

Proper error handling with databases is always a challenge when the safety of your data is involved. Cassandra is no exception to this rule. Thanks to the complete control of consistency, availability and durability offered by Cassandra, error handling turns out to be very flexible and, if done right, will allow you to extend the continuous availability of your cluster even further. But in order to reach this goal, it's important to understand the various kind of errors that can be thrown by the drivers and how to handle them properly.
To remain practical, this article will refer directly to the DataStax Java Driver exceptions and API, but all the concepts explained here can be transposed directly to other DataStax Drivers.
Error handling in a distributed system
A typical query in Cassandra can imply message exchanges across more than two machines. This leads to additional error causes compared to a classic client server exchange. Consider the request in the following diagram:
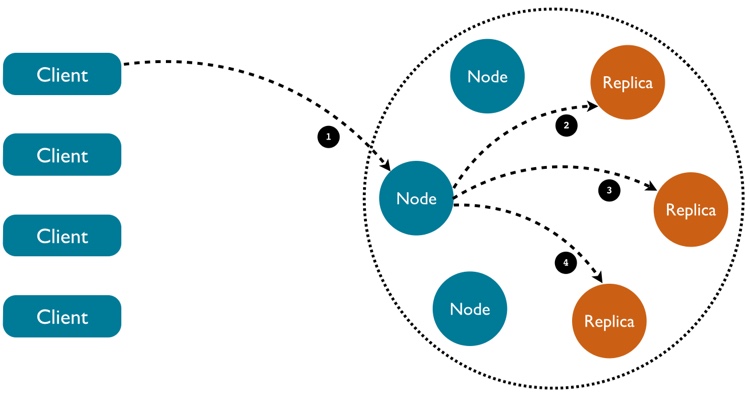
In this very typical example of Cassandra request, 4 request-response round trips are performed to complete a query. Errors can happen for any of these steps and the driver provides specific errors to deal with each possible situation:
NoHostAvailableException
In the situation where the driver is not able to establish a connection to any Cassandra node, either at startup or at a later point in time, the driver will throw a NoHostAvailableException.
UnavailableException
When a request reaches the coordinator and there is not enough replica alive to achieve the requested consistency level, the driver will throw an UnavailableException. If you look carefully at this exception, you'll notice that it's possible to get the amount of replicas that were known to be alive when the error was triggered, as well as the amount of replicas that where required by the requested consistency level.
ReadTimeoutException
Sometimes the coordinator believes that there's enough replicas alive to process a query with the requested consistency level, but for some reasons one or several nodes are too slow to answer within the predefined timeout. This could be due to a temporary overloading of these nodes or even that they've just failed or have been turned off. If the query is a read, a ReadTimeoutException will be thrown. During reads, Cassandra doesn't request data from every replica to minimize internal network traffic. Instead, some replica are only asked for a checksum of the data. A read timeout may occurred even if enough replica have responded to fulfill the consistency level if only checksum responses have been received. In Java, wasDataRetrieved() allows you to check whether you're in this situation or not. Note that by default, the driver will automatically retry the query if only checksum responses have been received, making this cause of read timeout not so likely to reach your code.
WriteTimeoutException
In a similar situation as above, if the query is a write, then a WriteTimeoutException will be thrown. If the driver differentiates between read and write timeout here, this is because a read is obviously a non mutating operation, whereas a write is likely to be. If a write timeouts at the coordinator level, there is no way to know whether the mutation has been applied or not on the non-answering replica. As we'll see next, the way this error will be handled will thus depends on whether the write operation was idempotent (which is the case of most statements in CQL) or not (for counter updates, and append/prepend updates on lists).
QueryValidationException
As with any database, when something's wrong in the way a query string has been written, the driver will throw an exception. In the case of the Java Driver, that will be a QueryValidationException.
When you can't do much
If the driver throw a QueryValidationException, you obviously can't do anything but fixing your code or checking the compatibility of your query with the Cassandra version you are using here.
In the previous section we've seen how a NoHostAvailableException was raised when the driver isn't able to connect to any node. This is caused by your Cassandra cluster being down or any network connectivity issue between the client and the cluster. When it happens in production it typically means that a manual operation will be required to re-establish the communication between the client and the Cassandra cluster, while ensuring that it's correctly up and running. The driver will automatically reconnect to the Cassandra nodes with regular retries (that you can configure when starting the driver with withReconnectionPolicy()).
Non-idempotent operations
Most operations are idempotent in Cassandra, but a few aren't: counter updates, append/prepend on list, both because they represent a delta and not an absolute value. When the driver throw a WriteTimeoutException while executing one of these operations, there is no way to know whether the delta has been applied or not. And because the update isn't idempotent retries could cause duplicates.
As a consequence it's a good idea to avoid using these operations to update critical data. For instance CAS should be preferred to counters to update stock quantities in an eCommerce environment, while set should be preferred to list when storing a list of tags. Thus counters are more appropriate for analytics use cases where a slight error margin is acceptable, while list's append/prepend should be used when duplicates can be accepted, otherwise a complete replacement of the list is a safer way to update it.
Additionally, using CQL functions to generate random values such as UUIDs, will make a write query non idempotent: uuid(), for instance, will be evaluated on the server side, and evaluated again if the client makes another try, which will lead to a different value. Therefore, generating UUIDs within your application is generally a better idea. Random value generating functions like uuid() are actually more appropriate in interactive environments such as cqlsh or DataStax DevCenter.
