 )
)What is Cloud Native?
Cloud native explained
Cloud native is a combination of technology, methodology, and organizational approaches. It describes a type of service or application targeted for a cloud environment, as well as the characteristics, organizational principles, practices, and technology used to develop it.
Cloud-native technology is designed to take advantage of the cloud's unique ability to scale in and out and typically consists of collections of loosely coupled services running in containers. Cloud-native applications leverage cloud-computing technologies like service meshes, microservice architectures, immutable infrastructure, and declarative APIs.
However, as often happens in our industry, it’s easy to get caught up in the technology and overlook that cloud native isn't just about the tools. It's also about how organizations build, test, release, deploy, operate, and maintain these systems.
The goal is to enhance speed, flexibility, and innovation in the development cycle, while ensuring predictable iterations that deliver new digital user experiences. Cloud-native approaches are particularly valuable for large organizations that work on extensive code bases, where traditional monolithic applications often struggle.
Cloud-native app
Cloud-native applications are specifically (re)designed to fully exploit containerized deployment on distributed IaaS, PaaS, and FaaS environments, and are supported by Agile, DevOps, and CI/CD processes and methodologies.
“Cloud native is structuring teams, culture, and technology to utilize automation and architectures to manage complexity and unlock velocity.”
- Joe Beda, Co-Founder, Kubernetes and Principal Engineer, VMware
Design principles and architectural approaches like API-first design, twelve-factor (stateless) applications, and domain-driven design can be used to make microservices, modular monoliths, and even (gasp!) monoliths themselves into cloud-native applications. But it’s more than application architecture and technology like IaaS, PaaS, and SaaS. A cloud-native application relies on human practices and methodologies, as well as organizational structure.
A cloud-native maturity model
The cloud-native model includes various approaches for designing and operating applications and databases within distributed, service-oriented cloud architectures. This maturity spans three stages—cloud enabled, cloud based, and cloud native—each offering incremental benefits as systems evolve.Cloud enabled
At the cloud-enabled stage, traditional monolithic applications are slightly modified to run in virtualized environments. Changes include adapting storage for ephemeral use and bundling dependencies into a deployable form, allowing these applications to run in the cloud.
While these changes enable more efficient provisioning and better resource utilization, the systems remain largely monolithic. They rely on vertical scaling, lack automated fault tolerance, and do not fully adhere to modern design principles. Although they avoid relying on local storage, they may not support data sharding or operating in clusters. As a result, cloud-enabled applications are not guaranteed to be highly available, fault-tolerant, or self-healing, and their scalability typically remains vertical rather than horizontal.
Cloud based
Cloud-based applications extend beyond basic IaaS by embracing horizontal scaling and practices such as test-driven development, continuous integration, continuous delivery, and immutable infrastructure. DevOps practices facilitate collaboration between engineers and operations, leading to more observable and maintainable systems. Scaling usually still needs to be managed manually, but with significantly less effort than with traditional monolithic setups.
At this stage, the cloud platform often manages virtual machine availability, automatically restarting instances in case of failure. Cloud-based databases, while still monolithic in process and not fully auto-scaling, can share data and are cluster aware, typically operating on an eventually consistent model.
Cloud native
Cloud native represents the full evolution of processes, architecture, and organizational practices required to build and operate applications in a service-oriented, microservice environment. Applications are either designed or rearchitected to exploit the cloud fully as a target deployment environment. This involves adhering to the twelve-factor principles, which promote statelessness, lightweight, container-based virtualization, and continuous deployment
Key benefits at this level of cloud maturity include high availability, global scalability, and improved performance through dynamic autoscaling. . Additionally, data architectures shift toward consistent architectures, using messaging and streaming to coordinate data movement across systems.
For databases, achieving serverless DBaaS often requires breaking apart the monolithic server. Apache CassandraⓇ, for example, benefits from its inherent partition tolerance. However, transitioning to this model presents several technical challenges:
- Separating functions like coordination, reads, writes, compaction, and repair into independent processes
- Eliminating dependency on locally attached storage
- Managing latency due to process separation
- Ensuring security across disk, process, and network boundaries
- Emitting, collecting, and monitoring telemetry for billing
- Re-engineering to leverage Kubernetes-native structures (e.g., etcd) for workload orchestration, automated remediation, and leader delegation
The final piece of the cloud-native puzzle is autoscaling. Autoscaling is a complex optimization challenge that minimizes computational costs while meeting fluctuating tenant demands. It dynamically adjusts capacity—scaling up during high demand and down when demand decreases—to balance high performance with cost-effectiveness.
