted to focus on improving was read performance, which we succeeded in increasing a phenomenal 400%!
Reads
There are actually two different execution paths for reads in Cassandra: you can request columns by name (SELECT x, y, z FROM foo, in CQL), or by slice (SELECT x .. z FROM foo), which gives all columns between column x and column z, inclusive, in comparator order.
Cassandra 1.0 optimizes slice reads by using a lighter-weight data structure for representing a row fragment from a read, than for a row fragment in a memtable into which we are accumulating updates. This results in about a 25% improvement in throughput.
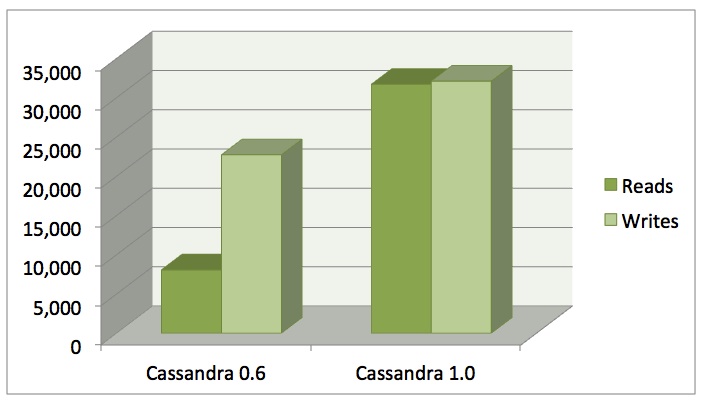
Read/write performance on a single four-core machine. One million inserts followed by one million updates
With named reads we can make a bigger improvement by only deserializing the most recent versions of the requested columns. This sounds obvious, and in fact Cassandra did this all the way back in 0.3. The trick is dealing with data that arrives in the "wrong" order because of network partitions, node failures, and so forth. Early Cassandra couldn't do this, so we removed the optimization in 0.4, and finally added it back correctly for 1.0. Combined with the other optimizations we've made in the year since 0.6 was released, this makes reads in Cassandra as fast as writes for many workloads.
The benchmark on the right was run with tiered compaction and uncompressed data to give an apples-to-apples comparison, but leveled compaction and compression can further improve read performance.
Writes
The big improvement made to writes in Cassandra 1.0 was to switch to arena allocation for memtables.
Recall that memtables are where Cassandra collects updates in memory prior to writing them out to disk. This means that they will almost always be promoted to the old generation under the Sun/Oracle JVM. The Sun JVM gives you several options for how to run garbage collection on the old generation, but they fall into one of two categories: non-compacting and concurrent, or compacting and non-concurrent.
"Concurrent" GC means that Cassandra threads can continue to run during garbage collection, with no pauses or at least very short ones. "Compacting" means that the GC process relocates used portions of the heap to end up with the free portion available as a contiguous region afterwards. Ideally, GC will achieve both, but Sun's JVM does not. (The details differ slightly, but neither does JRockit or IBM's JVM. Currently, only Azul's relatively expensive Zing does. Sun's G1 attempts to provide low-pause, compacting GC, but has other problems when structures like the ConcurrentSkipListMaps we use in Memtables generate a lot of intra-region references.)
Given this choice, most Cassandra deployments opt for the CMS (concurrent mark/sweep) collector. This gives you concurrent GC... until the heap becomes so fragmented that there is not enough contiguous space to perform a requested allocation. Then the JVM falls back to a "full," non-concurrent, compacting GC--the infamous "promotion failure" scenario.
Back to memtables: because they hold column values that often differ widely in size, they are the primary source of heap fragmentation in Cassandra. So the optimization in Cassandra 1.0 is to pre-allocate 1MB "arenas" for the memtables, into which we copy the columns being updated. The original Column objects are then collected in the young generation, which is always compacting because the young gen is much smaller than the old. Then when the memtable is flushed, the garbage collector can reclaim the entire arena at once, effectively eliminating fragmentation.
Two other things worth mentioning regarding write performance: Cassandra 0.8.1 introduced a bulk load tool that eliminates the memtable step entirely by essentially moving it to the client. This results in performance limited only by your sequential i/o speed, especially with 1.0's single-pass streaming optimization.
Finally, Cassandra 0.8.2 introduced durable_writes, a per-ColumnFamily setting that allows disabling the commitlog for particularly low-value data, in exchange for a 20-80% throughput impovement. (Note that if you have not done so already, ensuring that the commitlog is on a separate device can give you much of the benefit without the danger.)
Network
The above optimizations apply to node-local reads and writes. Cassandra 1.0 also optimizes intra-node reads and writes by reducing the copies done on its internal MessagingService system. This increases the efficiency of communication between nodes. Thus, while there is necessarily still a "penalty" over true linear scalability when moving, for instance, from a single node to two -- half your requests must now be routed off-node -- non-local operations are about 15% faster in in Cassandra 1.0.
Previously
- What's new in Cassandra 1.0, part 3: Leveled compaction
- What's new in Cassandra 1.0, part 2: Improved memory and disk space management
- What's new in Cassandra 1.0, part 1: Compression
- What's new in Cassandra 0.8
- What's new in Cassandra 0.7
- What's new in Cassandra 0.6
More Company
View All
Shaping the Wild in Las Vegas: An AWS re:Invent Recap

Announcing 12 Days of Codemas: The DataStax Holiday Giveaway!

London Called. RAG++, The AI Event, Answered!
