
In Part 1 of our series on machine learning with Apache Cassandra®, we discussed the goals and approaches of machine learning, why Cassandra is the perfect tool for executing large datasets, and the tech stack of choice for companies like Uber, Facebook, and Netflix. Both posts in this series build on a video tutorial we’ve created called, “Machine Learning with Apache Cassandra and Apache Spark”.
In this post, we’ll give you an overview of how Apache Spark integrates with Cassandra to power machine learning and how to build effective algorithms and solutions. We’ll also discuss supervised vs. unsupervised data, machine learning metrics with examples, and give you a list of exercises you can try on GitHub to get familiar with different machine learning algorithms. So, follow along to find out how to write your very own machine learning code using Python, Cassandra, and Spark.
Cassandra for machine learning
Cassandra has several features that make it particularly useful for machine learning applications. These features, which are discussed in more detail here, are:
- Great scalability. When data starts counting in petabytes, you need a scalable database to tackle the challenges of machine learning.
- Cloud-native and masterless. A cloud-native database is essential for companies like Uber, Apple, and Netflix with a global user base. Cassandra is designed to build a single cluster out of multiple geographically distributed data centers enabling it to read and write from anywhere.
- Extreme fault tolerance. Not only is data distributed in Cassandra but also replicated throughout the cluster. By automatically replicating data to multiple nodes (usually three), the database will never be offline even if you need to replace nodes.
- Decentralized data distribution. For machine learning to work correctly, we need to continue feeding data into the database to make a decentralized and fault-tolerant database like Cassandra essential.
- Performance for data accuracy. Cassandra offers a high-availability and high-performance database built with a masterless architecture capable of supporting high-velocity machine learning algorithms with no single point of failure.
Adopting Cassandra as a single, one-size-fits-all database does have some downsides. Because of its decentralized data distribution model, it’s not very efficient to do certain types of queries or data analytics, especially when performing aggregations, data analysis, and the like. That’s where Apache Spark can help.
In our video tutorial, we show how adopting Spark alongside Cassandra can help solve these problems with hands-on machine learning exercises. DataStax has an enterprise solution with a pre-packaged integrated Cassandra and Spark cluster, but the actual libraries to connect both are open-source. We provide step-by-step instructions on GitHub and in our YouTube video on how to deploy Cassandra with Spark. We’ll provide an overview of how they work together here.
How Cassandra works with Apache Spark
While Cassandra is all about the storage and distribution of data, Spark is about computation. Cassandra and Spark fit very well together in big data architecture because Cassandra is well-designed to store and dispatch any amount of data in milliseconds and Spark handles complicated lab queries and data analytics. So, Cassandra stores the data; Spark worker nodes are co-located with Cassandra and do the data processing.
Let’s talk about data analytics here for a bit. Data analytics is the science of analyzing raw data to make conclusions about that data and support decision-making. Data analytics can be applied to:
- Making recommendations
- Fraud detection
- Social networks and web link analysis
- Marketing and advertising decisions
- Customer 360
- Sales and stock market analytics
- IoT analysis
Spark is a distributed computation engine designed for large-scale data analytics and in-memory processing. It’s a multi-language engine available in Python, SQL, Scala, Java, and R for executing data analytics and machine learning on single nodes or clusters. With Spark, you can conduct interactive and batch data analytics up to 100 times faster and 5–10 times less code than Apache Hadoop, another framework for distributed processing of large datasets.
Because Spark is integrated with Cassandra in a single binary on our DataStax Enterprise (DSE) solution, which features a unified database, search, and analytics all built on Cassandra, the solution is independent of the public cloud provider and completely portable. The consistent data management system is also built for on-premises, hybrid, and multi-cloud deployment.
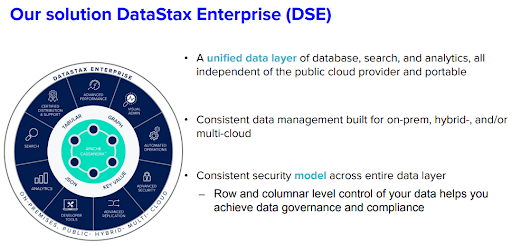
Figure 1. DataStax Enterprise (DSE) features.
Spark is excellent for conducting data analytics on DSE because it distributes competition among the nodes. As a batch-processing system, Spark is designed to deal with large amounts of data.