Monolithic systems can run in the cloud but are generally not cloud native due to internal interdependencies that lead to slow feature deployment, challenges with multiple library versions, prolonged regression testing, and limited independent deployment or scaling. Consequently, many early-stage applications are being designed as modular monoliths, which better support large codebases and multiple concurrent developers.
What qualifies an application as cloud native?
Typically, cloud-native applications follow Heroku’s 12-factor methodology for application development, which include:
- Stateless (with state managed externally)
- Lightweight virtualization (using Linux containers)
- Service oriented or microservice architecture, or cloud functions
- Strong API contracts that allow flexible reimplementation
- Deployment to elastic, software-defined infrastructure (IaaS, PaaS, FaaS)
- High availability, fault tolerance, and self-healing capabilities, at the IaaS level or beyond
- Management via Agile, DevOps, and CI/CD processes
- Dynamic configuration and service discovery at runtime
- Centralized logging, metric streaming, and tracing for observability
- Operation on immutable infrastructure that can be started, stopped, and scaled as needed
The major components of cloud-native architecture
There is ongoing debate over whether serverlessness is required for an application to be considered cloud native. At DataStax, we believe the autoscaling aspect of serverless (as opposed to solely functions-as-a-service or FaaS) is essential. However, both applications and functions can be cloud native. Below are key elements commonly found in cloud-native systems:
Microservice architecture
Cloud-native systems are built on small, loosely coupled services that promote agility and independent development. Stateless microservices support resilience, elastic scalability, and low-risk system evolution. Coordinating autoscaling between the application and data tiers helps ensure smooth autoscaling, preventing bottlenecks and resource starvation.
Programming languages and frameworks
Development teams can select technologies based on functionality rather than the specific implementation. Data access can range from low-level drivers to high-level APIs. While standardized tooling can offer efficiencies, diverse team skills are often necessary.
Serverless and Functions-as-a-Service
Business logic can be implemented as simple functions without a full operating system, easing development and scaling. Serverless frameworks and FaaS providers deliver zero- configuration, turnkey autoscaling. In general, cloud-native systems avoid singleton, non-autoscaled data repositories when autoscaling is desired
APIs
An API-first design with strong, well-documented contracts, often aligned with domain-driven design, is critical. At the data tier, standardized interfaces from microservices and third-party services promote faster development and collaboration. Common examples include schemaless JSON, REST, GraphQL, WebSockets, and gRPC.
Data
Databases, streaming, and messaging platforms enable data flow between microservices and systems of record. Eventual consistency, enabled by unified event streaming, is widely adopted. Cloud-native designs may require data transformation tools to ensure backward compatibility with old data models for auditing and compliance.
Containers
Microservices are frequently packaged and deployed as Docker images for portability and efficient resource consumption. Containers provide lightweight virtualization, packaging multiple dependencies into a single, easily deployable unit.
Orchestration
Container orchestration platforms like Kubernetes automate deployment, scaling, and resilience at scale. Open source operator collections like K8ssandra extend Kubernetes beyond stateless applications, allowing it to manage stateful components or isolate singleton pods for database processes. For example, K8ssandra packages multiple tools into a convenient Helm chart, including:
- Apache Cassandra
- Stargate, the open-source data gateway
- Cass-operator, the Kubernetes Operator for Apache Cassandra
- Reaper for Apache Cassandra, an anti-entropy repair feature (plus reaper-operator)
- Medusa for Apache Cassandra for backup and restore (plus medusa-operator)
- Metrics Collector for Apache Cassandra, with Prometheus integration, and visualization via pre-configured Grafana dashboards
Monitoring
Distributed applications require robust observability. Systems must emit the required metrics, logs, traces, and APM data needed to identify issues, diagnose slow processes, and trigger remediation. As complexity increases, automated monitoring, often leveraging machine learning, is increasingly essentially.Security
Modern security practices involve (m)TLS, OAuth, OIDC, JWTs, identity providers, API gateways, and automatic container patching. Regular updates, encryption at rest and in transit, and effective credential management are critical to protect the broader attack surface inherent in cloud-native systems.
