

Data is the lifeblood of every business and the very reason behind naming the industry's collective efforts as “information technology.” The rate of growth and the need for global deployment of data is skyrocketing. Yet the most powerful data of all is real-time data. So why are open source projects like Apache Cassandra and Apache Pulsar leading the delivery of data in real-time—at cloud scale—for today’s developers?
Developers and real-time data
You’ll see real-time applications delivering results in the applications you use everyday, everywhere: from location-based services to web apps, retail, and banking. And more is coming; 5G mobile networks and machine learning will propel both the consumption and production of real-time data. 2023 is sure to be a year where more developers embrace real-time as a primary development approach. This three-part blog series will examine what’s standing in the way of adoption of real-time data for developers, and how real-time streaming and databases like Apache Pulsar and Apache Cassandra have addressed those difficulties in 2022.
More than in-memory
Historically, developers have associated real-time data with in-memory caches or in-memory databases, and only more recently with streaming technology. With in-memory technology, indexes and data are stored in volatile memory (typically DRAM). But a select few operational DBMS are capable of real-time performance using non-volatile (durable) storage. With the right data model, modern NoSQL systems like Apache Cassandra can achieve in-memory levels of performance. When deployed correctly, solid-state disk and low-cost object storage dramatically alter storage unit economics for Cassandra. Combine in-memory performance on lower cost hardware and you’ve eliminated the need to synchronize volatile in-memory data with a companion, durable DBMS. Scratch one off the list of the two hard things for developers in computer science: cache invalidation, naming things and off-by-one errors.
While most developers would gladly be rid of caching design considerations and troubleshooting headaches, operational databases are just one of many systems employed by modern digital businesses today. That reality widens the lens for what developers need to learn in order to ensure system-wide low latency. Developers were trained for decades to the mindset of “persist user or machine input to an operational database first, and data travels further from there.” With the advent of streaming systems, it becomes a mindset of: “direct all user or machine input to a stream, sending that data in parallel to multiple downstream systems for multiple reasons”. And “multiple downstream systems” maps to a whole landscape of other systems, not just operational databases:
- Cloud functions, other streams, event sourcing repositories
- Time-series, graph, key-value, and wide-column databases
- Feature stores for machine learning
- Distributed ledgers (blockchain)
- Traditional RDBMSs
Changing that traditional “app-to-database-first” mindset to an “app-to-stream-first” mindset should then be a critical leap to make for the aspiring real-time developer. Or would it?
When developing with a real-time database and streaming designed to work together, you’d retain the flexibility of using either approach as needed or as is appropriate for the use case.
So what’s stopping projects from making the leap?
Thinking real-time first
