

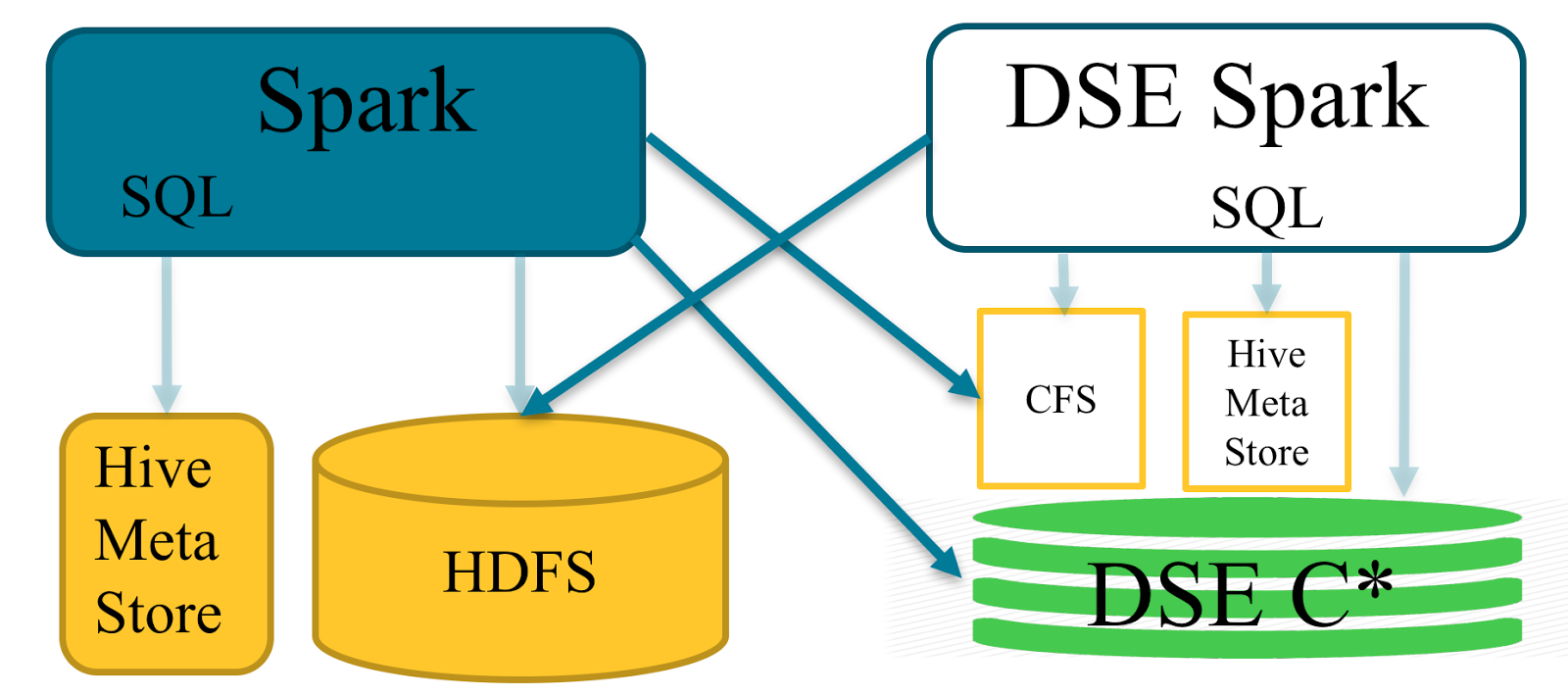
Bring Your Own Spark (BYOS) is a feature of DSE Analytics designed to connect from external Apache Spark™ systems to DataStax Enterprise with minimal configuration efforts. In this post we introduce how to configure BYOS and show some common use cases.
BYOS extends the DataStax Spark Cassandra Connector with DSE security features such as Kerberos and SSL authentication. It also includes drivers to access the DSE Cassandra File System (CFS) and DSE File System (DSEFS) in 5.1.
There are three parts of the deployment:
- <dse_home>clients/dse-byos_2.10-5.0.6.jar is a fat jar. It includes everything you need to connect the DSE cluster: Spark Cassandra Connector with dependencies, DSE security connection implementation, and CFS driver.
- 'dse client-tool configuration byos-export' tool help to configure external Spark cluster to connect to the DSE
- 'dse client-tool spark sql-schema' tool generates SparkSQL-compatible scripts to create external tables for all or part of DSE tables in SparkSQL metastore.
HDP 2.3+ and CDH 5.3+ are the only Hadoop distributions which support Java 8 officially and which have been tested with BYOS in DSE 5.0 and 5.1.