Continuous integration, continuous delivery / deployment tooling
Frequent, automated releases replace risky, infrequent deployments. Agile practices, test-driven development, and infrastructure-as-code allow teams to iterate rapidly using CI/CD pipelines. Continuous integration merges code into a shared repository with automated builds and tests running throughout the day, while continuous delivery and deployment streamline the path to production, either with a final manual check or entirely automated.
Cassandra and Kubernetes go together like peanut butter and chocolate
What are the benefits of using cloud-native technologies?
According to the Cloud Native Computing Foundation (CNCF), “Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservice architecture, immutable infrastructure, and declarative APIs exemplify this approach.” The benefits include, “loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”
Resilient
Applications can survive hardware, network and software flaws. Container management systems, like Kubernetes, ensure the availability of applications or services inside of these lightweight virtual instances.
Manageable
Applications are easy to configure and quickly adapt to changing operating conditions and environments. Scalability is provided by the system automatically in response to changing operating conditions, or pre-defined rules.
Observable
Applications are instrumented to collect traces, metrics, logs, and APM data to provide actionable insight. Root cause analysis can be determined quickly, without an operator directly logging into a specific instance and/or making instance-specific changes.
Frequent changes
Applications are modular, allowing rapid incremental changes to individual units. The unit of work for a team is defined by a domain-driven design and the boundaries of a given microservice. Small teams can own and iterate on their implementation as long as they adhere to the API contract. Compare that to traditional monolithic design, where interdependencies in the code base make it quite difficult for teams to work independently in parallel. Making changes requires large meetings, painstaking change management processes, and/or impact analysis for any given modification.
Predictable changes
Applications and configurations are source controlled to ensure auditability and repeatability of deployments and configuration changes. Immutable infrastructure is used to ensure that development, staging, QA, test, and production environments are exactly the same. This avoids the configuration drift that is so often responsible for system outages or unexplainable behavior.
Minimal toil
Application deployment and management is automated, reducing busywork and enabling operators to manage systems holistically. Pipelines for continuous integration, continuous delivery, and continuous deployment are used to codify tribal release management knowledge into an automated and repeatable process.
Building cloud-native applications requires a mindset shift that reaches into the culture, processes, and structure of organizations. Whether you're delivering that first app for your startup or modernizing a traditional monolith, adopting cloud-native applications enables you to delight your customers with tailored, personalized experiences, while empowering them to leverage their data in ways they may not have even considered.
Take our DBaaS for a spin and launch your database in 5 minutes or less
Cloud-native applications
Given the variety of design options and data stores available, there are any number of ways to approach data. We've observed several common patterns.
“Cloud native is structuring teams, culture, and technology to utilize automation and architectures to manage complexity and unlock velocity.”- Joe Beda, Co-Founder, Kubernetes and Principal Engineer, VMware
Design principles and architectural approaches like API-first design, twelve-factor (stateless) applications, and domain-driven design can be used to make microservices, modular monoliths, and even (gasp!) monoliths themselves into cloud-native applications. But cloud native is more than application architecture and technology like Iaas, PaaS and SaaS. A cloud-native application rests on a foundation of human practices and methodologies, as well as an organizational structure.