When a job arrives, the Spark workers load data into memory, spilling to disk if necessary. The important aspect of this is that there is no network traffic. The Spark worker understands how Cassandra distributes the data and reads only from the local node. To enable Spark on DSE, follow along with our YouTube video.
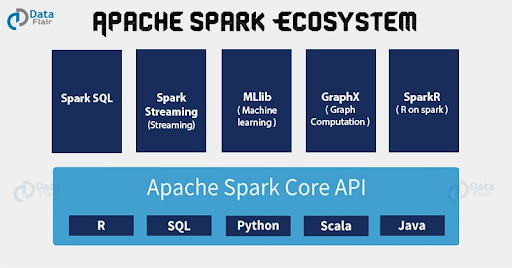
Figure 2. Apache Spark ecosystem.
In addition to easy integration with Cassandra, the Apache Spark ecosystem includes several features that can support machine learning:
- Apache SparkR. This is a front-end for the R programming language for creating analytics applications. SparkR is integrated with DSE to support the creation of dataframes from DSE data and popular for data scientists by providing tools like dataframes to manipulate data, support for data visualization, and several packages that support statistics and machine learning functions.
- GraphX. GraphX is a new component in Spark used for graphs and graph data modeling. It provides speed and capacity for running massively parallel and machine learning algorithms.
- Machine Learning Library (MLlib). MLliB is a machine learning library built on top of Spark with common learning algorithms and utilities. We will use MLlib in the hands-on exercises later on.
- Spark Streaming. This allows you to consume live data streams from different sources such as Kafka, Akka, and Twitter. The data is then analyzed by Spark applications and stored in a database. This then is processed using complex algorithms expressed with high-level functions. The processed data can be pushed out to filesystems, databases, and live dashboards.
- SparkSQL. With SparkSQL you can execute Spark relational queries over data stored in DSE clusters, using a variation of the SQL language. The high-level API offers a concise and very expressive API to execute structured queries on distributed data for machine learning. SparkSQL also allows a user to run relational SQL queries over Cassandra, which normally doesn’t support foreign keys and relations.
If you want to learn more about how to use Cassandra and Spark for machine learning, follow along with our video tutorial exercises.
Supervised vs. unsupervised data
There are multiple kinds of machine learning. Let’s talk about two commonly used types — supervised and unsupervised machine learning:
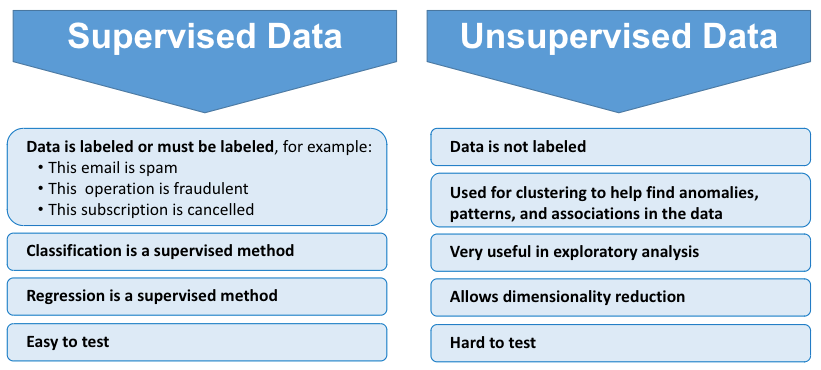
Figure 3. Supervised vs. unsupervised data.
An example of supervised data would be a spam detector, which builds and trains up an algorithm to detect spam emails based on an existing database of emails to build predictions. Emails can be marked as spam – or not spam – by users, on top of scanning for suspicious words.
When an email has been dispatched 100,000 times and marked as spam out of 100 times, supervised machine learning labels it as spam. Then, it predicts whether the next email is spam.
Supervised data means that the data is labeled, or must be labeled. Similar to identifying fraudulent bank transactions, machine learning must sift through a huge collection of different operations and routes to label and establish a rhythm for accurate predictions.
Other supervised data methods include classification and regression. To explore these algorithms, check out our YouTube tutorial or GitHub to access Jupyter notebooks to try some of them out.
