



DataStax and Decodable announced a new partnership to help application developers delight customers with instantaneous real-time features and deliver streaming data services in minutes, not months, without specialist skills.
The two companies will connect their cloud services to deliver the benefits of three powerful open source technologies: Apache Pulsar, Apache Flink, and Apache Cassandra®.
The solution offers fully-managed services available on any cloud through DataStax’s Cassandra-based Astra DB, Pulsar-based Astra Streaming, and Decodable’s SQL-based stream processing platform powered by Apache Flink™. The combination of Decodable’s open source, stream processing capabilities connected to DataStax’s open stack for real-time applications enables developer and data engineering teams to:
- Connect to legacy operational, analytic, and streaming systems in minutes using Decodable and Astra Streaming.
- Process data in SQL with Decodable and feed it to applications in real-time with Astra Streaming.
- Deliver data from DataStax’s multi-cloud Database as a Service (DBaaS), Astra DB, and advanced unified event streaming Astra Streaming service to power modern, real-time, applications and machine learning.
In this blog, we’ll dig into why real-time matters, what’s stopping adoption, and how DataStax + Decodable unlocks streaming for any organization. The blog will also highlight a real-world use-case of the DataStax + Decodable solution.
Real-time customer experiences matter
To understand the rationale behind the DataStax and Decodable partnership and the push for real-time data, let’s step back for a moment. How do you convert a standard app user to a delighted advocate that’s moved to socialize how much they love the experience?
It’s that moment when their streaming service recommends a playlist that fits the mood perfectly. It’s when a fraud notification lets the user know an incident has already been prevented - no canceled cards, no further action needed. It’s when an order gets filled earlier than planned, and they get an unexpected notification that it’s on the way!
Capitalizing on the immediacy of these key customer experience moments is made possible by real-time data and automated decisions. It’s not an overstatement to say that these moments can define industry leaders. Just consider, how would Uber or Lyft possibly operate in batch mode?
Put simply, developers make data work for their customers. They find insights to create enhanced customer experiences, gain competitive advantage, and drive intelligent features.
So why isn’t everything real-time already?
Real-time customer experiences rely on data platforms that can provide access to real-time data. Fully realizing the value of real-time data means processing continuous stream(s) of data records, not just a single event. Performing pattern matching & aggregation, joining multiple streams, and analyzing a sliding window of records provide context to individual records that feed the end experience, ML model, or analytical database.
Open source streaming data platforms that provide these capabilities have been available for some time, but deploying, configuring, and operating them requires deep skills and a significant investment of time and money. Even then, teams can lose data or real-time performance through a misunderstanding of Apache Flink checkpointing, inadequate capacity planning, or integration issues. It’s a serious undertaking and, as a result, gives streaming data a reputation that many organizations consider out of reach. So many projects ripe for real-time never see the light of day out of this fearful perception. The significant challenges perceived by many organizations in achieving continuous streaming are as follows:
- They’re not used to dealing with huge recordsets of changing data types at millisecond latencies.
- Joining multiple data sources bottlenecks select operations and impacts performance.
- Data is ingested and accessed via a complex and fragile web of connections where any format change breaks a dozen different things.
- Middleware technologies have strict integration requirements that span multiple languages, and these technologies cannot cope with the scale of real-time performance.
- Maintaining the technologies to make real-time decisions is incredibly complex, requiring specific skills, tooling, and data conforming to very specific requirements.
- The cost! Ooh, the cost of running all these technologies!
Having the right data to make the right decisions at the right time is priceless. Excuses like “it’s too complex” or “that data isn’t accessible here” are reasons for a lost customer connection. Whether it’s on the application’s time-to-value or time-to-scale or the eventual customer experience, increased time means lost revenue, lost customers, and damaged relationships.
DataStax & Decodable: making real-time simple
Decodable and DataStax free your data from traditional silos and make it consumable by applications and services, enabling them to make real-time decisions. Developers’ applications can connect to and consume data as a continuous stream.
- DataStax provides an open stack for real-time data, with Astra Streaming (based on Apache Pulsar) for data in motion and Astra DB (based on Apache Cassandra) for data at rest, available as a service on any cloud, exposing standard APIs.
- Decodable completes the stack with its stream processing and capabilities and library of connectors for a wide range of sources and sinks.