Database management in a cloud-native environment
Given the variety of design options and data stores available, there are any number of ways to approach data. We've observed several common patterns:
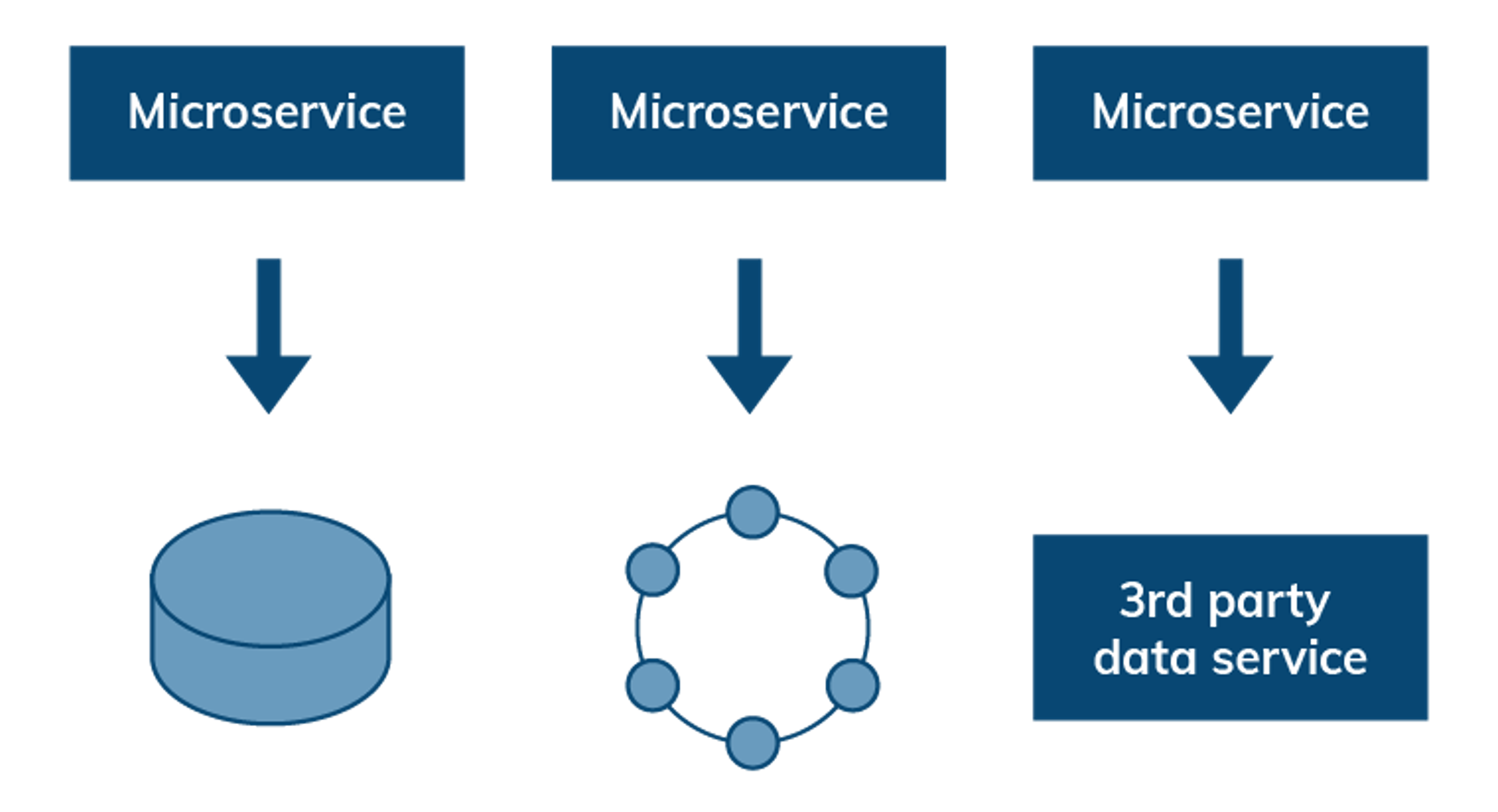
Stateless microservices with delegated data persistence
Microservices typically delegate responsibility for storing state to a persistence mechanism such as a dedicated block storage volume, a distributed database cluster, or a data service. Regardless of the store used, each service should control access to its own data. Saga patterns, compensating transactions, event-driven architecture, streaming, messaging, and eventual consistency are other concepts that become very important in wrangling distributed data. Aligning the operating model of the data tier and application tier ensures smooth scaling / autoscaling.