CAS operations
CAS (Compare-And-Set) operations, also called Lightweight Transactions, have been introduced in Cassandra 2.0. They rely on the Paxos protocol to achieve a distributed consensus. These operations have a paxos phase and a commit phase. The consistency level of the former is set on a Statement with setSerialConsistencyLevel() while the consistency level of the latter is defined with the usual setConsistencyLevel() method.
If the paxos phase fails, the driver will throw a WriteTimeoutException with a WriteType.CAS as retrieved with WriteTimeoutException#getWriteType(). In this situation you can't know if the CAS operation has been applied so you need to retry it in order to fallback on a stable state. Because lightweight transactions are much more expensive that regular updates, the driver doesn't automatically retry it for you. The paxos phase can also lead to an UnavailableException if not enough replicas are available. In this situation, retries won't help as only SERIAL and LOCAL_SERIAL consistencies are available.
The commit phase is then similar to regular Cassandra writes in the sense that it will throw an UnavailableException or a WriteTimeoutException if the amount of required replicas or acknowledges isn't met. In this situation rather than retrying the entire CAS operation, you can simply ignore this error if you make sure to use setConsistencyLevel(ConsistencyLevel.SERIAL) on the subsequent read statements on the column that was touched by this transaction, as it will force Cassandra to commit any remaining uncommitted Paxos state before proceeding with the read. That being said, it probably won't be easy to organize an application to use SERIAL reads after a CAS write failure, so you may prefer another alternative such as an entire retry of the CAS operation.
Batch queries
Cassandra 1.2 introduced atomic batches, which rely on a batch log to guarantee that all the mutations in the batch will eventually be applied. This atomicity is useful as it allows developers to execute several writes on different partitions without having to worry on which part will be applied and which won't: either all or none of the mutations will be eventually written.
If a timeout occurs when a batch is executed, the developer has different options depending on the type of write that timed out (see WriteTimeoutException#getWriteType()):
BATCH_LOG: a timeout occurred while the coordinator was waiting for the batch log replicas to acknowledge the log. Thus the batch may or may not be applied. By default, the driver will retry the batch query once, when it's notified that such a timeout occurred. So if you receive this error, you may want to retry again, but that's already a bad smell that the coordinator has been unlucky at picking replicas twice.BATCH: a timeout occurred while reaching replicas for one of the changes in an atomic batch, after an entry has been successfully written to the batch log. Cassandra will thus ensure that this batch will get eventually written to the appropriate replicas and the developer doesn't have to do anything. Note however that this error still means that all the columns haven't all been updated yet. So if the immediate consistency of these writes is required in the business logic to be executed, you probably want to consider an alternate end, or a warning message to the end user.UNLOGGED_BATCH: the coordinator met a timeout while reaching the replicas for a write query being part of an unlogged batch. This batch isn't guaranteed to be atomic as no batch log entry is written, thus the parts of the batch that will or will not be applied are unknown. A retry of the entire batch will be required to fall back on a known state.
When to retry
Retries can be used in Cassandra thanks to the fact that most queries are idempotent. If the driver sends a write query again with the same the same timestamp, it won't overwrite another update that may have arrived in between, as the last timestamp will always win.
While retries can be expensive in some situation and should be considered with care, it's still a useful error handling strategy in many cases. In general, retries can be useful when receiving a timeout exception or an UnavailableException stating that the amount of received acknowledges or available replicas is greater or equal than one and that you're willing to downgrade the consistency level of a query, and to loose the consistency guarantee that came with it.
DataStax Drivers come with a way to automatically handle retries in your application: RetryPolicy. This simple interface lets you implement the logic that you want to apply to any given statement (note that you can set a particular RetryPolicy to a statement). When handling retries with this interface, timestamps will be set properly to ensure that queries are idempotent.
By default, the driver uses an implementation of this interface, the DefaultRetryPolicy, that only performs retries in two cases that we consider safe and almost always efficient:
- On a read timeout, if enough replica replied but data was not retrieved.
- On a write timeout, if a timeout occurs while writing the distributed log used by batch statements.
A RetryPolicy is provided to handle consistency level downgrading in a straightforward way: DowngradingConsistencyRetryPolicy. This policy will retry failed queries with the best consistency level that is likely to work considering the received acknowledges or available replicas. Note that if you use this policy, the retry will be handled transparently with a lowered consistency so the developer must check the consistency level that was achieved to probably display a warning to the user or any other such kind of downgrading experience strategy. You may also want to consider the LoggingRetryPolicy to automatically log the retry. Finally, note that if you find yourself using a downgraded consistency level and feeling OK with it, then you should probably wonder whether the original consistency level wasn't too excessive for your actual requirement.
To conclude this article, let's summarize these few takeaway advices:
- Understand the difference between
NoHostAvailableException,UnavailableException,Read/WriteTimeoutException. - Write timeout of non-idempotent operations can lead to unknown states, don't use these operation for critical data.
- Consider using a consistency level
SERIALfor reads on a column updated by a CAS operation, if the extra cost on reads is acceptable, to cope with commit phase errors in a simple way. - Atomic batches come with a very handy guarantee that updates will eventually be applied, be sure not to reinvent this mechanism yourself on the client side.
- Use retries with care, in a sparse manner.
Leaders like Barracuda and Temporal manage Apache Cassandra® with Astra DB. You can too.
Create a ClusterError handling in a distributed system
When you can't do much
Non-idempotent operations
CAS operations
Batch queries
When to retry
More Technology
View All

Simplifying Ground Truth Generation for LLMs