Well, let’s consider for a moment that real-time data is quite a perspective shift for practitioners. After all, real-time systems can be limited by their slowest component(s). Keeping end-to-end system latency in mind while coding at the level of a given component is hard, requiring architect and developer collaboration at a whole new level. And this newly minted collaboration must contend with everything from “this isn’t how we’ve done it before” to helping make the business case. DataStax surveyed 500+ leaders and practitioners for The State of the Data Race 2022, who responded to the challenges of thinking real-time first, identifying a wide range of issues:
- Gaps in security, encryption, audit, compliance, and governance
- Operational complexity of real-time, especially for self-managed environments
- Lack of requisite technical skills for real-time / at-scale design patterns and architecture
- Diverse and distributed data, locked in distinct silos, formats and encodings
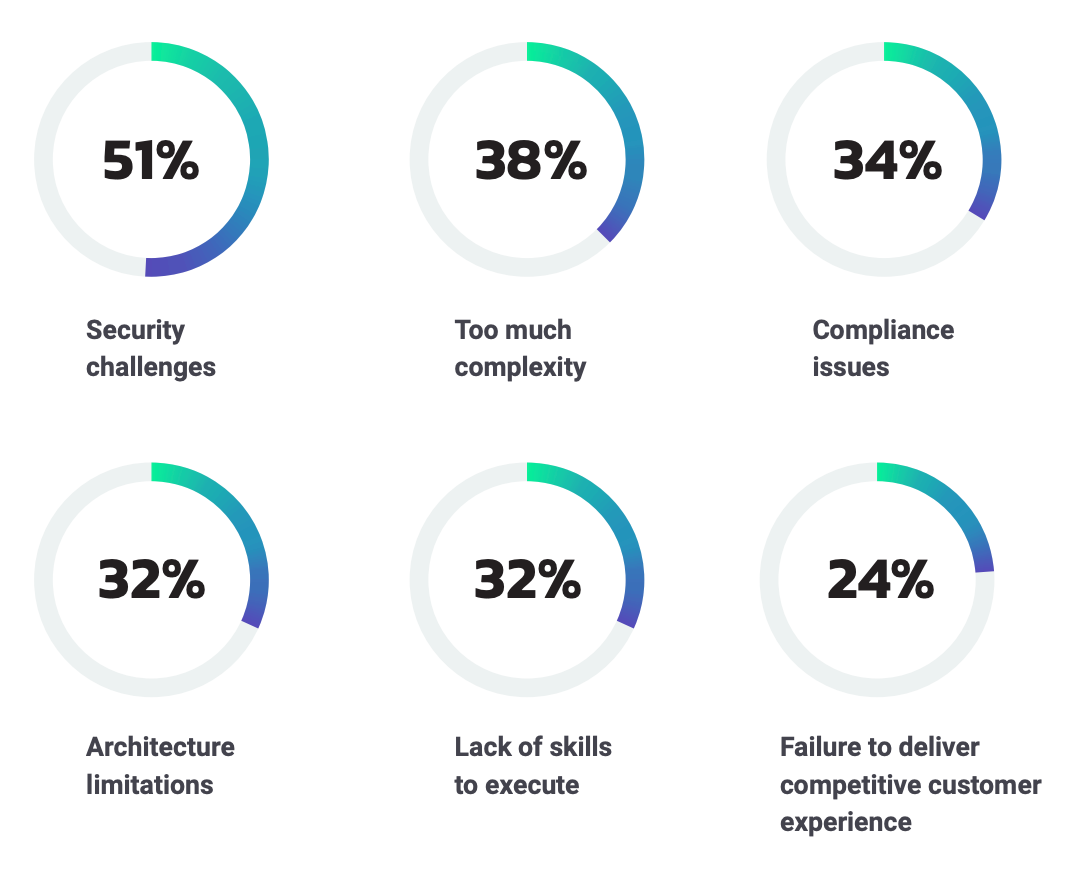
Figure 1: How respondents answered “What’s the biggest fear regarding the use of real-time data at your organization?” in a survey conducted for The State of the Data Race 2022.
For developers and architects, high-level concerns like these expand into multitude of related technical, cultural, and organizational issues. For example:
- Requirements to cooperate with legacy, phased batch processing
- Nascent or specialized tools and protocols to build, deliver and test apps in real-time
- Knowing when, why, and how to apply reactive vs. imperative programming
- Escalating data volume and big-data-level storage costs for low latency storage
- Global deployment of applications and data for edge computing
“Interestingly, the biggest fear (by a significant amount) that organizations voice regarding the use of real-time data at their organizations are challenges around security. When one isolates this response for data leaders, the concern is even more significant: 51% of all organizations point to this as a significant fear, while the percentage is 61% for data leaders.” —The State of the Data Race 2022
Since those leaders have already surmounted a lot of the get-to-production hurdles, they are focused on longer horizon concerns like security posture. Also, real-time data and apps are frequently used for systems of engagement where the stakes are higher and core to the business. Still, the benefits of real-time are accessible to only a select few organizations. Those capable of walking away from traditional tech stacks, and dedicating the resources to delivering and supporting the complex systems needed are the ones reaping the rewards.
You see them in the leading digital services you use every day: streaming, gaming, social networks, e-commerce, and many others are built on open source like Apache Cassandra, Stargate, and Apache Pulsar. Startups and Fortune 100 companies around the globe have chosen to partner with DataStax to accelerate the data that runs and transforms their business. So, Cassandra, Stargate, and Pulsar must have done some pretty amazing things to make real-time data more accessible in 2022.
In the next two blog posts of this series, we’ll talk about what they are and set the stage for the breakout year to come while doing it.
Follow the DataStax Tech Blog for more developer stories. Check out our YouTube channel for tutorials DataStax Developers on Twitter for the latest news about our developer community.







