

Testing at Scale
Working as Software Engineers in Test at Datastax requires that we demonstrate that Datastax Enterprise is able to scale to handle "Big Data" but what does "Big Data" really mean? Some marketing departments would like "Big" to mean 100GB and others may just state that "Big Data" requires "10's of machines" to host. While these might be reasonable thresholds for some definitions of "Big", these definitions are actually quite conservative compared to many actual use cases of Datastax Enterprise. For these truly large systems we want to demonstrate that our users can trust Datastax Enterprise, and to that end we perform what we call the "1000 Node Test".
1000 Node Test Plan
Every major release of DataStax Enterprise sets in motion a variety of regression, performance, and scalability tests. This effort culminates with running a variety of tests and operations on a 1000 node cluster.
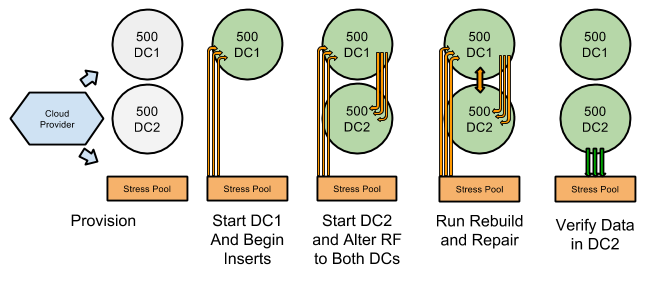
We test that standard administrative operations will continue to work properly even when working with a cluster that has 1000 members and is operating under load. The main test begins by provisioning 1000 nodes on one of our certified cloud providers (more details below) and separating these nodes into two 500 node groups.
Once configured, we start up the first datacenter. This begins the test with a blank 500 node cluster with a single datacenter. A separate set of ~10 nodes is utilized to start feeding data into these first 500 nodes. Inserts are generated using cassandra-stress with NetworkTopologyStrategy placing all of the data into the running datacenter. The second 500 nodes are started as a separate datacenter with auto-bootstrap turned off while inserts are still being performed on the cluster(Adding a Datacenter to an Existing Cluster). Once all of these nodes in the second datacenter are up, we alter the replication strategy of the stress keyspace so that information will be routed to both datacenters. While this is occurring we run nodetool rebuild and repair on each node. Once these operations and the full insert have completed successfully we verify that all of the written data can be read from the second datacenter.
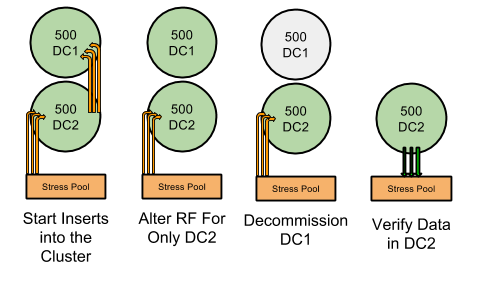
Following the successful addition of a 500 node datacenter we test the removal of 500 node datacenter. The test again begins with inserting data from a separate set of nodes into 1000 node cluster. The keyspace is then altered so that data only ends up being copied to the second datacenter. One by one, the nodes from the first datacenter are scrubbed and decommissioned from the cluster. Once the first datacenter has been successfully decommissioned we verify that the insert workload was completed successfully and all of the data we expect is on the second datacenter. This set of functional operations is usually followed by several more specific and feature related tests.
Technical Tips
The most difficult part of this exercise has routinely been the initial provisioning and installation of our software. When you are performing normal system operations at this scale usually trivial concerns become magnified into show stopping bottlenecks. Most cloud services are simply not designed to request a batch of 1000 nodes at once so a batched approach to launching can be useful. Additionally it can be useful to have your own framework around provisioning which can check as the nodes are created whether or not they are actually stable (functioning ssh, mountable drives, working os .) This becomes key when requesting such large numbers of nodes since the chance that you will receive a dud or two increases.
Another key issue we originally ran into was that 1000 nodes simultaneously downloading from our package server caused a great deal of stress and was a large bottleneck. Thanks to some advice from some of our partners at Google Cloud we ended up with far more efficient provisioning. Rather than having each node set itself up separately, we would create a single base node which would have all of the software and dependencies installed on it. This would then be snapshotted using the cloud provider's api. Most cloud providers (GCE, EC2, ect ...) allow for the launching of nodes from snapshotted images which ends up saving us a great deal of time. This brought the time initially required to configure our 1000 nodes down from several days to approximately an hour. Once all the software is in place we use our own cluster management tools to quickly configure Datastax Enterprise.
The Future of Testing at Scale
Data is only getting bigger and scaling horizontally has shown again and again that it is the only way to really get great performance for truly "Big Data." At Datastax we always have this in mind and to this end expect us to be testing on even larger clusters with greater volumes of data in the future.
More Technology
View All
Simplifying Ground Truth Generation for LLMs

How to Build Graph RAG with Unstructured and Astra DB