Quick Start Guide
Pre-requisites:
There is installed and configured a Hadoop or standalone Spark system and you have access to at least one host on the cluster with a preconfigured Spark client. Let’s call it spark-host. The Spark installation should be pointed to by $SPARK_HOME.
There is installed and configured a DSE cluster and you have access to it. Let’s call it dse-host. I will assume you have a cassandra_keyspace.exampletable C* table created on it.The DSE is located at $DSE_HOME.
DSE supports Java 8 only. Make sure your Hadoop, Yarn and Spark use Java 8. See your Hadoop distro documentation on how to upgrade Java version (CDH, HDP).
Prepare the configuration file
On dse-host run:
$DSE_HOME/bin/dse client-tool configuration byos-export byos.conf
It will store DSE client connection configuration in Spark-compatible format into byos.conf.
Note: if SSL or password authentication is enabled, additional parameters needed to be stored. See dse client-tool documentation for details.
Copy the byos.conf to spark-host.
On spark-host append the ~/byos.conf file to the Spark default configuration
cat byos.conf >> $SPARK_HOME/conf/conf/spark-defaults.conf
Note: If you expect conflicts with spark-defaults.conf, the byos-export tool can merge properties itself; refer to the documentation for details.
Prepare C* to SparkSQL mapping (optional)
On dse-host run:
dse client-tool spark sql-schema -all > cassandra_maping.sql
That will create cassandra_maping.sql with spark-sql compatible create table statements.
Copy the file to spark-host.
Run Spark
Copy $DSE_HOME/dse/clients/dse-byos-5.0.0-all.jar to the spark-host
Run Spark with the jar.
$SPARK_HOME/bin/spark-shell --jars dse-byos-5.0.0-all.jar scala> import com.datastax.spark.connector._ scala> sc.cassandraTable(“cassandra_keyspace”, "exampletable" ).collect
Note: External Spark can not connect to DSE Spark master and submit jobs. Thus you can not point it to DSE Spark master.
SparkSQL
BYOS does not support the legacy Cassandra-to-Hive table mapping format. The spark data frame external table format should be used for mapping: https://github.com/datastax/spark-cassandra-connector/blob/master/doc/14_data_frames.md
DSE provides a tool to auto generate the mapping for external spark metastore: dse client-tool spark sql-schema
On the dse-host run:
dse client-tool spark sql-schema -all > cassandra_maping.sql
That will create cassandra_maping.sql with spark-sql compatible create table statements
Copy the file to spark-host
Create C* tables mapping in spark meta-store
$SPARK_HOME/bin/spark-sql--jars dse-byos-5.0.0-all.jar -f cassandra_maping.sql
Tables are now ready to use in both SparkSQL and Spark shell.
$SPARK_HOME/bin/spark-sql --jars dse-byos-5.0.0-all.jar spark-sql> select * from cassandra_keyspace.exampletable
$SPARK_HOME/bin/spark-shell —jars dse-byos-5.0.0-all.jar scala>sqlConext.sql(“select * from cassandra_keyspace.exampletable");
Access external HDFS from dse spark
DSE is built with Hadoop 2.7.1 libraries. So it is able to access any Hadoop 2.x HDFS file system.
To get access you need just proved full path to the file in Spark commands:
scala> sc.textFile("hdfs://<namenode_host>/<path to the file>")
To get a namenode host you can run the following command on the Hadoop cluster:
hdfs getconf -namenodes
If the Hadoop cluster has custom configuration or enabled kerberos security, the configuration should be copied into the DSE Hadoop config directory:
cp /etc/hadoop/conf/hdfs-site.xml $DSE_HOME/resources/hadoop2-client/conf/hdfs-site.xml
Make sure that firewall does not block the following HDFS data node and name node ports:
| NameNode metadata service | 8020/9000 |
| DataNode | 50010,50020 |
Security configuration
SSL
Start with truststore generation with DSE nodes certificates. If client certificate authentication is enabled (require_client_auth=true), client keystore will be needed.
More info on certificate generation:
https://docs.datastax.com/en/cassandra/2.1/cassandra/security/secureSSLCertificates_t.html
Copy both file to each Spark node on the same location. The Spark '--files' parameter can be used for the coping in Yarn cluster.
Use byos-export parameters to add store locations, type and passwords into byos.conf.
dse client-tool configuration byos-export --set-truststore-path .truststore --set-truststore-password password --set-keystore-path .keystore --set-keystore-password password byos.conf
Yarn example:
spark-shell --jars byos.jar --properties-file byos.conf --files .truststore,.keystore
Kerberos

Make sure your Spark client host (where spark driver will be running) has kerberos configured and C* nodes DNS entries are configured properly. See more details in the Spark Kerberos documentation.