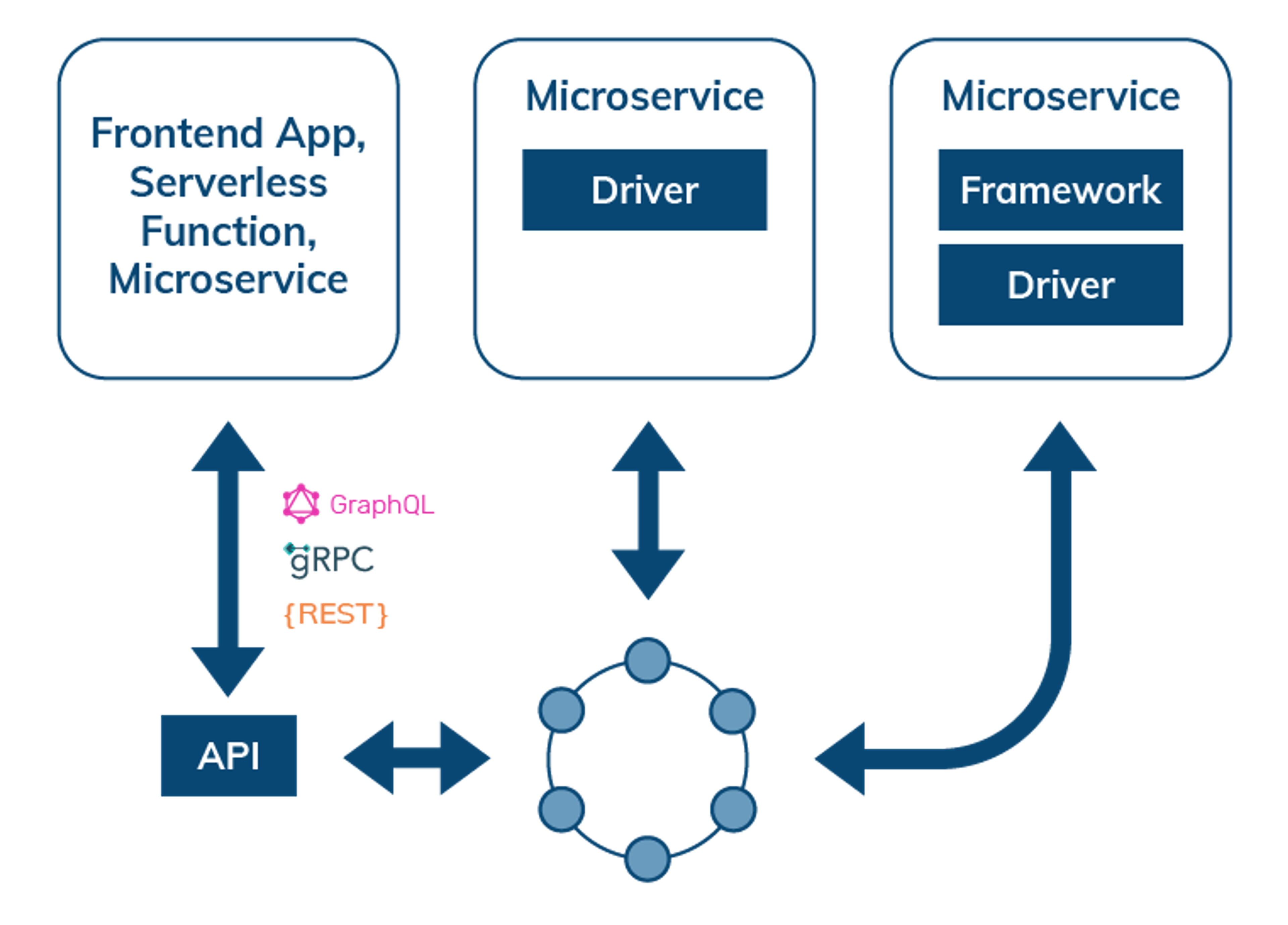
Data access through APIs, data API gateways, drivers, and frameworks
When interacting with a distributed database, such as Cassandra, the simplest way to access data is through data-service APIs described in GraphQL, REST, or gRPC. This mode of interaction is useful for frontend applications, serverless functions, or microservice architecture. Microservices that need more control over their interactions with the backend database can be coded directly using a driver, or use a language SDK and/or integration for frameworks such as Spring Boot, Quarkus, Node.js, Express.js, Django, or Flask. APIs also enable Jamstack and frontend developers using React.js, Angular, JS, Vue.js to provide persistent storage for their applications.