A note about machine learning metrics
Metrics are also critical to deciding whether your machine learning models are effective. After all, you can’t control what you can’t measure. Some of the important metrics are:
- Accuracy
- Precision vs. Recall
Accuracy
Accuracy is a metric for assessing how many predictions were done correctly. It is the number of correct predictions divided by total predictions. Let’s take a look at a real-life example of patients with tumors.
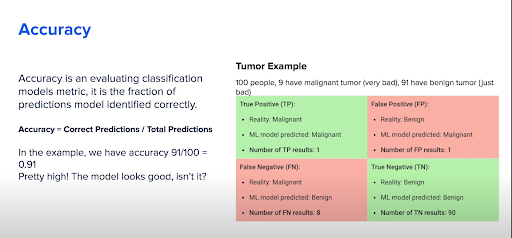
Figure 4: A tumor diagnosis example using algorithms.
In Figure 4, out of 100 sick people, we have 9 with malignant tumors and 91 with benign tumors. It is important to identify those with malignant tumors on time, because if we don’t, people may die. We identify four sections based on the type of results: false positive, false negative, true positive, and true negative (Figure 4). We can use the following equation to calculate the accuracy of this model on a scale of 0–1 with 1 representing the maximum accuracy:
TP (true positive) + TN (true negative) = 0.9 + 0.01 = 0.91
With a resulting value close to 1, we should be able to feel confident that our model is reasonably accurate, right?
Well, not really.
In Figure 4, you can see there are eight people that we falsely identified as having benign tumors when they actually have malignant tumors. We are sending home eight people who have very bad tumors, without any treatment. In the next section, we talk about precision, and why it matters for our tumor example.
Precision vs. recall
Precision, also known as a positive predictive value, only counts true positives out of all true and false positives. In our tumor example, precision is only 0.5 (Figure 5), because it didn’t identify one true positive out of two positives. We literally can have better results by throwing a coin with a 50/50 chance instead of using the algorithm.
Sensitivity, also known as recall, is the number of true positives divided by all real positives. Using the tumor example again, recall is 0.11 (Figure 5). From these metrics, we can say that the model isn’t that great. But we need to understand that, in data science, there are serious limitations with metrics that contradict each other.
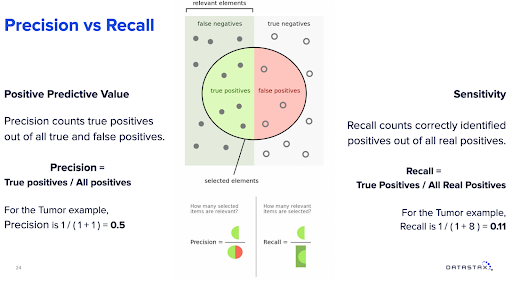
Figure 5. Machine learning — precision vs. recall.
Conclusion
This post builds upon Part 1 of our series on machine learning with Cassandra, which provides a foundational overview of Cassandra in relation to machine learning, applying it in the real world, and the process of machine learning. You can also find the codes you need to create spark connections, read DSE tables, add partitions with a primary key, and save them to DSE in our video tutorial or on GitHub.
With this post, we wanted to give you a basic understanding of how Cassandra is ideally suited for machine learning and to draw your attention to our video tutorial where you can get hands-on tutorials that illustrate the concepts we’ve presented in this series.
When you run through our video tutorial, you’ll take a deeper dive into machine learning with Cassandra with a robust set of hands-on exercises to help you:
- Learn the basics of working with Apache Cassandra and Apache Spark.
- Discover what machine learning is and its goals and approaches.
- Understand how to build effective machine learning algorithms and solutions.
- Write your very own machine learning code using Python, Cassandra, and Spark.
Explore more tutorials on our DataStax Developers YouTube channel and subscribe to our event alert to get notified about new developer workshops. Also, follow DataStax on Medium to get exclusive posts on all things data: Cassandra, streaming, Kubernetes, and more!
Resources
- Real World Machine Learning with Apache Cassandra and Apache Spark (Part 1)
- YouTube Tutorial: Machine Learning with Apache Cassandra and Apache Spark
- Distributed Database Things to Know: Cassandra Datacenter & Racks
- GitHub Tutorial: Machine Learning with Apache Spark & Cassandra
- DataStax Academy
- DataStax Certification
- DataStax Enterprise
- DataStax Luna
- Astra DB
- DataStax Community
- DataStax Labs
- KillrVideo Reference Application