If the Spark cluster mode deployment will be used or no Kerberos configured on the spark client host use "Token based authentication" to access Kerberized DSE cluster.
byos.conf file will contains all necessary Kerberos principal and service names exported from the DSE.
The JAAS configuration file with the following options need to be copied from DSE node or created manually on the Spark client node only and stored at $HOME/.java.login.config file.
DseClient {
com.sun.security.auth.module.Krb5LoginModule required
useTicketCache=true
renewTGT=true;
};
Note: If a custom file location is used, Spark driver property need to be set pointing to the location of the file.
--conf 'spark.driver.extraJavaOptions=-Djava.security.auth.login.config=login_config_file'
BYOS authenticated by Kerberos and request C* token for executors authentication. The token authentication should be enabled in DSE. the spark driver will automatically cancel the token on exit
Note: the CFS root should be passed to the Spark to request token with:
--conf spark.yarn.access.namenodes=cfs://dse_host/
Spark Thrift Server with Kerberos
It is possible to authenticate services with keytab. Hadoop/YARN services already preconfigured with keytab files and kerberos useк if kerberos was enabled in the hadoop. So you need to grand permissions to these users. Here is example for hive user
cqlsh> create role 'hive/hdp0.dc.datastax.com@DC.DATASTAX.COM' with LOGIN = true;
Now you can login as a hive kerberos user, merge configs and start Spark thrift server. It will be able to query DSE data:
#> kinit -kt /etc/security/keytabs/hive.service.keytab \ hive/hdp0.dc.datastax.com@DC.DATASTAX.COM #> cat /etc/spark/conf/spark-thrift-sparkconf.conf byos.conf > byos-thrift.conf #> start-thriftserver.sh --properties-file byos-thrift.conf --jars dse-byos*.jar
Connect to it with beeline for testing:
#> kinit #> beeline -u 'jdbc:hive2://hdp0:10015/default;principal=hive/_HOST@DC.DATASTAX.COM'
Token based authentication
Note: This approach is less secure than Kerberos one, use it only in case kerberos is not enabled on your spark cluster.
DSE clients use hadoop like token based authentication when Kerberos is enabled in DSE server.
The Spark driver authenticates to DSE server with Kerberos credentials, requests a special token, send the token to the executors. Executors authenticates to DSE server with the token. So no kerberos libraries needed on executors node.
If the Spark driver node has no Kerberos configured or spark application should be run in cluster mode. The token could be requested during configuration file generation with --generate-token parameters.
$DSE_HOME/bin/dse client-tool configuration byos-export --generate-token byos.conf
Following property will be added to the byos.conf:
spark.hadoop.cassandra.auth.token=NwAJY2Fzc2FuZHJhCWNhc3NhbmRyYQljYXNzYW5kcmGKAVPlcaJsigFUCX4mbIQ7YU_yjEJgRUwQNIzpkl7yQ4inoxtZtLDHQBpDQVNTQU5EUkFfREVMRUdBVElPTl9UT0tFTgA
It is important to manually cancel it after task is finished to prevent re usage attack.
dse client-tool cassandra cancel-token NwAJY2Fzc2FuZHJhCWNhc3NhbmRyYQljYXNzYW5kcmGKAVPlcaJsigFUCX4mbIQ7YU_yjEJgRUwQNIzpkl7yQ4inoxtZtLDHQBpDQVNTQU5EUkFfREVMRUdBVElPTl9UT0tFTgA
Instead of Conclusion
Open Source Spark Cassandra Connector and Bring Your Own Spark feature comparison:
| Feature | OSS | DSE BYOS |
| DataStax Official Support | No | Yes |
| Spark SQL Source Tables / Cassandra DataFrames | Yes | Yes |
| CassandraDD batch and streaming | Yes | Yes |
| C* to Spark SQL table mapping generator | No | Yes |
| Spark Configuration Generator | No | Yes |
| Cassandra File System Access | No | Yes |
| SSL Encryption | Yes | Yes |
| User/password authentication | Yes | Yes |
| Kerberos authentication | No | Yes |
Leaders like Barracuda and Temporal manage Apache Cassandra® with Astra DB. You can too.
Create a ClusterQuick Start Guide
Pre-requisites:
Prepare the configuration file
Prepare C* to SparkSQL mapping (optional)
Run Spark
SparkSQL
Access external HDFS from dse spark
Security configuration
SSL
Kerberos
Spark Thrift Server with Kerberos
Token based authentication
Instead of Conclusion
More Technology
View All

Simplifying Ground Truth Generation for LLMs