- Decodable and DataStax Astra Streaming are available as fully managed services, optimally deployed and configured, so that organizations can focus on building the applications that drive their business forward and not spend cycles on the day-to-day operations and maintenance of the data platform.
Set up continuous data streams in a few simple steps
- Use Decodable’s built-in connectors to integrate with data sources and sinks.
- Build Decodable pipelines using industry-standard SQL to ingest, enhance, and normalize data.
- Sink the data to an Apache Pulsar messaging system powered by DataStax Astra Streaming.
- If needed, persist data in Astra DB through a simple connector. Make it available to other messaging systems, database engines, analytics systems, or buckets if required.
- Consume data from Astra Streaming & Astra DB via standard APIs like Pulsar, JMS, Kafka and REST, Document, GraphQL, and gRPC.
- DataStax and Decodable make all the data and the real-time data processing easy, and it is available at your fingertips with a few clicks.
Scale on any cloud
DataStax uses serverless architectures available on any cloud (AWS, GCP, Azure) and ensures flexibility where consumers can start small and scale without limits. The serverless architectures scale with application needs automatically - needing no management. Consistent single-digit processing time ensures low latency for rapid events and data processing.
It’s your data; we take care of the rest
The fully managed services from DataStax and Decodable eliminate the operational burden related to data management while keeping full visibility and control via standard orchestration and observability tools. Data is as easy to operate as applications. What would have taken months now only takes minutes, and all the management & operations are taken care of for you, with a reduced TCO.
- Fully-managed DBaaS with Astra DB
- Fully-managed Streaming-aaS with Astra Streaming
- Fully managed SaaS to build and deploy real-time data pipelines with Decodable
Click streams with DataStax and Decodable - A real-world example
Telemetry data is all the rage today. It’s driving feedback loops and data-driven decision-making and is a core piece of product-led growth. The data is usually transmitted in the background of a website or mobile app when the user takes action. The action could be a simple click or something more meaningful like adding an item to their shopping cart.
This type of click data is typically very minimal. As a background task, it should be invisible to the user’s experience. So the data can’t carry much context to keep response time very low. It’s just simply a collection of key/value pairs. The client (in the web browser) is gathering this minimal click data without much validation or knowledge of what’s happening.
Once all this data is available in a processing pipeline, it needs to be normalized. An example of normalization would be taking the browser’s `user agent` click data and breaking the interesting pieces out - like the operating system, browser type, and browser version.
The following flow is an example of all this processing in action:
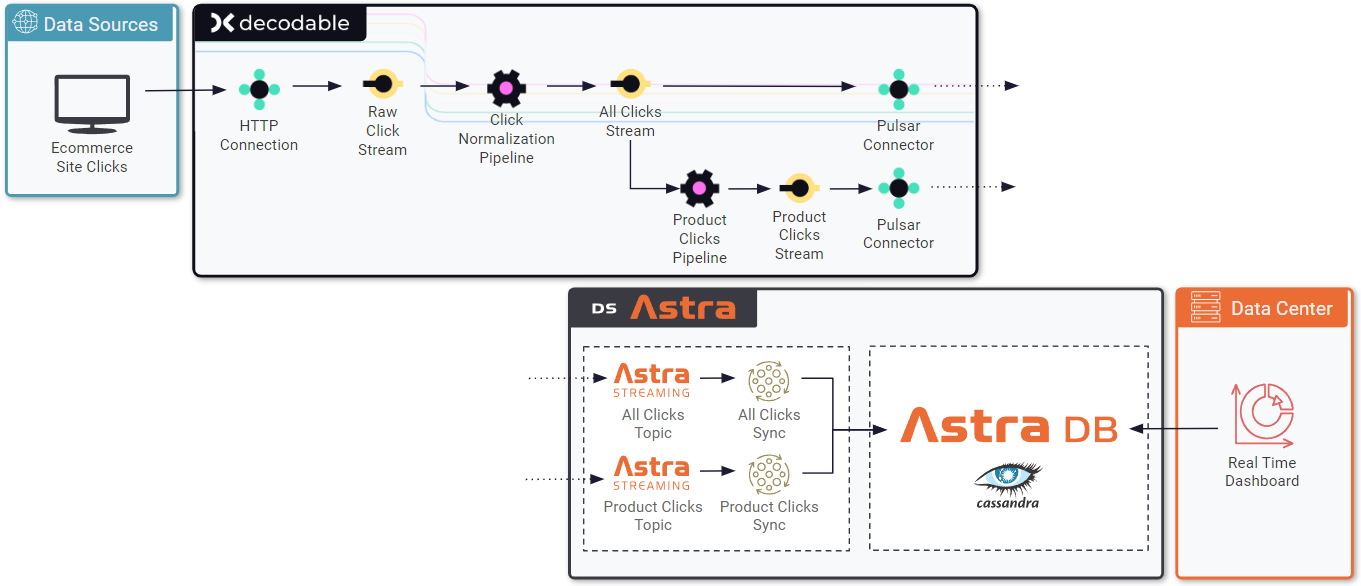
Using Decodable’s HTTP connector, the click data can be posted in the web browser to the generated connector endpoint. From there, everything about the connection and its payload are managed on the server side. Decodable processing pipelines do all this work at almost no cost to latency. How? All processing is SQL based and in-memory.
From the connector, the data feeds into a processing pipeline. The pipeline parses the click data into something structured (and useful). Then the normalized data is sent to an Astra Streaming topic and forwarded to another pipeline that filters for only “product clicks.” That filtered click data forwards to a second Astra Streaming Pulsar topic.
Once the data is available on a topic within Astra, there is the option to persist to a Cassandra table in Astra DB. There’s no code required to do this, just add a “sink” connector and point it to an existing table. A development team could also use a Pulsar client to subscribe to the topic and receive the click data as it arrives. It’s at this point that the application context kicks in. The identifier in the click data can look up further information and decide how to provide a better experience.
The combination of pipeline processing in Decodable and messaging topics in Astra Streaming are the core of real-time data. They create a new world of possibilities. The consumers (your applications) use a Pulsar client to subscribe to the topic and receive data as it arrives. Astra Streaming takes care of the schema, message semantics, and availability. Decodable provides the ingest, normalization, and processing pipelines with ease.
Get started today
To learn more about the above example, watch the on-demand recording of a live session discussing the solution specifics. Create a free account with both DataStax Astra and Decodable. It’s quite easy to create a connection between the two, and with that, you can begin creating meaningful business solutions.
The combination of DataStax and Decodable could be the catalyst to the next level of your business. Try the example and discover what possibilities lie ahead!
Real-time customer experiences matter
So why isn't everything real-time already?
DataStax & Decodable: making real-time simple
Set up continuous data streams in a few simple steps
Scale on any cloud
It's your data; we take care of the rest
Click streams with DataStax and Decodable - A real-world example
Get started today
More Company
View All
Shaping the Wild in Las Vegas: An AWS re:Invent Recap

Announcing 12 Days of Codemas: The DataStax Holiday Giveaway!

London Called. RAG++, The AI Event, Answered!