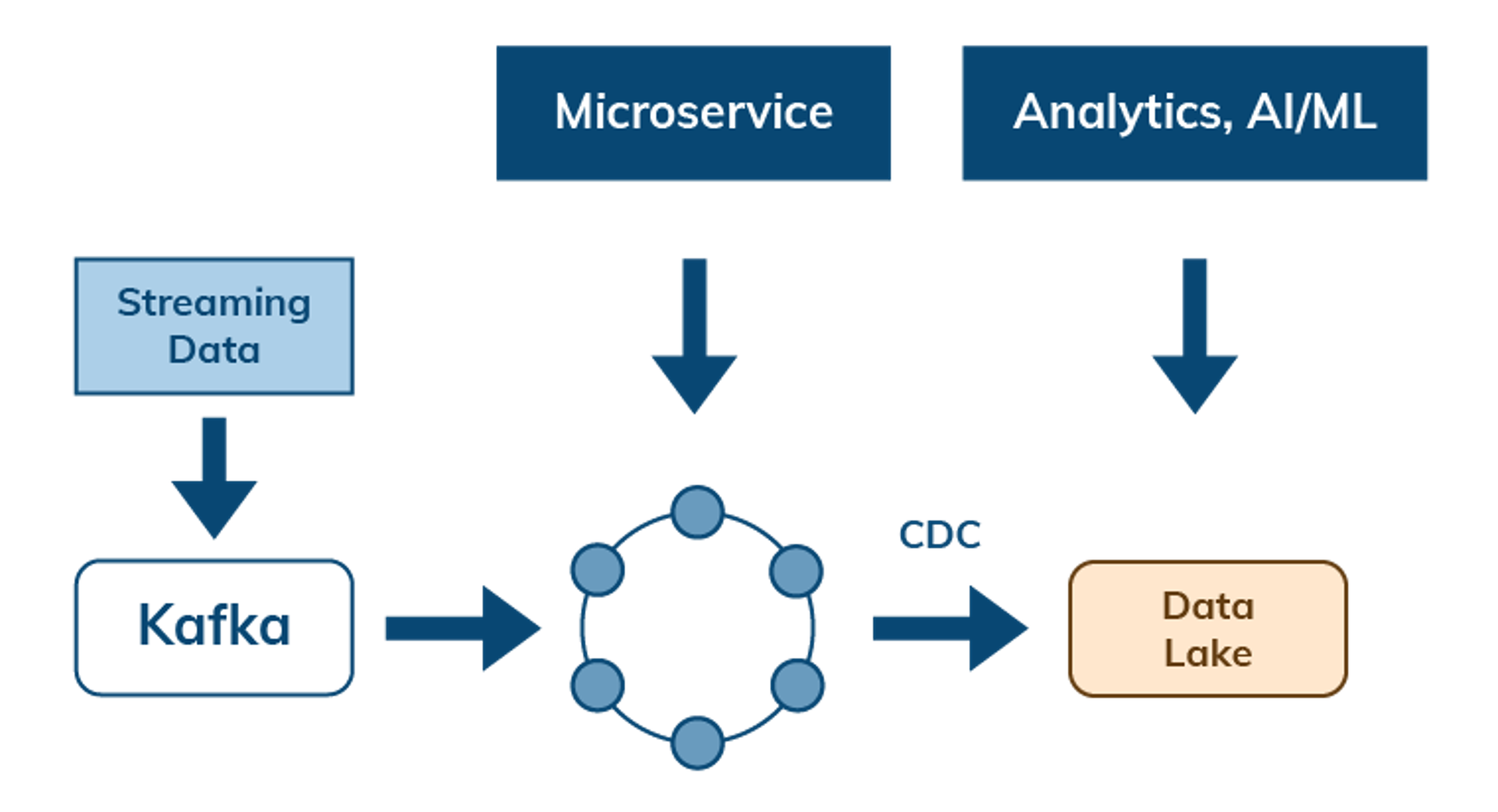
Manage data flow with streaming and change data capture
Cloud-native architectures also need to address the flow of data between services and APIs. Data can flow from streaming and messaging systems such as Apache Pulsar and Kafka into Cassandra as a system of record for access by microservices. Change data capture (CDC) enables data flows out of Cassandra to other services or to a data lake to enable further analysis.
Cloud-native examples
At DataStax, we built Astra DB with a serverless design focused on elasticity and autoscaling, which required our team to develop a suite of autoscaling policies, strategies, heuristics, and predictive models.
Today, there are plenty of businesses using cloud‑native architecture. For example, Netflix and Airbnb have both leveraged this approach to transform their operations:
- Netflix transitioned from a monolithic system to a microservices‑based, cloud‑native architecture hosted on AWS. This transformation enables them to deliver streaming video to millions of users worldwide with high scalability and resilience. In addition to dynamically provisioning compute resources, Netflix developed its own content delivery network, Open Connect, which caches content closer to viewers, thereby optimizing streaming performance and ensuring minimal latency even under massive load.
- Airbnb migrated nearly all of its infrastructure to AWS to support rapid, global scaling of its online marketplace. By adopting a cloud‑native architecture, Airbnb is able to provision resources on‑demand, optimize costs with pay‑per‑use pricing, and maintain high availability as user demand grows.
Learn how easy Cassandra in the cloud can be with DataStax Astra DB





